

“欧洲版 OpenAI” Mistral 的代码模型CodeStral,又上新了!
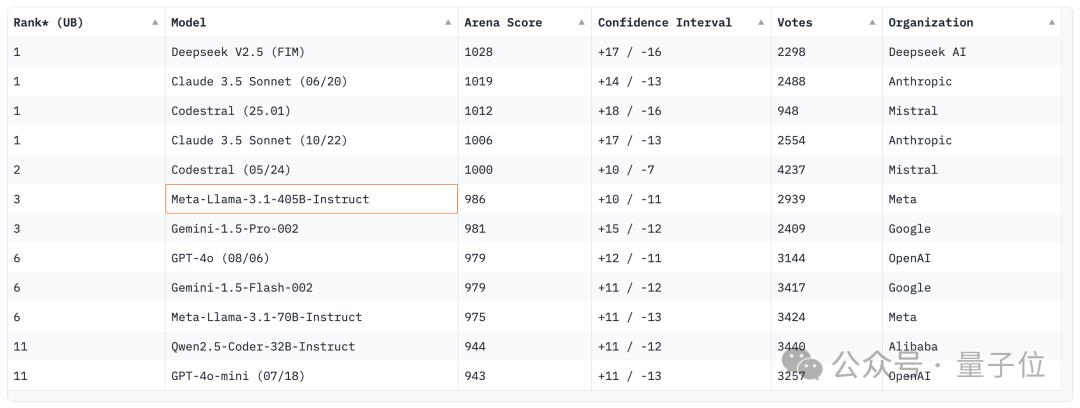
而且与 DeepSeek V2.5 和 Claude 3.5 平起平坐,共同位列 Copilot 竞技场第一名。
上下文窗口也增长到了之前的 8 倍,达到了 256k。

据介绍,新版 Codestral(2501)使用了更高效的架构和分词器,生成速度比前一代大约快了 2 倍。
在多个 Benchmark 当中,2501 版本都取得了 SOTA 的成绩,代码补全(FIM)能力也可圈可点。
Mistral 的合作方 Continue.dev 联创 Ty Dunn 还表示,Codestral 2501 标志着FIM领域的重大进步。
登顶代码模型竞技场,多种编程语言均是SOTA
在代码模型竞技场 Copilot Arena 上,CodeStral 2501 取得了第一名,与 Deepseek V2.5 以及 Claude 3.5 Sonnet 并列。
之后是 CodeStral 的上一个版本(2405),新版得分相比这一版提高了 12 分(1.2%)。
Llama 3.1、Gemini 1.5 Pro 和 GPT-4o 的排名则还要再靠后。
不过榜单当中没有 o1,如果加进来对话可能形势还会有所改变。
Copilot Arena 由卡内基梅隆大学和 UC 伯克利的研究人员与 LMArena 合作于去年 11 月推出。
它和我们更熟悉的 LLM 竞技场很类似,由用户出题并让系统随机选择两个模型匿名输出,然后用户根据输出选择优胜方。
Copilot Arena 可以看做是LLM 竞技场的代码专用版本,不过同时它也是一款开源编程工具,可以在 VSCode 中同时让多个模型同时生成,方便用户“货比三家”。
目前已经有 12 个代码模型在 Copliot Arena 中进行过 PK,总共进行了 1.7 万余场battle。
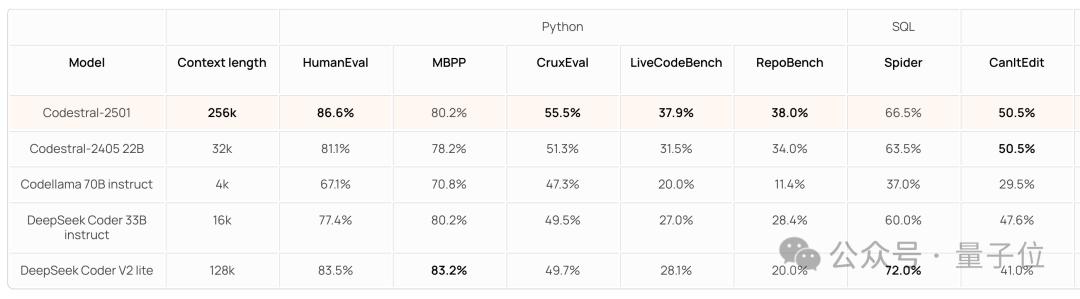
而根据 Mistral 官方晒出的成绩单,CodeStral 2501 在 HumanEval 等传统测试当中的多个指标上,也取得了 SOTA 的成绩。
(按照 Mistral 的说法,选择参与对比的模型是参数量 100B 以下且在 FIM 任务当中普遍被认为表现较好的模型。)
并且窗口长度也从 2405(参数量 22B)的 32k 增长到了 256k。
在 Python 语言和 SQL 数据库的测试中,CodeStral 2501 在多个测试指标上都位列第一,其余位列第二。
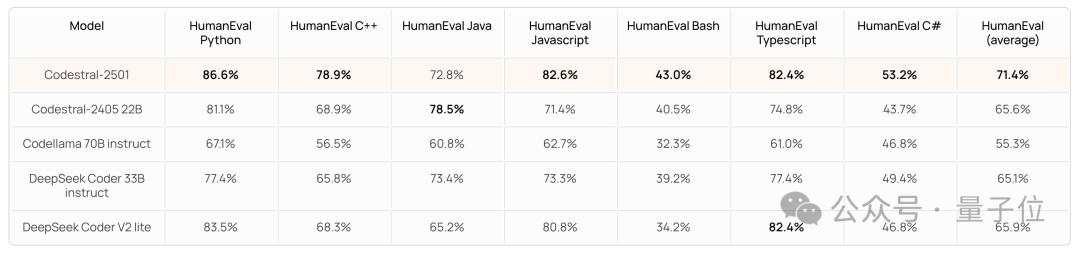
其他语言方面(据宣传 CodeStral 共支持 80+ 种语言),CodeStral 的 HumanEval 平均分为 71.4%,比第二名高出近 6 个百分点。
具体来看,在 Python、C+、JS 等多种常用语言中也都是 SOTA,并且实现了 C# 语言得分过半。
不过有意思的是,在 Java 上 CodeStral 2501 的成绩相比前一代出现了下降。
除了生成,Mistral 团队也发布了 CodeStral 2501 的 FIM 表现(单行精确匹配)。
结果平均成绩以及 Python、Java 和 JS 三个单项相比前一代均进步明显,且优于 OpenAI FIM API(最新版是3.5 Turbo)等其他模型(不过紧随其后的 DeepSeek 咬得很紧)。
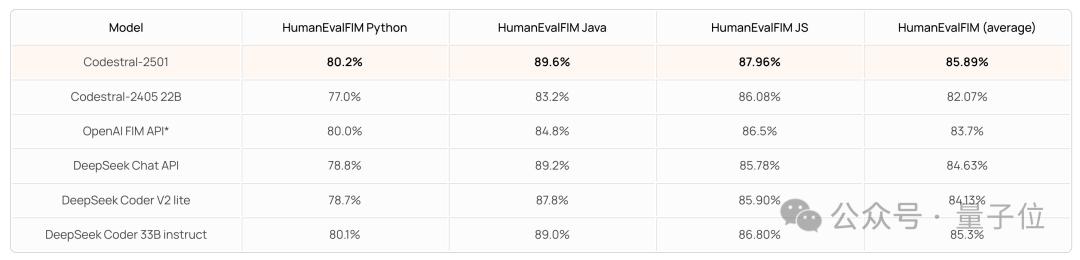
在 FIM 的 pass@1 当中,表现也是类似:

目前,CodeStral 2501 可以通过 Mistral 的合作方 Continue,在 VSCode 或 Jetbrains 系列 IDE 中使用。
当然动手能力强的用户,也可以通过 API 自己来部署,价格是 0.3/0.9 美元或欧元每百万输入/输出 token。
参考链接:
[1]https://x.com/lmarena_ai/status/1878872916596806069
[2]https://mistral.ai/news/codestral-2501/


