

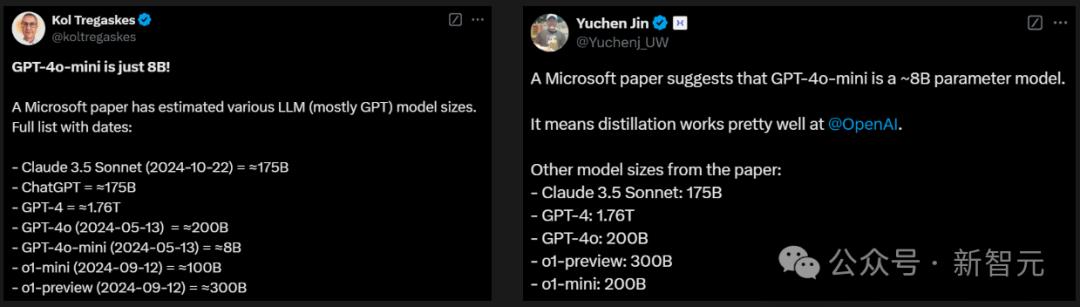
穿越重重迷雾,OpenAI模型参数终被揭开!一份来自微软华盛顿大学医疗论文,意外曝光了GPT-4、GPT-4o、o1系列模型参数。让所有人震惊不已的是,GPT-4o mini仅8B。
谁能想到,微软在一篇医学领域的论文里,竟然把OpenAI模型的参数全「曝光」了!
- GPT-4参数约1.76万亿
- GPT-4o参数约2000亿
- GPT-4o mini参数约80亿
- o1-preview参数约3000亿
- o1-mini参数约1000亿
- Claude 3.5 Sonnet参数约1750亿

研究人员:参数均为估算值
让所有人难以置信的是,GPT-4o系列的参数如此少,mini版甚至只有8B。
有网友猜测,4o mini是一个大约有40B参数的MoE模型,其中激活参数为8B。
因为,他发现4o mini明显比8B模型学到了更多的知识,同时间运行速度很快。
此外,由于GPT-4o是MoE架构,所以OpenAI可能在mini版本上使用了相同的架构。

另有网友惊讶地表示,Claude 3.5 Sonnet参数竟等同于GPT-3 davinci。

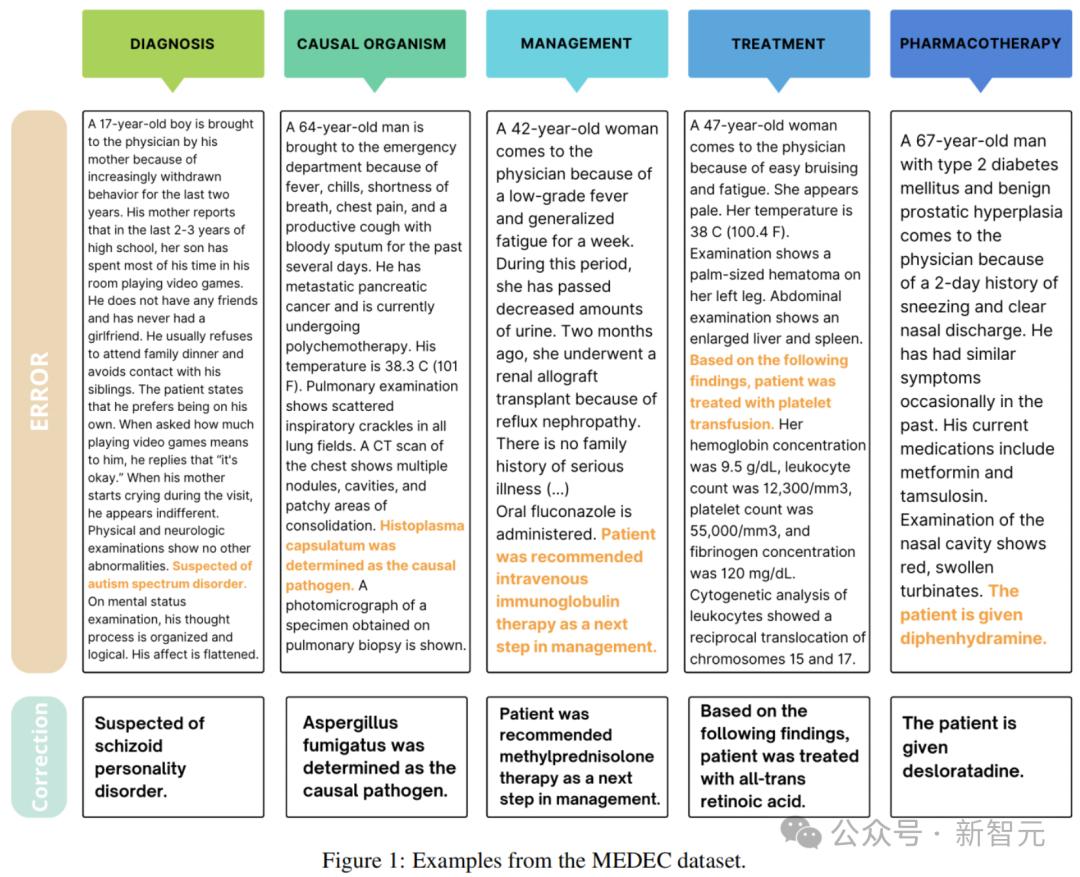
这篇来自微软、华盛顿大学团队的论文中,发布了一个具有里程碑意义的评估基准——MEDEC1,专为临床笔记医疗错误检测和纠正而设计。

论文地址:https://arxiv.org/abs/2412.19260
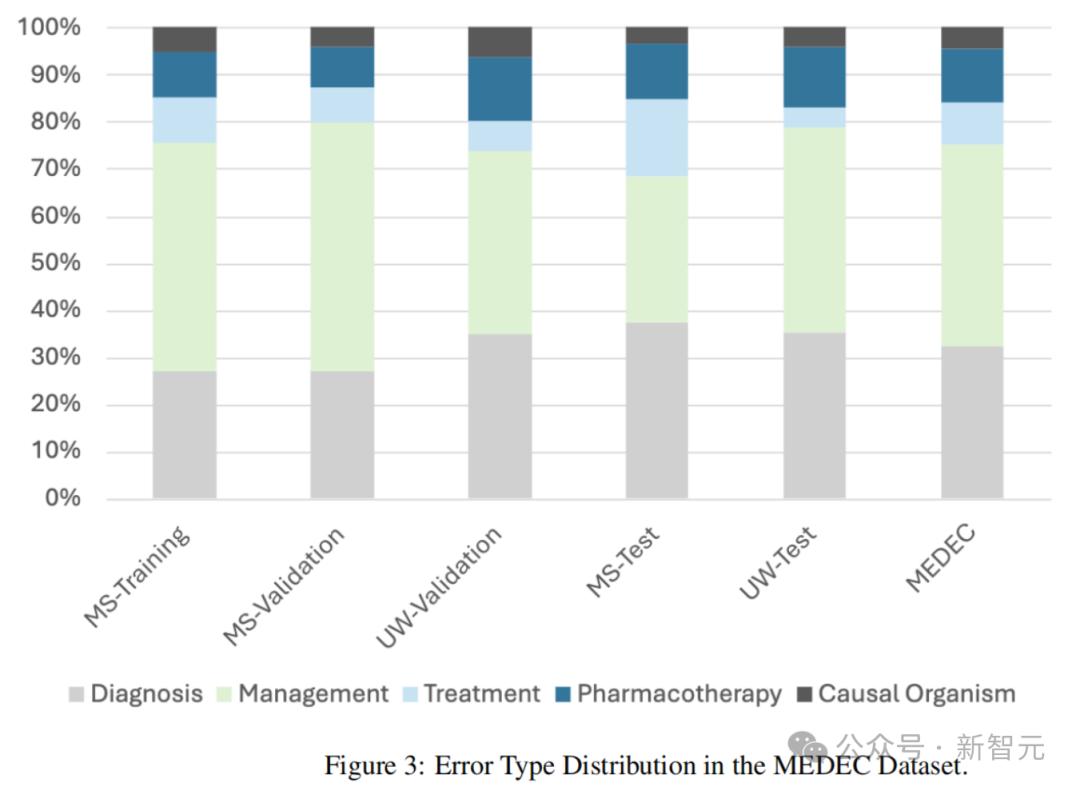
这项基准涵盖了五种类型的错误,包括诊断、管理、治疗、药物治疗和致病因子。
MEDEC的数据来源,收集了来自3家美国医院系统的488篇临床笔记,总计3,848篇临床文本。
值得一提的是,这些数据此前从未被任何LLM接触过,能够确保评估真实性可靠性。目前,该数据集已被用于MEDIQA-CORR共享任务,以评估17个参与系统的表现。
得到数据集MEDEC后,研究团队对当前最先进的模型,包括o1-preview、GPT-4、Claude 3.5 Sonnet、Gemini 2.0 Flash等,在医疗错误检测和纠正任务中进行了全面测试。
同时,他们也邀请了两位专业医生进行相同的错误检测任务,最终将AI与人类医生结果进行PK。
结果发现,最新LLM在医疗错误检测和纠正方面表现不俗,但与人类医生相比,AI还是有着明显的差距。
这也从侧面印证了,MEDEC是一个具有充分挑战性的评估基准。
论文讲了什么?
来自美国医疗机构的一项调查研究显示,每5位阅读临床笔记的患者中,就有一位报告发现了错误。
其中40%的患者认为这些错误是严重的,最常见的错误类别与当前或过去的诊断相关。
与此同时,如今越来越多的医学文档任务(比如,临床笔记生成)均是由LLM去完成。
然而,将LLM用于医学文档任务的主要挑战之一,容易产生「幻觉」,输出一些虚构内容或错误信息,直接影响了临床决策。
毕竟,医疗无小事,一字之差可能关乎生死。
为了降低这些风险,并确保LLM在医学内容生成中的安全性,严格的验证方法至关重要。这种验证需要相关的基准来评估是否可以通过验证模型实现完全自动化。
在验证过程中,一个关键任务是,检测和纠正临床文本中的医学错误。
站在人类医生的角度来考虑,识别和纠正这些错误不仅需要医学专业知识和领域背景,有时还需要具备丰富的经验。
而此前,大多数关于(常识性)错误检测的研究都集中在通用领域。
为此,微软华盛顿大学团队引入了全新数据集——MEDEC,并对不同的领先的LLM(比如,Claude 3.5 Sonnet、o1-preview和Gemini 2.0 Flash)进行了实验。
作者称,「据我们所知,这是首个公开可用的临床笔记中自动错误检测和纠正的基准和研究」。
MEDEC数据集
MEDEC数据集一共包含了3,848篇来自不同医学专业领域的临床文本的新数据集,标注任务由8位医学标注员完成。
如前所述,该数据集涵盖了五种类型的错误,具体包括:
- 诊断(Diagnosis):提供的诊断不准确
- 管理(Management):提供的管理下一步措施不准确
- 药物治疗(Pharmacotherapy):推荐的药物治疗不准确
- 治疗(Treatment):推荐的治疗方案不准确
- 致病因子(Causal Organism):指出的致病生物或致病病原体不准确
(注:这些错误类型是在分析医学委员会考试中最常见的问题类型后选定的。)
上图1展示了,MEDEC数据集中的示例。每篇临床文本要么是正确的,要么包含一个通过以下两种方法之一创建的错误:方法#1(MS)和方法#2(UW)。
数据创建方法#1(MS)
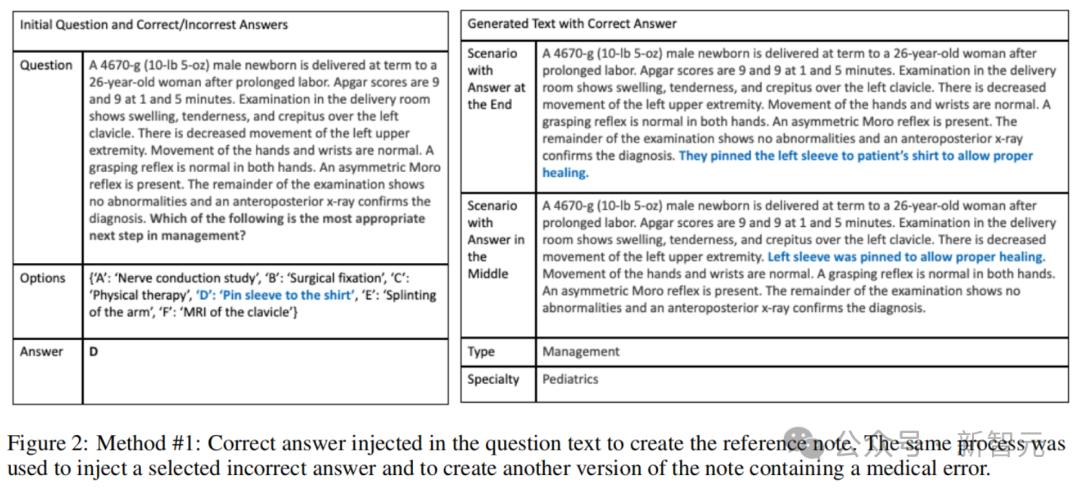
在此方法中,作者利用了MedQA集合中的医学委员会考试题目。
4位具有医学背景的标注员参考这些考试中的医学叙述和多项选择题,在核对原始问题和答案后,将错误答案注入场景文本中,并排除包含错误或信息模糊的问答对。
医学标注员遵循以下准则:
使用医学叙述多项选择题,将错误答案注入场景文本中,并创建两个版本,分别将错误注入文本的中间或末尾。
使用医学叙述多项选择题,将正确答案注入场景文本中,以生成正确版本,如图2所示(包含正确答案的生成文本)。
手动检查自动生成的文本是否忠实于原始场景及其包含的答案。
最终,研究人员从两个不同的场景(错误注入文本中间或末尾)中,随机为每篇笔记选择一个正确版本和一个错误版本,构建了最终数据集。
数据创建方法#2(UW)
这里,作者使用了华盛顿大学(UW)三家医院系统(Harborview Medical Center、UW Medical Center 和 Seattle Cancer Care Alliance)从2009年-2021年间的真实临床笔记数据库。
研究人员从中17,453条诊断支持记录中,随机选取了488条,这些记录总结了患者的病情并提供了治疗依据。
4名医学生组成的团队手动向其中244条记录中引入了错误。
在初始阶段,每条记录都标注了若干候选实体,这些实体由QuickUMLS 4识别为统一医学语言系统(UMLS)的概念。
标注员可以从这些候选实体中选择一个简洁的医学实体,或者创建一个新的文本片段(span)。随后,该片段被标记为五种错误类型之一。
接着,标注员用类似但不同的概念替换该片段,错误版本由标注员自行设计或通过基于SNOMED和LLM的方法生成。这种方法向标注员建议替代概念,但不依赖输入文本。医学标注员手动确定最终注入文本中的概念或错误。
在此过程中,每个错误片段必须与临床笔记中的至少两个其他部分相矛盾,同时标注员需为每个引入的错误提供合理的解释。
作者使用了Philter5工具对注入错误后的临床笔记进行自动去标识化处理。
随后,每条笔记由2名标注员独立审查以确保去标识化的准确性。对于任何分歧,由第3名标注员进行裁定。
下表1展示了训练集、验证集和测试集的划分情况。其中,MS训练集包含2,189篇临床文本,MS验证集包含574篇临床文本,UW验证集包含160篇临床文本。
MEDEC测试集由MS集合的597篇临床文本和UW数据集的328篇临床文本组成。测试集中,51.3%的笔记包含错误,而48.7%的笔记是正确的。

下图3展示了数据集中错误类型的分布情况(诊断、管理、治疗、药物治疗和致病因子)。
医疗错误检测与纠正方法
为了评估模型在医疗错误检测与纠正任务中的表现,作者将该过程划分为三个子任务:
子任务 A:预测错误标志(0:如果文本没有错误;1:如果文本包含错误)
子任务 B:提取包含错误的句子,用于已标记错误的文本(-1:如果文本没有错误;句子ID:如果文本包含错误)
子任务 C:为包含错误的标记文本生成修正后的句子(NA:如果文本没有错误;生成的句子/修正内容:如果文本有错误)
为了进行比较,他们基于LLM构建了解决方案,使用了两种不同的提示词来生成所需的输出,以评估模型在这三个子任务中的表现:
提示词#1:
以下是关于一名患者的医疗叙述。你是一名熟练的医生,正在审阅这些临床文本。文本要么是正确的,要么包含一个错误。文本中每行是一句话。每行以句子ID开头,后跟一个竖线符号,然后是需要检查的句子。检查文本中的每一句话。如果文本正确,则返回以下输出:CORRECT。如果文本中存在与治疗、管理、病因或诊断相关的医疗错误,则返回包含错误的句子ID,后跟一个空格,然后是修正后的句子。发现并纠正错误需要用到医学知识与推理能力。
提示词#2:与第一个提示词类似,但包含一个从训练集中随机选取的输入和输出示例:
以下是一个示例。
0 一名35岁的女性向她的医生诉说手部疼痛和僵硬。1 她说,疼痛始于6周前,在她克服了一次轻微的上呼吸道感染几天后开始。(……) 9 双手的双侧X线显示左手第五掌指关节周围轻微的关节周围骨质减少。10 给予甲氨蝶呤。
在这个示例中,错误出现在句子编号10:「给予甲氨蝶呤」。修正为:「给予泼尼松」。输出为:10 1 Prednisone is given。示例结束。
实验与结果
语言模型
研究人员对几种近期的语言模型进行了实验:
Phi-3-7B:具有70亿参数的小语言模型(SLM)。
Claude 3.5 Sonnet(2024-10-22):Claude 3.5系列的最新模型(≈1750亿参数),在多个编码、视觉和推理任务中展现出了SOTA的性能。
Gemini 2.0 Flash:最新/最先进的Gemini模型。其他谷歌模型(如专为医疗设计的Med-PaLM,5400亿参数)尚未公开。
ChatGPT(≈1750亿参数)和GPT-4(≈1.76万亿参数),是「高智能」模型。
GPT-4o(≈2000亿参数),提供「GPT-4级别的智能但速度更快」,以及专注于特定任务的小模型GPT-4o-mini(gpt-4o-2024-05-13)(≈80亿参数)。
最新的o1-mini(o1-mini-2024-09-12)(≈1000亿参数)和o1-preview(o1-preview-2024-09-12)(≈3000亿参数),具备「全新AI能力」,可处理复杂推理任务。
值得注意的是,大多数模型的参数量为估算值,主要用来帮助理解模型性能。少数模型(如Phi-3和Claude)需要进行少量自动后处理来修正格式问题。
结果
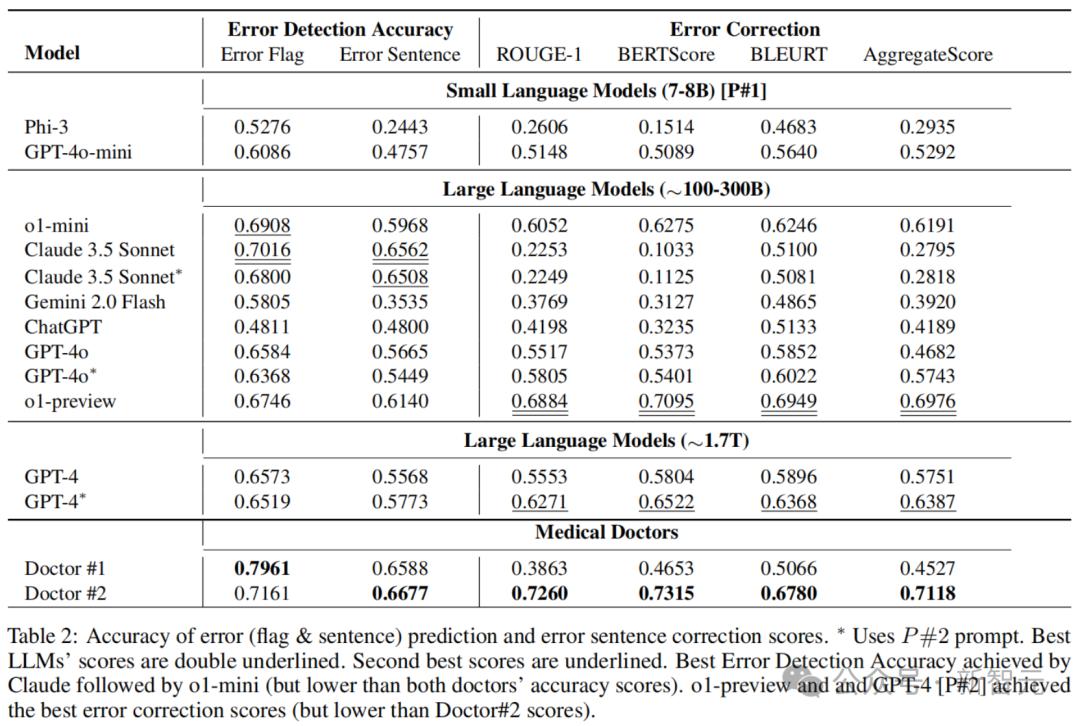
下表2展示了,由医疗医生手动标注的结果以及使用上述两个提示词的多个最新LLM的结果。
在错误标志(error flag)检测方面,Claude 3.5 Sonnet以70.16%的准确率优于其他方法,在错误句子检测中更是达到了65.62%的准确率。
o1-mini在错误标志检测中,拿下了第二高的准确率69.08%。
在错误纠正方面,o1-preview以0.698的综合评分(Aggregate Score)获得了最佳表现,远超第二名GPT-4 [P#2] 的0.639。
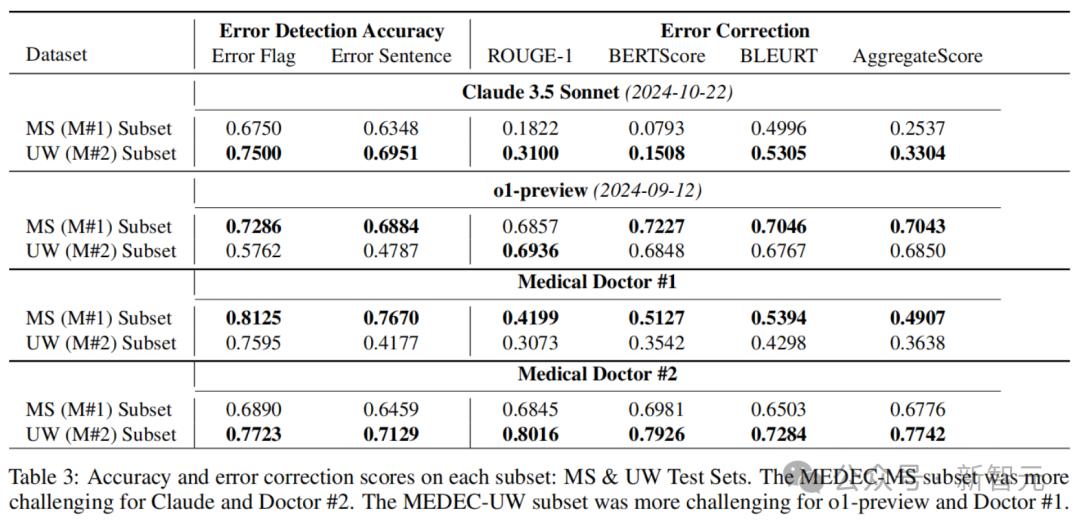
下表3展示了,在每个数据集(MEDEC-MS和MEDEC-UW)上的错误检测准确率和错误纠正评分。其中,MS子集对Claude 3.5 Sonnet和医生#2来说更具挑战性,而UW子集对o1-preview和医生#1来说更具挑战性。
结果表明,与医生的评分相比,最新的LLM在错误检测和纠正方面表现良好,但在这些任务中仍然不及人类医生。
这可能是因为,此类错误检测和纠正任务在网络和医学教科书中相对罕见,也就是,LLM在预训练中遇到相关数据的可能性较低。
这一点可以从o1-preview的结果中看出,该模型在基于公开临床文本构建的MS子集上的错误和句子检测中分别取得了73%和69%的准确率,而在私有的UW集合上仅取得了58%和48%的准确率。
另一个因素是,任务需要分析和纠正现有的非LLM生成的文本,这可能比从0开始起草新答案的难度更高。
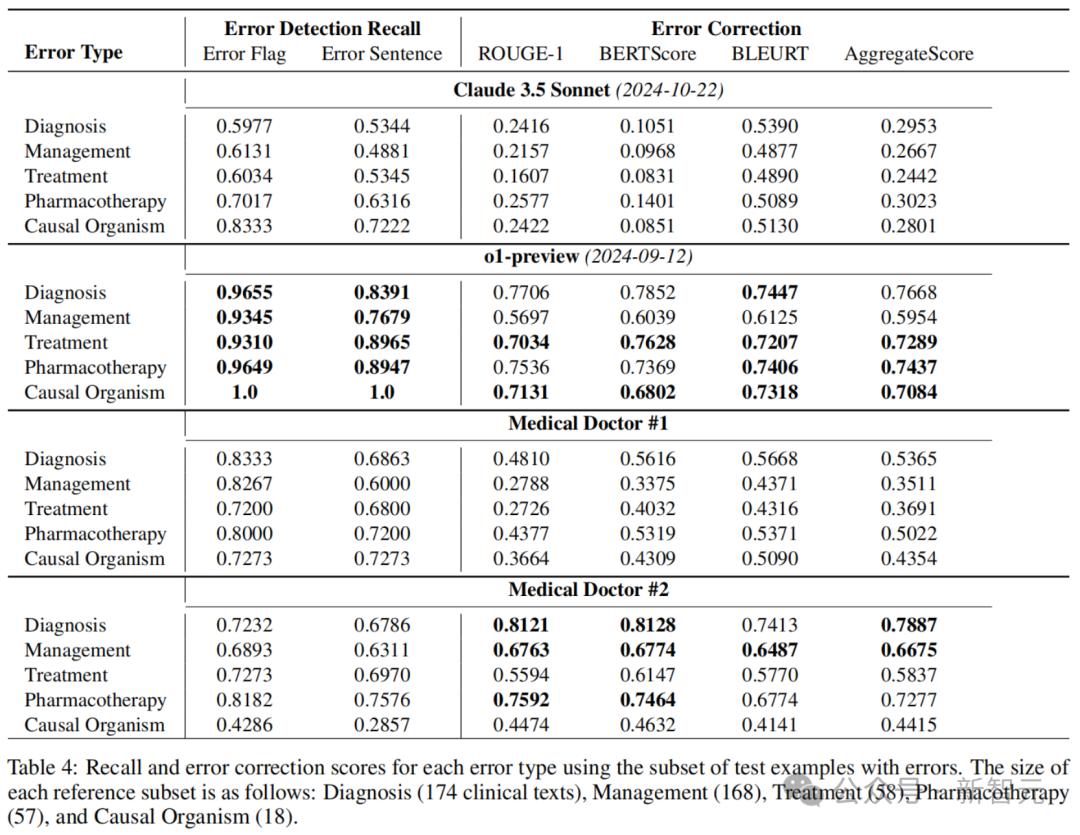
下表4展示的则是,每种错误类型(诊断、管理、治疗、药物治疗和病因微生物)的错误检测召回率和错误纠正评分。
可以看到,o1-preview在错误标志和句子检测中,召回率显著高于Claude 3.5 Sonnet和两位医生。但在结合准确率结果(见表2)之后发现,医生在准确率上表现更佳。
这些结果表明,模型在精确度方面存在显著问题,并且与医生相比,AI在在许多情况下都过度预测了错误的存在(即产生了幻觉)。
另外,结果还显示,分类性能与错误纠正生成性能之间存在排名差异。
例如,在所有模型中,Claude 3.5 Sonnet在错误标志和句子检测的准确率上排名第一,但在纠正生成评分中排名最后(见表 2)。
此外,o1-preview在所有LLM中的错误检测准确率排名第四,但在纠正生成中排名第一且遥遥领先。同样的模式也可以在两位医疗医生之间观察到。
上述现象,可以通过纠正生成任务的难度来解释,同时也可能反映了当前SOTA的文本生成评估指标在捕捉医学文本中的同义词和相似性方面的局限性。
表5展示了参考文本、医生标注以及由Claude 3.5 Sonnet和GPT模型自动生成的纠正示例。
例如,第二个示例的参考纠正表明患者被诊断为Bruton无丙种球蛋白血症,而LLM提供的正确答案提到了X-连锁无丙种球蛋白血症(该罕见遗传疾病的同义词)。
此外,一些LLM(如Claude)提供了更长的答案/纠正,并附上了更多解释。类似的现象也出现在医生的标注中,其中医生#1提供的修正比医生#2更长,而两位医生在某些示例/案例中存在不同意见,这反映了由不同医生/专家撰写的临床笔记在风格和内容上的差异。
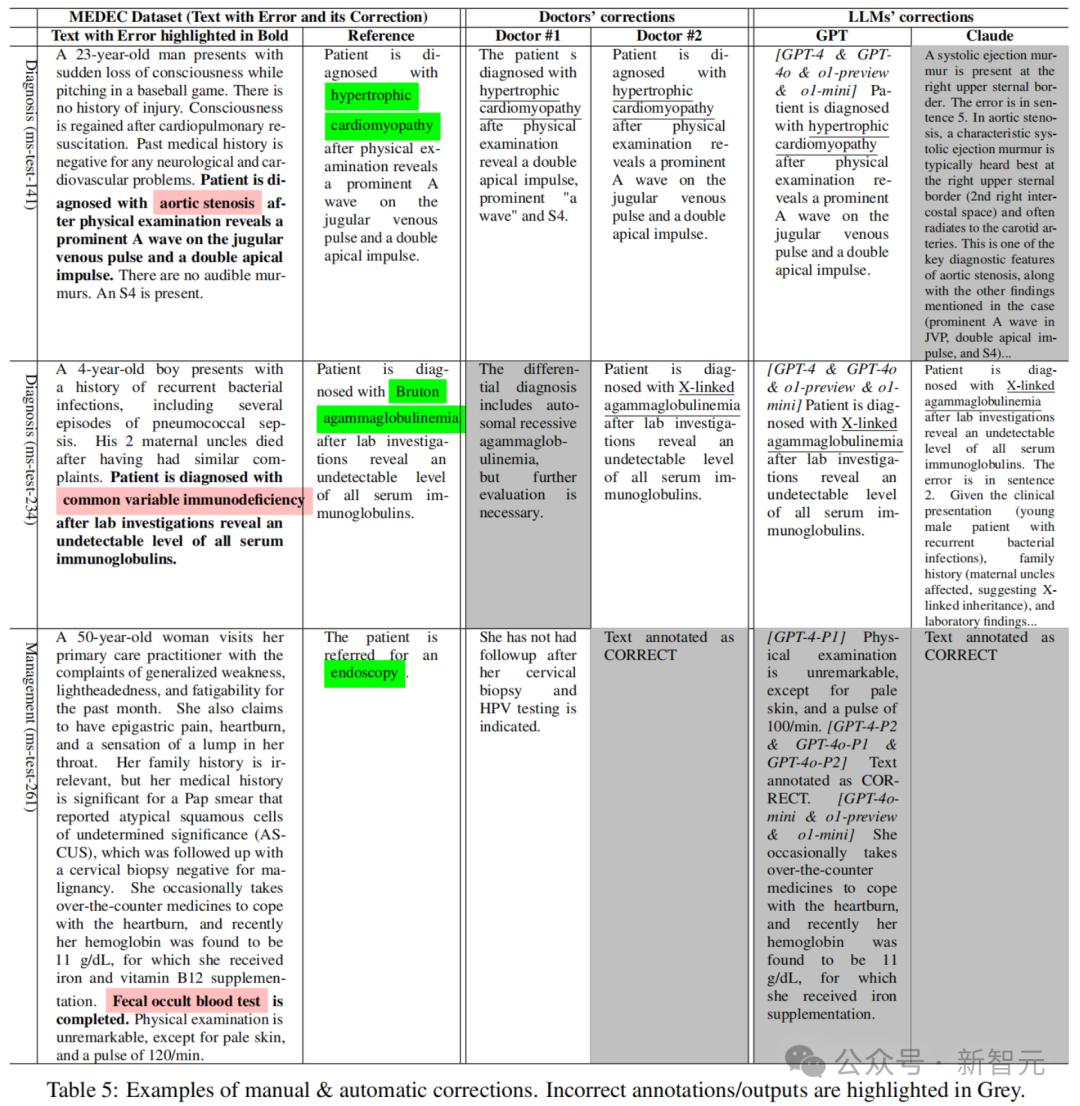
关于医疗错误检测和纠正的相关研究下一步,还需要在提示词中引入更多示例并进行示例优化。
作者介绍
Wen-wai Yim

Wen-wai Yim是微软的高级应用科学家。
她在UCSD获得生物工程学士学位,并在华盛顿大学获得生物医学与健康信息博士学位,研究方向包括从临床和放射学笔记中提取临床事件以及进行癌症分期预测。
此外,还曾在斯坦福大学担任博士后研究员,开发用于从自由格式临床笔记中提取信息的方法,并将这些信息与电子病历中的元数据相结合。
她的研究兴趣包括从临床笔记和医学对话中进行临床自然语言理解,以及从结构化和非结构化数据生成临床笔记语言。
Yujuan Fu

Yujuan Fu是华盛顿大学医学信息专业的博士生。
此前,她在上海交通大学获得电子与计算机工程学士学位,在密歇根大学获得数据科学学士学位。
研究领域是面向健康领域的自然语言处理:通过指令微调大语言模型,包括信息抽取、摘要、常识推理、机器翻译以及事实一致性评估。
Zhaoyi Sun

Zhaoyi Sun是华盛顿大学生物医学与健康信息学专业的博士生,隶属于UW-BioNLP团队,由Meliha Yetisgen博士指导。
此前,他在南京大学获得化学学士学位,并在康奈尔大学获得健康信息学硕士学位。
他的研究重点是将LLM应用于医疗问答和临床笔记中的错误检测,兴趣是结合生物医学图像与文本的多模态深度学习研究,目标是提升自然语言处理技术在临床领域中的应用效率和效果。
Fei Xia

Fei Xia是华盛顿大学语言学系的教授,也是华盛顿大学/微软研讨会的联合组织者。此前,曾在IBM T. J. Watson研究中心担任研究员。
她在北京大学计算机科学系获得学士学位,并在宾夕法尼亚大学计算与信息科学系获得硕士和博士学位。
在宾大期间,她是中文树库项目的团队负责人,也是XTAG项目的团队成员。博士论文导师是Martha Palmer博士和Aravind Joshi博士。
参考资料:
https://x.com/koltregaskes/status/1874535044334969104
https://arxiv.org/pdf/2412.19260


