

DeepSeek-R1掀起新一轮购卡潮的同时,AMD的含金量也上升了。
在AMD的MI300X上跑FP8满血R1,性能全面超越了英伟达H200——
相同延迟下吞吐量最高可达H200的5倍,相同并发下则比H200高出75%。

这个结果,一方面归功于SGLang框架,另一方面则是得益于AMD新优化的AI内核库AITER。
AITER可以用来加速GPU训练和推理,AMD副总裁Emad Barsoum直接喊出了AITER is all you need。

还有网友表示,英伟达CUDA的护城河要终结了。

之前著名黑客George Hotz也曾表示自己非常看好AMD,认为只要有好的软件MI300X表现就能超越H100。
结果MI300X超额实现了George的期待,直接把H200给超了。

吞吐翻倍、延迟更低
AMD的测试结果显示,MI300X在延迟相似的情况下实现了H200五倍的吞吐量,超过了每秒7k Tokens。
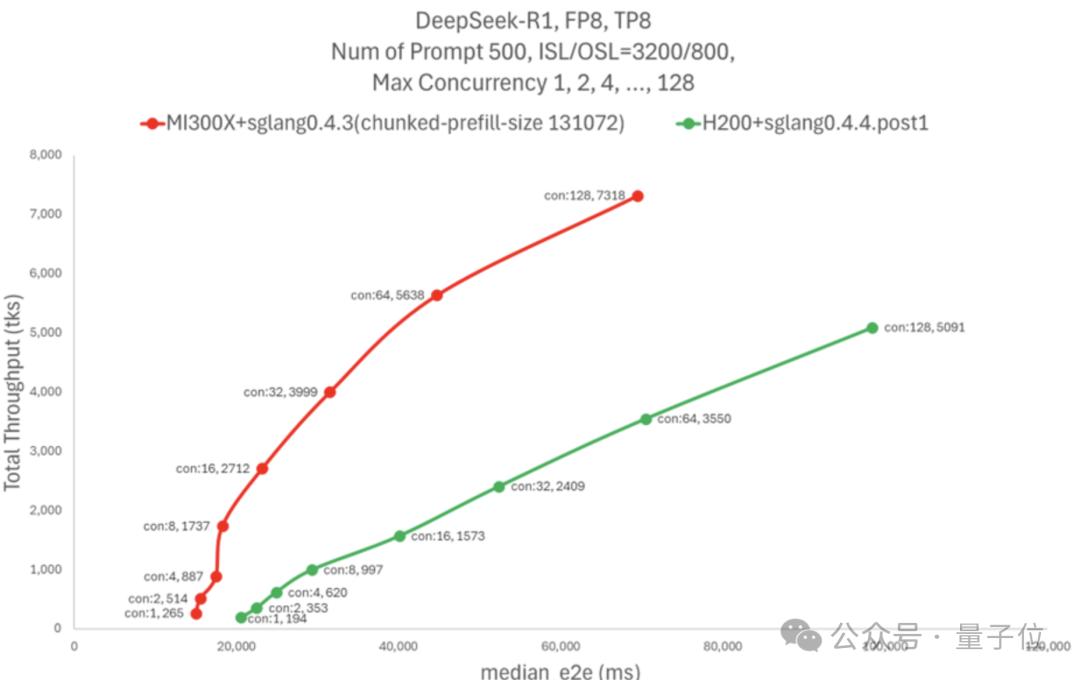
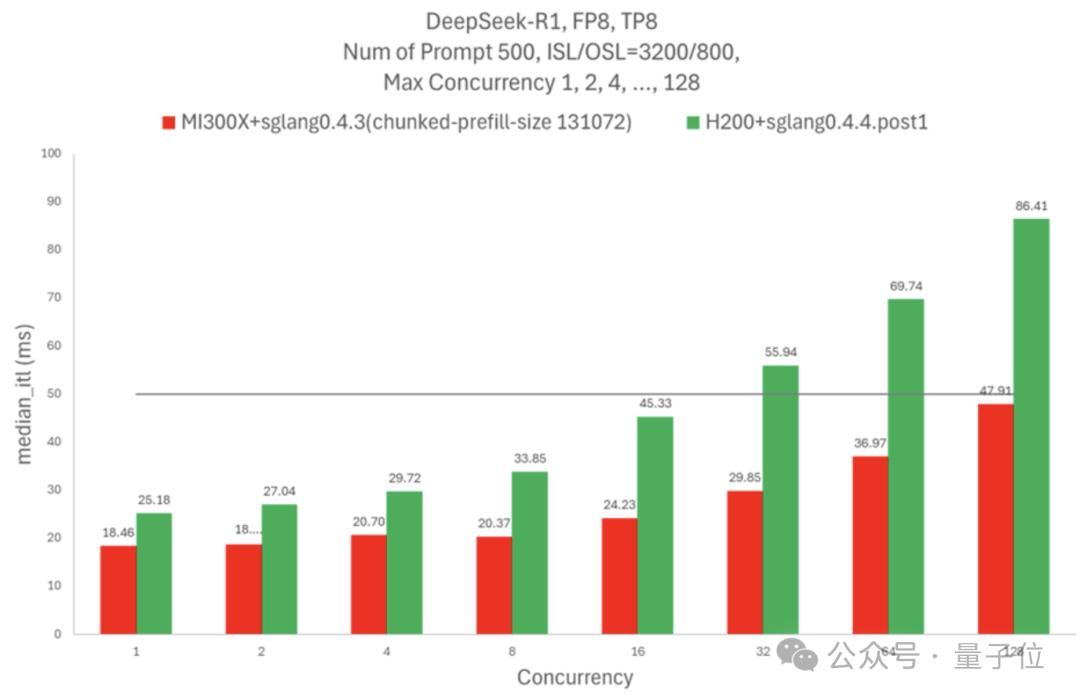
如果固定并发数量,MI300X相同并发下的吞吐量比H200高75%,延迟降低 60%。
如果需要Token间延迟不超过50毫秒,一个H200节点可以处理16个并发请求,MI300X节点则可以处理128个。
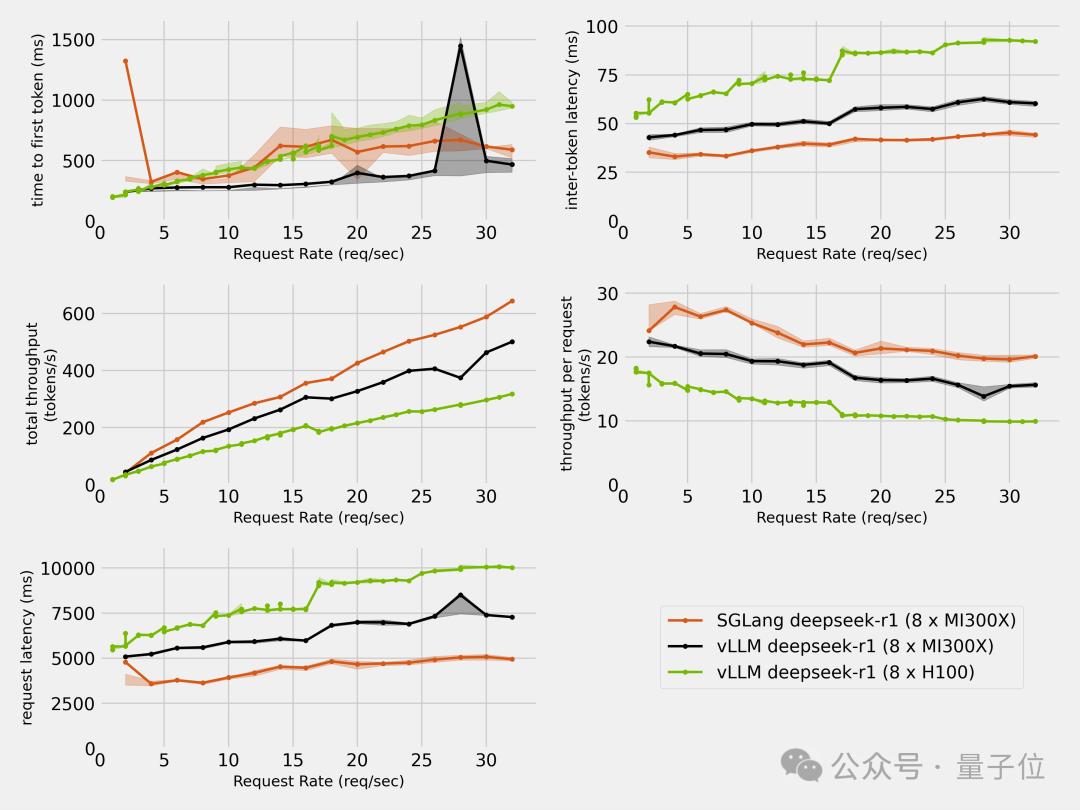
除了AMD自己,也有第三方对H100和MI300X进行了对比测试。
结果除了首个Token延迟出现了一些不稳定之外,其余的速度和延迟指标都是MI300X全面超过了H100。
看到MI300X的表现,有人拿出了老黄经典的那句“买的越多省的越多”,表示现在这句话该让AMD来说了。
那么,在这些成绩的背后,AMD都用了那些技术呢?
SGLang框架+AMD张量引擎
软件框架层面,R1在MI300X上取得优异表现的关键,是SGLang框架。
SGLang是一个开源大模型推理框架,是开源社区协作的一项成果,发起者是LMSYS,也就是搞大模型竞技场的那个组织。
SGLang在GitHub上拥有超过1.2万星标,并且不论AMD还是隔壁英伟达,以及马斯克的xAI,都非常青睐这个框架,此外AMD还是SGLang的主要贡献者之一。
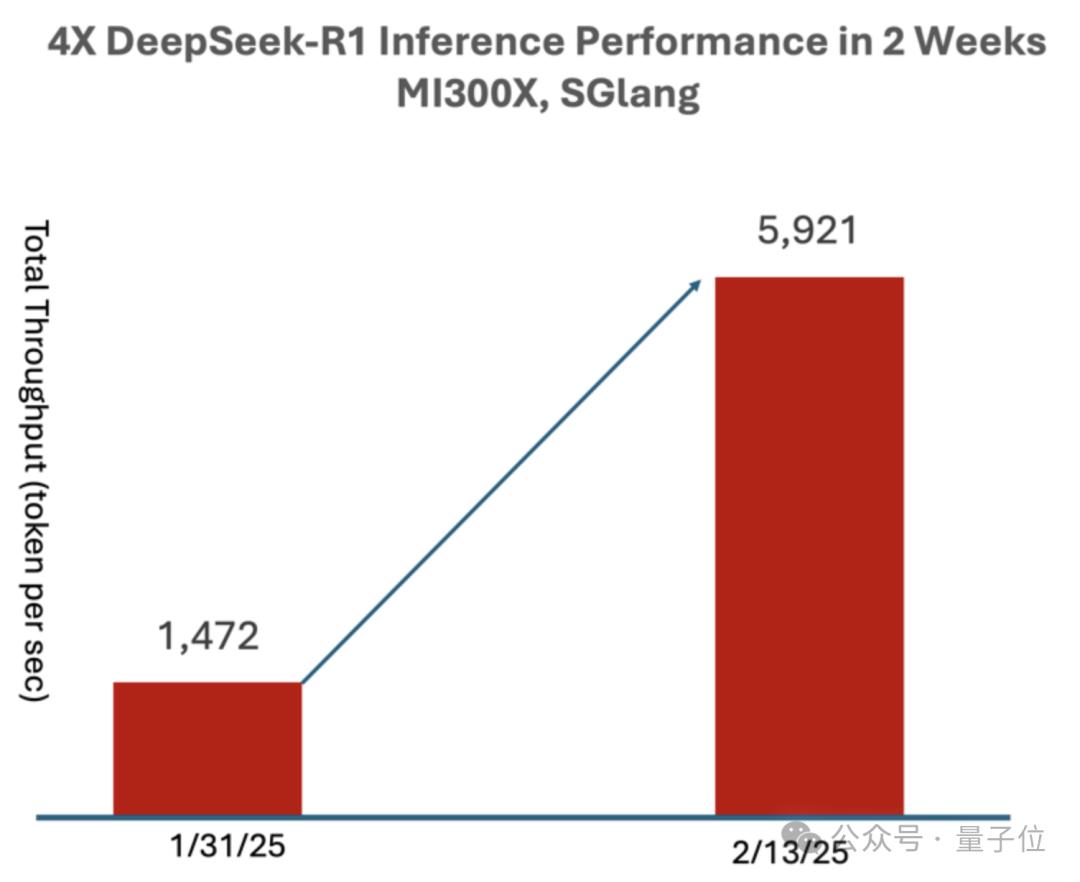
在稍早一些的测试当中,使用SGLang在MI300X上运行DeepSeek-R1,仅过了两周就相比于day 0时性能提升到了4倍,吞吐量达到了每秒5921 Tokens。
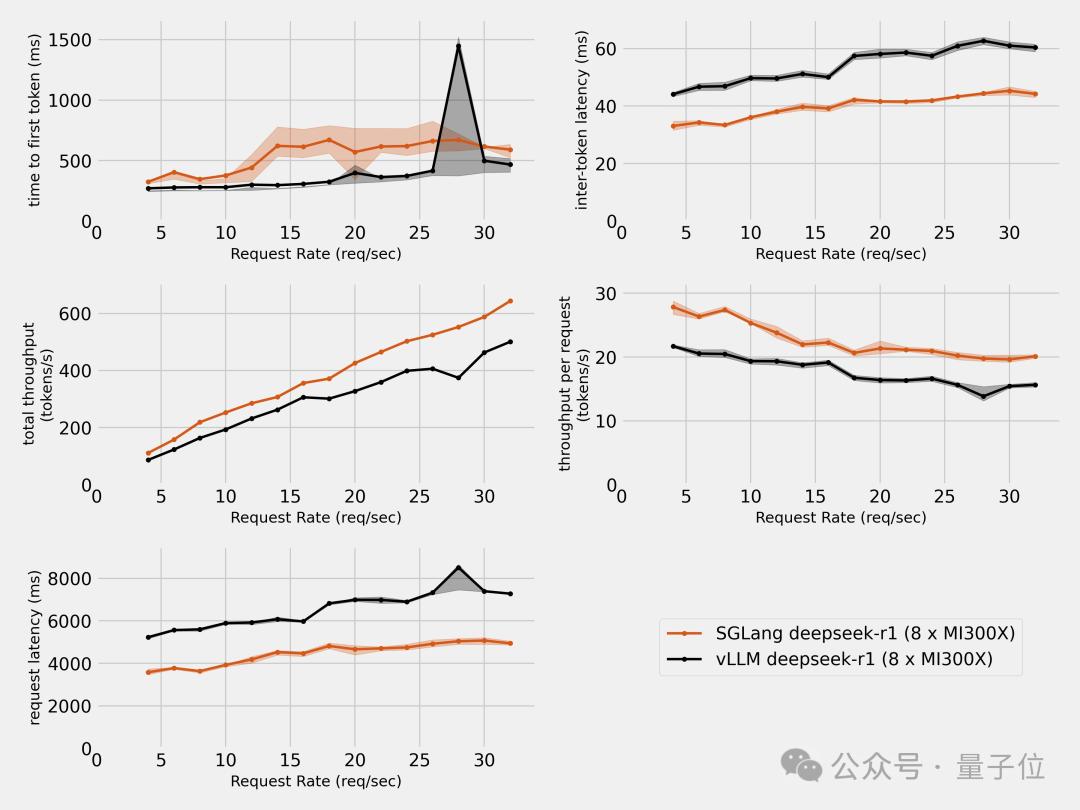
前面提到的第三方,也在MI300X上分别用SGLang和vLLM进行了测试,结果SGLang完胜。
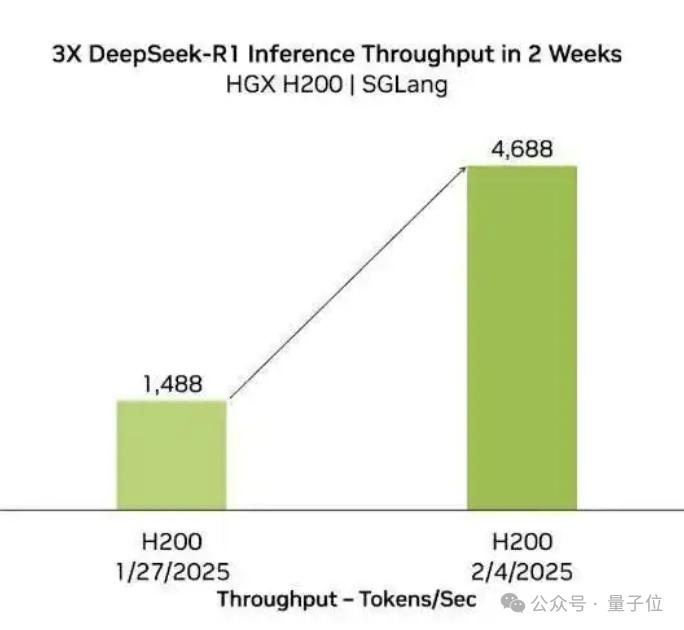
实际上,SGLang一直是DeepSeek模型的一个最佳拍档,不仅对于AMD,在英伟达H200上,也能带来类似的性能提升。
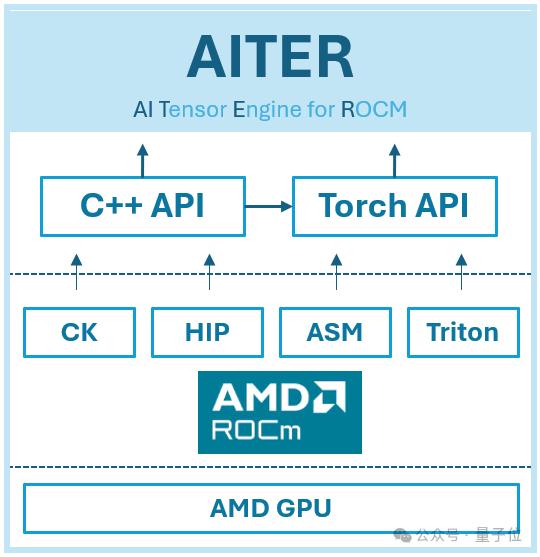
而在硬件层面,MI300X高效运行R1的关键,是AMD为ROCm(可以理解为AMD版CUDA)打造的AI张量引擎AITER。
AITER是一个包含大量高性能AI算子的集中式存储库,也是一个统一平台,可以轻松找到优化的算子并将其集成到现有框架中。
AITER的基础架构建立在多种底层技术之上,包括 Triton、CK(计算内核)、ASM(汇编)和 HIP(异构可移植性接口)。
它支持各种计算任务,例如推理工作负载、训练内核、GEMM(通用矩阵乘法)运算和通信内核。
它可以让GEMM的性能提升2倍、MoE性能提升3倍、MLA解码性能提升17倍、MHA预填充性能提升14倍。
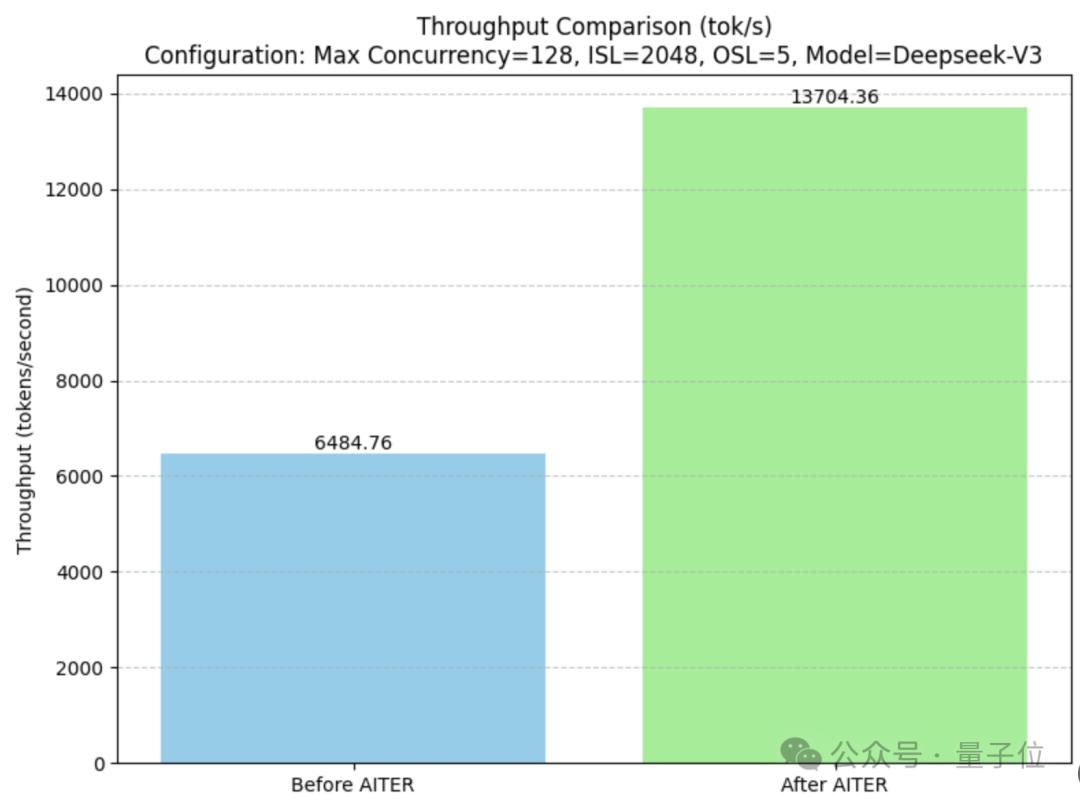
开启AITER后,MI300X上DeepSeek-V3的吞吐量是开启前的两倍多。
除了框架和硬件的适配,AMD还进行了超参数调整。
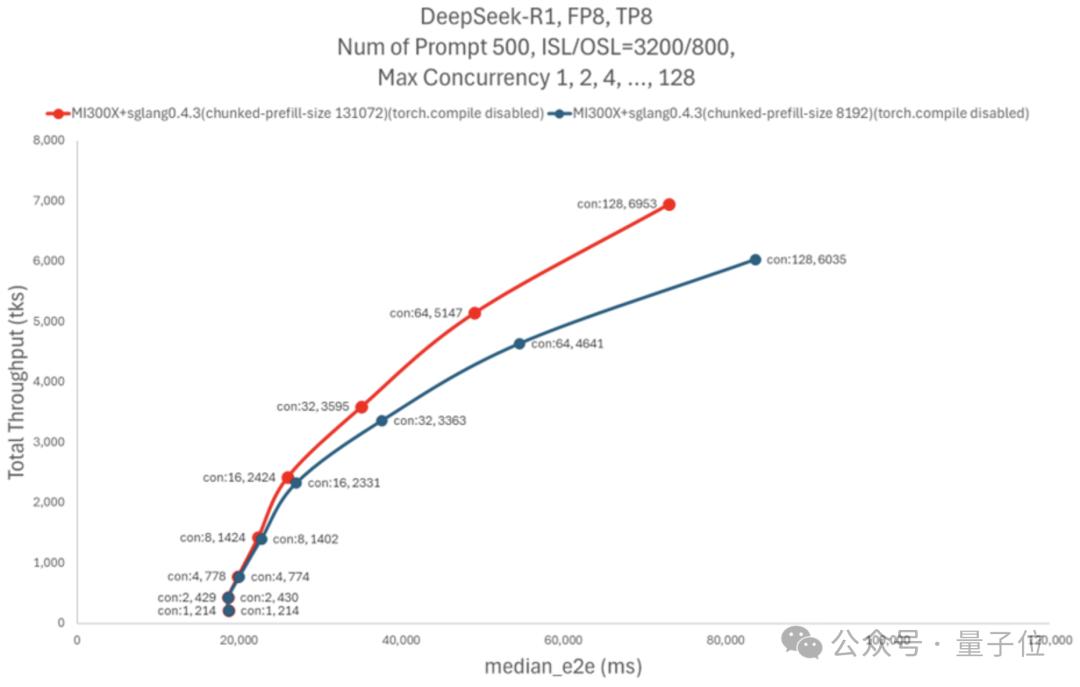
AMD发现,当运行具有大量线程(例如128个或更多)的程序时, 由于预填充吞吐量缓慢,带来了系统的性能瓶颈。
于是AMD提高了chunked_prefill_size参数的大小,用更高的内存占用换取了预填充过程的加速。
不过考虑到内存容量大本就是MI300X的一大特色,这种选择也不失为一种更优的结果。
那么,你觉得这次AMD是不是又Yes了呢?
参考链接:
[1]https://rocm.blogs.amd.com/artificial-intelligence/DeepSeekR1-Part2/README.html、
[2]https://x.com/tngtech/status/1901779226602115076
[3]https://geohot.github.io//blog/jekyll/update/2025/03/08/AMD-YOLO.html


