


编者按:芯事重重“算力经济学”系列研究,聚焦算力、成本相关话题的技术分析、产业穿透,本期聚焦ASIC芯片自研与产业链研究。本文系基于公开资料撰写,仅作为信息交流之用,不构成任何投资建议。
作者:由我、苏扬
编辑:郑可君
DeepSeek带动推理需求爆发,英伟达的“算力霸权”被撕开一道口子,一个新世界的大门逐渐打开——由ASIC芯片主导的算力革命,正从静默走向喧嚣。
日前,芯流智库援引知情人士的消息,称DeepSeek正在筹备AI芯片自研。相比这个后起之秀,国内大厂如阿里、百度、字节们更早就跨过了“自研”的大门。
大洋彼岸,OpenAI自研芯片的新进展也在年初释出,外媒披露博通为其定制的首款芯片几个月内将在台积电流片。
此前更是一度传出Sam Altman计划筹集70000亿美元打造“芯片帝国”,设计与制造通吃。此外,谷歌、亚马逊、微软、Meta也都先后加入了这场“自研热潮”。
一个明显的信号是——无论DeepSeek、OpenAI,还是中国公司和硅谷大厂,谁都不希望在算力时代掉队。而ASIC芯片,可能会成为他们跨越新世界大门的入场券。
这会不会“杀死”英伟达?或者,会不会“再造”第二个英伟达?现在还没有答案。
不过可以明确的是,这场轰轰烈烈的“自研浪潮”,其上游的产业链企业已经“春江水暖鸭先知”,例如给各家大厂提供设计定制服务的博通,业绩已经“起飞”:2024年AI业务收入同比240%,达到37亿美元;2025Q1AI业务营收41亿美元,同比增77%;其中80%来自ASIC芯片设计。
在博通的眼里,ASIC芯片这块蛋糕,价值超过900亿美元。
01
从GPU到ASIC,算力经济学走向分水岭
低成本是AI推理爆发的必要条件,与之相对的是——通用GPU芯片成了AI爆发的黄金枷锁。
英伟达的H100和A100是大模型训练的绝对王者,甚至连B200、H200也让科技巨头们趋之若鹜。金融时报此前援引Omdia的数据,2024年,英伟达Hopper架构芯片的主要客户包括微软、Meta、Tesla/xAI等,其中微软的订单量达到50万张。
但是,作为通用GPU的绝对统治者,英伟达产品方案其“硬币的另一面”已逐渐显现:高昂的成本与冗余的能耗。
成本方面,单个H100售价超3万美元,训练千亿参数模型需上万张GPU,再加上网络硬件、存储和安全等后续的投入,总计超5亿美元。根据汇丰的数据,最新一代的GB200 NVL72方案,单机柜超过300万美元,NVL36也在180万美元左右。
可以说,基于通用GPU的模型训练太贵了,只不过是算力不受限制的硅谷,仍然偏向于“力大砖飞”的叙事,资本支出并未就此减速。就在日前,马斯克旗下xAI,不久之前公布的Grok-3,训练的服务器规模,已经达到了20万张GPU的规模。
腾讯科技联合硅兔赛跑推出的《两万字详解最全2025 AI关键洞察》一文提到,超大规模数据中心运营商预计2024年资本支出(CapEx)超过 2000亿美元,到2025年这一数字预计将接近2500亿美元,且主要资源都将倾斜给人工智能。
能耗方面,根据SemiAnalysis的测算,10万卡H100集群,总功耗为150MW,每年耗费1.59TWh的电量,按0.078美元/千瓦时计算,每年电费高达1.239亿美元。
对照OpenAI公布的数据,推理阶段GPU的算力利用率仅30%-50%,“边算边等”现象显著,如此低效的性能利用率,在推理时代,确实是大材小用,浪费过于严重。
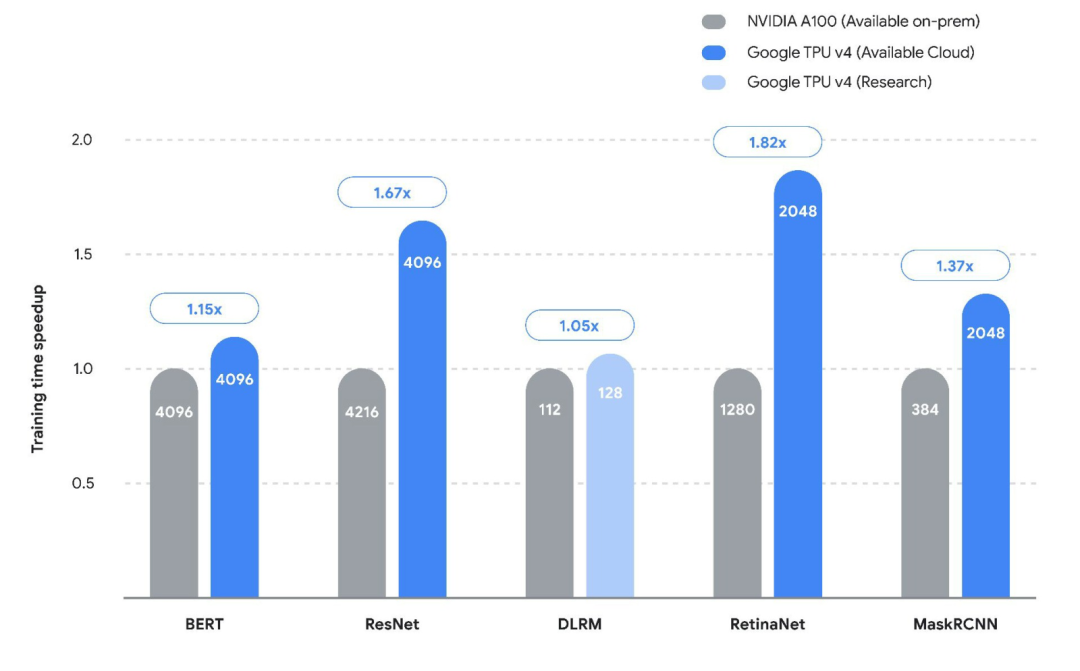
谷歌此前公布的TPU V4与A100针对不同架构模型的训练速度
性能领先、价格昂贵,效率不佳,外加生态壁垒,过去一年业内都在喊“天下苦英伟达久矣”——云厂商逐渐丧失硬件自主权,叠加供应链风险,再加上AMD暂时还“扶不起来”,诸多因素倒逼巨头开始自研ASIC专用芯片。
自此,AI芯片战场,从技术竞赛转向经济性博弈。
正如西南证券的研究结论,“当模型架构进入收敛期,算力投入的每一美元都必须产出可量化的经济收益。”
从北美云厂商最近反馈的进展看,ASIC已体现出一定的替代优势:
● 谷歌:博通为谷歌定制的TPU v5芯片在Llama-3推理场景中,单位算力成本较H100降低70%。
● 亚马逊:3nm制程的AWS Trainium 3,同等算力下能耗仅为通用GPU的1/3,年节省电费超千万美元;据了解,亚马逊Trainium芯片2024年出货量已超50万片。
● 微软:根据IDC数据,微软Azure自研ASIC后,硬件采购成本占比从75%降至58%,摆脱长期被动的议价困境。
作为北美ASIC链的最大受益者,博通这一趋势在数据中愈发显著。
博通2024年AI业务收入37亿美元,同比增240%,其中80%来自ASIC设计服务。2025Q1,其AI业务营收41亿美元,同比增77%,同时预计第二季度AI营收44亿美元,同比增44%。
早在年报期间,博通指引2027年ASIC收入将大爆发,给市场画了3年之后ASIC芯片将有望达到900亿美元的市场规模这个大饼。Q1电话会期间,公司再次重申了这一点。
凭借这个大的产业趋势,博通也成为全球继英伟达、台积电之后,第三家市值破1万亿美元的半导体公司,同时也带动了海外对于Marvell、AIchip等公司的关注。
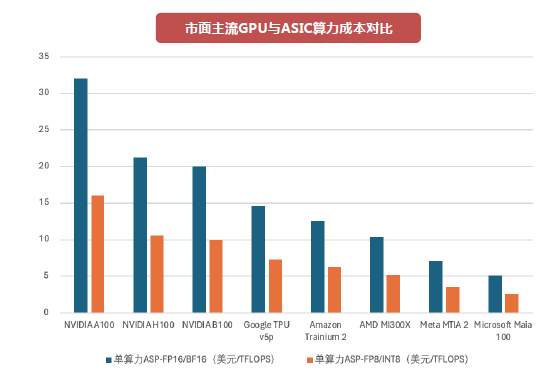
图:市面主流GPU与ASIC算力成本对比 资料来源:西南证券
不过,有一点需要强调——“ASIC虽好,但也不会杀死GPU”。
微软、谷歌、Meta都在下场自研,但同时又都在抢英伟达B200的首发,这其实说明了双方之间不是直接的竞争关系。
更客观的结论应该是,GPU仍将主导高性能的训练市场,推理场景中由于GPU的通用性仍将是最主要的芯片,但在未来接近4000亿美元的AI芯片蓝海市场中,ASIC的渗透路径已清晰可见。
IDC预测,2024-2026年推理场景中,ASIC占比从15%提升至40%,即最高1600亿美元。
这场变革的终局或许是:ASIC接管80%的推理市场,GPU退守训练和图形领域。真正的赢家将是那些既懂硅片、又懂场景的“双栖玩家”,英伟达显然是其中一员,看好ASIC断然不是唱空英伟达。
而新世界的指南,是去寻找除英伟达之外的双栖玩家,如何掘金ASIC新纪元。
02
ASIC的“手术刀”:非核心模块,通通砍掉
锦缎在《DeepSeek的隐喻:GPU失其鹿,ASIC、SoC们共逐之》一文中详解过SoC,而CPU、GPU用户早已耳熟能详,FPGA应用市场小众,最为陌生的当属ASIC。
特性 |
CPU |
GPU |
FPGA |
ASIC |
定制化程度 |
通用 |
半通用 |
半定制化 |
全定制化 |
灵活性 |
高 |
高 |
高 |
低 |
成本 |
较低 |
高 |
较高 |
低 |
功耗 |
较高 |
高 |
较高 |
低 |
主要优点 |
通用性最强 |
计算能力强,生态成熟 |
灵活强较高 |
能效最高 |
主要缺点 |
并行算力弱 |
功耗较大,编程难度较大 |
峰值计算能力弱,编程难度较难 |
研发时间长,技术风险高 |
应用场景 |
较少用于AI |
云端训练和推理 |
云端推理,终端推理 |
云端训练和推理,终端推理 |
图:算力芯片对比 资料来源:中泰证券
那么,都说ASIC利好AI推理,究竟它是一个什么样的芯片?
从架构上来说, GPU这样的通用芯片,其局限在于“以一敌百”的设计——需要兼顾图形渲染、科学计算、不同的模型架构等多元需求,导致大量晶体管资源浪费在非核心功能模块。
英伟达GPU最大的特点,就是有众多“小核”,这些“小核”可以类比成猎鹰火箭多台发动机,开发者可以凭借CUDA多年积累的算子库,平稳、高效且灵活地调用这些小核用于并行计算。
但如果下游模型相对确定,计算任务就是相对确定的,不需要那么多小核来保持灵活性,ASIC最底层的原理正是如此,所以也被称为全定制化高算力芯片。
通过 “手术刀式”精准裁剪,仅保留与目标场景强相关的硬件单元,释放出惊人的效率,这在谷歌、亚马逊都已经在产品上得到了验证。

谷歌TPU v5e AI加速器实拍
对于GPU来说,调用它们最好的工具是英伟达的CUDA,而对于ASIC芯片,调用它们的是云厂商自研的算法,这对于软件起家的大厂来说,并不是什么难事:
● 谷歌TPU v4中,95%的晶体管资源用于矩阵乘法单元和向量处理单元,专为神经网络计算优化,而GPU中类似单元的占比不足60%。
● 不同于传统冯·诺依曼架构的“计算-存储”分离模式,ASIC可围绕算法特征定制数据流。例如在博通为Meta定制的推荐系统芯片中,计算单元直接嵌入存储控制器周围,数据移动距离缩短70%,延迟降低至GPU的1/8。
● 针对AI模型中50%-90%的权重稀疏特性,亚马逊Trainium2芯片嵌入稀疏计算引擎,可跳过零值计算环节,理论性能提升300%。
当算法趋于固定,对于确定性的垂直场景,ASIC就是具有天然的优势,ASIC设计的终极目标是让芯片本身成为算法的“物理化身”。
在过去的历史和正在发生的现实中,我们都能够找到ASIC成功的力证,比如矿机芯片。
早期,行业都是用英伟达的GPU挖矿,后期随着挖矿难度提升,电力消耗超过挖矿收益(非常类似现在的推理需求),挖矿专用ASIC芯片爆发。虽然通用性远不如GPU,但矿机ASIC将并行度极致化。
例如,比特大陆的比特币矿机ASIC,同时部署数万个SHA-256哈希计算单元,实现单一算法下的超线性加速,算力密度达到GPU的1000倍以上。不仅专用能力大幅提升,而且能耗实现了系统级节省。
此外,使用ASIC可精简外围电路(如不再需要PCIe接口的复杂协议栈),主板面积减少40%,整机成本下降25%。
低成本、高效率,支持硬件与场景深度咬合,这些ASIC技术内核,天然适配AI产业从“暴力堆算力”到“精细化效率革命”的转型需求。
随着推理时代的到来,ASIC成本优势将重演矿机的历史,实现规模效应下的“死亡交叉”——尽管初期研发成本高昂(单芯片设计费用约5000万美元),但其边际成本下降曲线远陡于通用GPU。
以谷歌TPU v4为例,当出货量从10万片增至100万片时,单颗成本从3800美元骤降至1200美元,降幅接近70%,而GPU的成本降幅通常不超过30%。根据产业链最新信息,谷歌TPU v6预计2025年出货160万片,单片算力较前代提升3倍,ASIC的性价比,还在快速提升。
这又引申出一个新的话题,是否所有人都可以涌入自研ASIC大潮中去?这取决于自研成本与需求量。
按照7nm工艺的ASIC推理加速卡来计算,涉及IP授权费用、人力成本、设计工具、掩模板在内的一次流片费用等,量级可能就在亿元的级别,还不包括后期的量产成本。在这方面,大厂更具有资金优势。
目前,像谷歌、亚马逊这样的云厂商,因为有成熟的客户体系,能够形成研发、销售闭环,自研上拥有先天的优势。
Meta这种企业,自研的逻辑则在于内部本身就有天量级的算力需求。今年初,扎克伯格就曾透露,计划在2025年上线约1GW的计算能力,并在年底前拥有超过130万张GPU。
03
“新地图”价值远不止1000亿美元
仅仅是挖矿需求就带来了近100亿美元的市场,所以当博通2024年底喊出AI ASIC市场空间700-900亿美元的时候,我们并不意外,甚至认为可能这个数字都保守了。
现在,ASIC芯片的产业趋势不应当再被质疑,重点应该是如何掌握“新地图”的博弈法则。
近千亿美元的AI ASIC市场中,已经形成清晰的三大梯队——“制定规则的ASIC芯片设计者和制造者” 、“产业链配套”、“垂直场景下的Fabless”。
第一梯队,是制定规则的ASIC芯片设计者和制造者,他们可以制造单价超过1万美元的ASIC芯片,并与下游的云厂商合作商用,代表玩家有博通、Marvell、AIchip,以及不管是什么先进芯片都会受益的代工王者——台积电。
第二梯队,产业链配套,已经被市场关注到的配套逻辑包括先进封装与更下游的产业链。
● 先进封装:台积电CoWoS产能的35%已转向ASIC客户,国产对应的中芯国际、长电科技、通富微电等。
● 云厂商英伟达硬件方案解耦带来的新硬件机会:如AEC铜缆,亚马逊自研单颗ASIC需配3根AEC,若2027年ASIC出货700万颗,对应市场超50亿美元,其他还包括服务器、PCB均是受益于相似逻辑。
第三梯队,是正在酝酿的垂直场景的Fabless。ASIC的本质是需求驱动型市场,谁能最先捕捉到场景痛点,谁就掌握定价权。ASIC的基因就是定制化,与垂直场景天然适配。以智驾芯片为例,作为典型的ASIC芯片,随着比亚迪等All in智驾,这类产品开始进入爆发期。
映射全球ASIC产业链三大梯队对应的机会,可以看作是国产的“三把秘钥”。
受制于禁令的限制,国产GPU与英伟达的差距仍然巨大,生态建设也是一个漫长的路程,但是对于ASIC,我们甚至与海外在同一起跑线上,再结合垂直场景,中国不少Fabless能够做出更有能效比的产品,前面提及的矿机ASIC、智驾ASIC以及阿里平头哥的含光、百度的昆仑芯这些AI ASIC。
与之配套的芯片制造,主要依赖中芯国际,中兴旗下的中兴微等则是新入场的“玩家”,不排除未来他们将与国内厂商合作,上演一场“谁将是中国博通”的戏码。
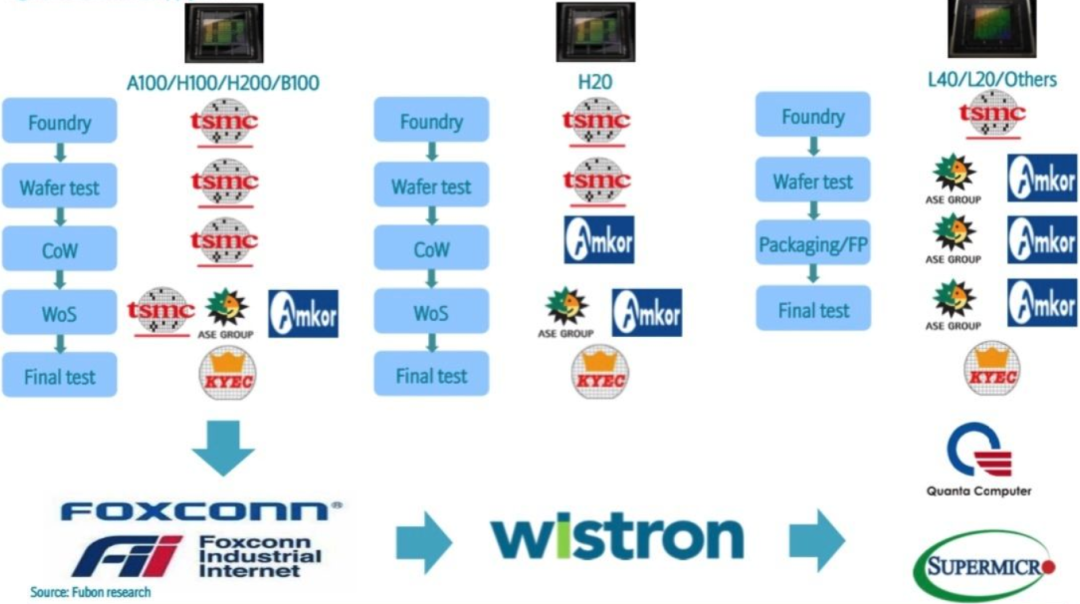

左图为英伟达主要上游供应商,来源Fubon Research ,右图GB200 NV72L机柜的总长接近2英里的NVlink Spine铜缆
产业链配套部分难度相对较低,对应的服务器、光模块、交换机、PCB、铜缆,由于技术难度低,国内企业本来竞争力就比较强。与此同时,这些产业链企业与国产算力属于“共生”关系,ASIC芯片产业链也不会缺席。
应用场景上,除了反复提及的智驾芯片和AI推理加速卡,其他国产设计公司的机会,取决于什么场景能爆发,对应哪些公司又能把握住机遇。
04
结语
当AI从大力出奇迹的训练军备竞赛,跃进推理追求能效的深水区,算力战争的下半场注定属于那些能将技术狂想,转化为经济账本的公司。
ASIC芯片的逆袭,不仅是一场技术革命,更是一本关于效率、成本和话语权的商业启示录。
在这场新的牌局中,中国选手的筹码正在悄然增加——机会永远留给准备好的人。


