

就在OpenAI热闹的12天发布会刚刚落下帷幕,谷歌的火力全开新模型Voe2和Gemnini2吸引了全球AI开发者的眼球时,Meta作为三巨头之一则在筹划着一场静悄悄的革命。
这场革命不是关于Agent、图像这些AI界最火的方向,而是关于AI的思维方式——他们正试图改变机器"思考"的根本逻辑。
在人工智能发展史上,语言处理一直面临着一个根本性的矛盾:我们试图用离散的符号系统(也就是所谓的“token”)来捕捉本质上连续且复杂的人类思维。
这种方法之所以流行,很大程度上是出于工程实现的考虑。
计算机只能处理离散的数值表示,因此需要将文本转换为向量进行数学运算,而token是实现这种转换的最简单直接的方式。它可以基于确定的词表进行切分和映射,就可以把任意长度的句子变成离散的向量。
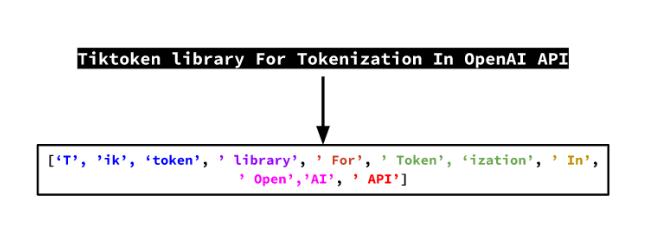
(tokenizaiton的示例)
它在工程实现上相对容易,因此这种方法在实践中确实取得了显著成功。
然而,这种基于token的方法存在着根本性的局限:它和人类的思维差得太多了。
Hyperbolic的CTO Yuchen Jin就表示,人类并不以“token”的方式进行思考。而是以“概念”的形式去思考。

token和概念之间的关系就类似于语义与语词。
想象一个外国人在学习中文,他可能记住了每个字的读音和意思,但却无法理解“山雨欲来风满楼”这样的诗句。因为理解这句诗不仅需要认识每个字,更需要理解“山雨”、“风”与“危机感”这些概念之间的联系。
而原来通过token学习的AI就只能通过学习都不是完整表意字的token间的联系,去预测下一个token。
而这也是很多人工智能专家都不相信这种基于token的AI真正能够理解这个世界的原因。
比如Meta的另一位研究员,日内瓦大学教授Francois Fleuret也认为OpenAI现在选择的COT之路,不过是一种“对真东西(人类思维)的劣化的模仿”。

他认为,应该具有一个在潜空间上更可观察的,能在抽象空间里进行动态思考的LLM。
但事实上Meta已经在朝着这个方向努力了。
在整个12月,他们连发三篇论文,挑战token思维模式。最近的是在12月24日,Meta发表了一篇论文《Large Concept Models:Language Modeling in a Sentence Representation Space》,让大模型直接从概念学起。

他们管这种利用概念训练的模型叫做“大概念模型”(LCM)。
让大模型直接学概念
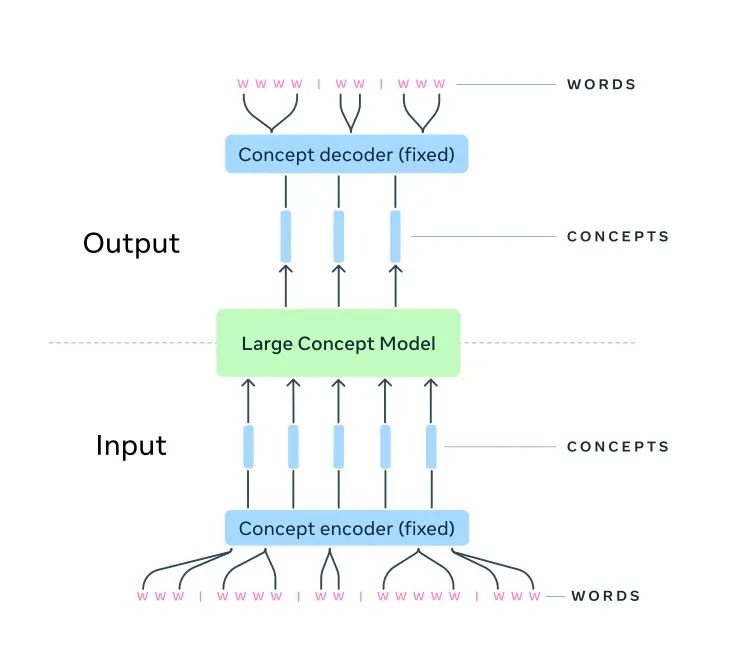
Meta研究团队的思路其实很简单:让大模型直接学概念,其实就是把句子还原成一组组概念的序列去训练它,取代原来token序列的训练。

这个概念转换的工具,Meta用的是SONAR。
它是一个编译器,能够将文本映射到概念空间,生成1024维的向量来表示这个概念,而相似的概念在这个潜在空间里就会比较接近。因为它的概念化能力,SONAR模型本身就可以在200种语言之间进行语言翻译。

(SONAR的基本运作逻辑)
SONAR是在token和最终理解之间搭建了一座桥梁,让模型既能跳过token,直接把握更高层的语义关联。LCM所接受和输出的就只有概念向量。
有了这个概念层抽象,关键问题是如何设计一个能够处理概念的模型架构。 研究团队详细探索了三种方案:
第一种是基础LCM架构。在这个方案中,前置网络(SONAR)首先处理输入文本的token序列,将其映射到概念空间中的向量表示。一个Transformer模型接收概念向量,然后预测之后的概念向量。最后,后置网络(SONAR)接收这个概念表示,尝试生成对应的目标语言表达。

用更容易理解的方式表达就是:

这种架构的优点是结构清晰,训练相对稳定,但存在信息瓶颈问题:所有的语义信息都必须通过中间的概念向量传递,容易造成信息损失。
比如看到"我今天很开心",后面可能跟:"因为考了满分","因为见到了朋友","因为收到了礼物"。模型会倾向预测一个"中间状态"。把所有可能的回答混在一起, 结果可能变得模糊不清。
Base-LCM就像一个只会给"标准答案"的学生,缺少创造力和随机性。
第二种是Quant-LCM架构。在这个方案中,模型会把SONAR提供的概念层再做一遍向量化,把连续概念重新打散成离散码本。比如描述"苹果",原来SONAR是把这个概念做成一个1024维的向量来精确描述每个特征,但在Quant-LCM中,它就只用红色, 圆形, 水果, 甜味这么几个简单的特征码去描述“苹果”。
这样计算更快更简单,也更有创造力。因为这就像是用用基本词汇组合新句子。但精度损失会比较明显,模型效能不怎么好。
鉴于前两种方法的劣势太明显,Meta最终采用了第三种方法:Diffusion双塔架构。这个架构包含两个主要组件:左边的塔和Basic LCM的结构一样,就像一个写文章框架的人,力求概念准确。另一座塔(Diffsuion去噪器)就像是一个编辑,负责润色和丰富用词。

(Diffusion双塔结构示意)
Diffusion去噪器的工作方式有点像是一个反复推敲的编辑:先把得到的信息故意"弄模糊"(加噪),然后再通过一步步的提炼(去噪)来重建内容。
在训练过程中,系统还使用了一个特殊的掩码策略,这就是图右边那个看似复杂的矩阵表示的内容。这个策略有点像是给系统设置不同难度的"练习题":有时候让它看到完整的上下文来工作,有时候(比如图中红色标注的那行)则刻意遮住一些信息,让系统学会在信息不完整的情况下也能工作。这种训练方法帮助系统建立起更强的适应能力和鲁棒性。
这样一座双塔结构就可以避免Basic LCM过分古板的问题,用Diffusion给它增加了足够的随机性和细节。
这是三种方法中最好的一种。
经Meta的研究者测试,LCM在多个标准评测任务上都展现出了优秀的性能,尤其在跨语言和长文本生成任务上展现出一定优势。这是因为概念本身的链接比token的链接覆盖的范围更大,我们也可以推测大模型的语义理解通过这一训练得到了加强。
在跨语言任务上,LCM更是优于现有的LLMs。因为当我们理解"望子成龙"这样的成语时,如果只理解具体字词的含义,对应翻译,无论如何都得不到"Like father, like son"这样的实际对应翻译。因为英语和中文虽然表达了类似的文化概念,但字面上完全不同。而直接把握概念的LCM就很容易做到。
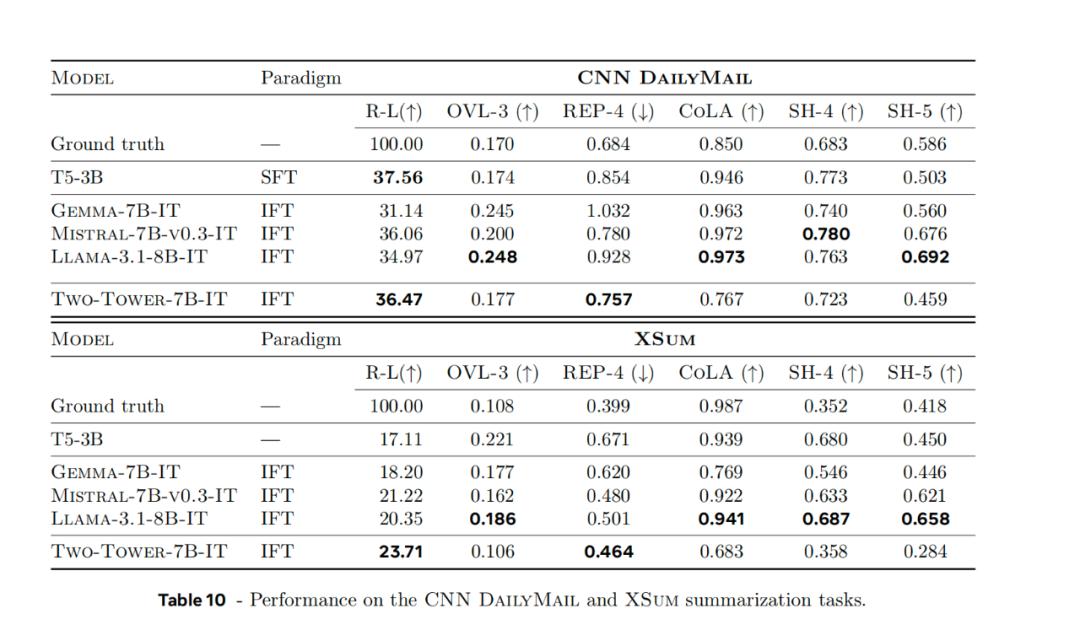
具体我们可以具体看一下LCM比LLM强的一些方面:
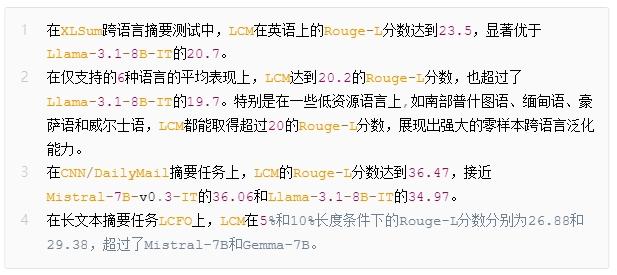
不过在文本扩展任务上,LCM的Rouge-L分数(30.85)低于主流LLM(如Llama-3.1-8B-IT的37.76)。

这是因为,LCM依靠概念训练,其词语表达和想象严格收到SONOR编译器赐予的限制。它能准确表意但表达上会很简单,比如你问CLM"今天去哪玩?" 他的回答很可能是:"去公园散步"。
但你问一个LLM"今天去哪玩?"他的回答就丰富多了:"考虑到今天阳光明媚,可以去城市公园散步,那里有漂亮的花园和儿童游乐设施......" 但从准确性上讲,它是不如CLM的。
而且从推理成本和速度角度看,LCM也有很大优势。相比于同样大小的Llama 2 7B模型,LCM的推理速度大概是它的3、4倍,而成本仅为其一半。
不止LCM,Meta全方位发力潜空间
LCM实际上已经是Meta近期对于“潜空间”展开拓展的第三次尝试了。
BLT:让潜空间还原为字节
12月12号,Meta还发布了一篇备受讨论的论文《Byte Latent Transformer: patches Scale Better Than Tokens》同样是试图打破tokenization的霸权。
不过这一方法并非是向上用概念,而是向下用字节去取代token,作为潜空间的核心表征。
Meta将这一方法称作BLT。

BLT其实与LCM很相似,它通过一个transformer 的轻量级模型对字节进行编组,把它们变成动态的字节包(patchs)。再用这些字节包去训练一个latent Transformer模型。最终依靠另一个解码器把字节包解码成字节序列。
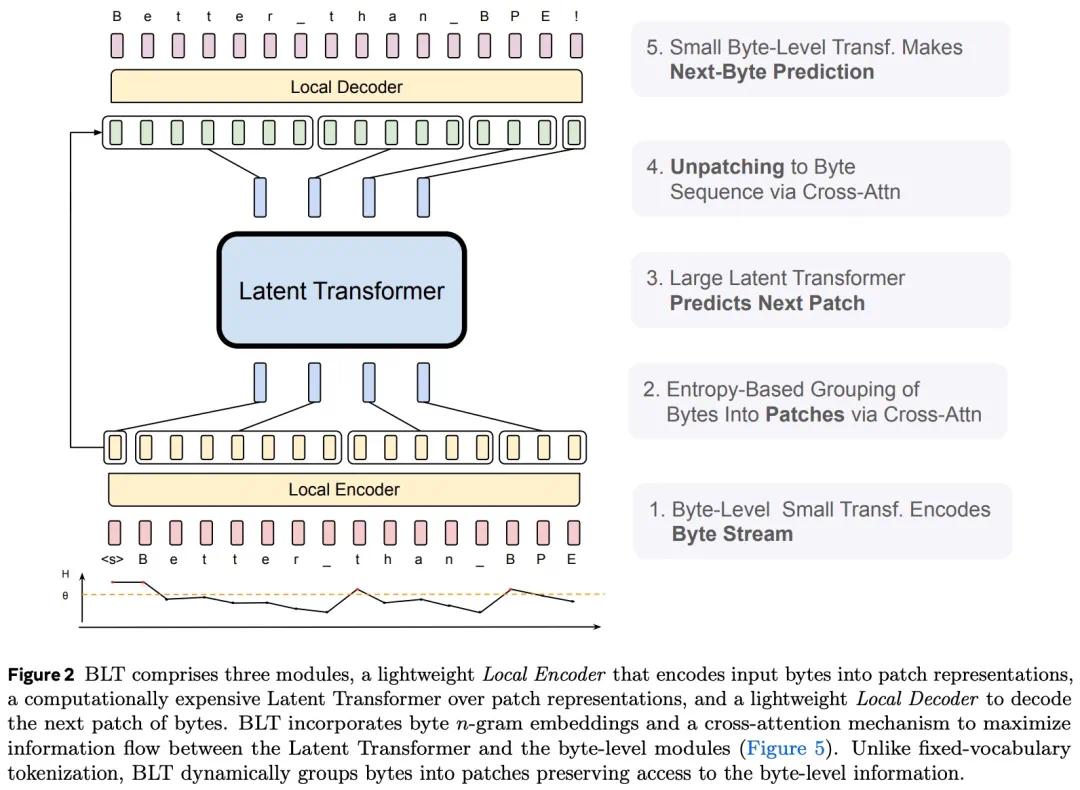
这里从字节转化到字节包的编码器,和LCM中的CONSOR作用几乎完全一致。
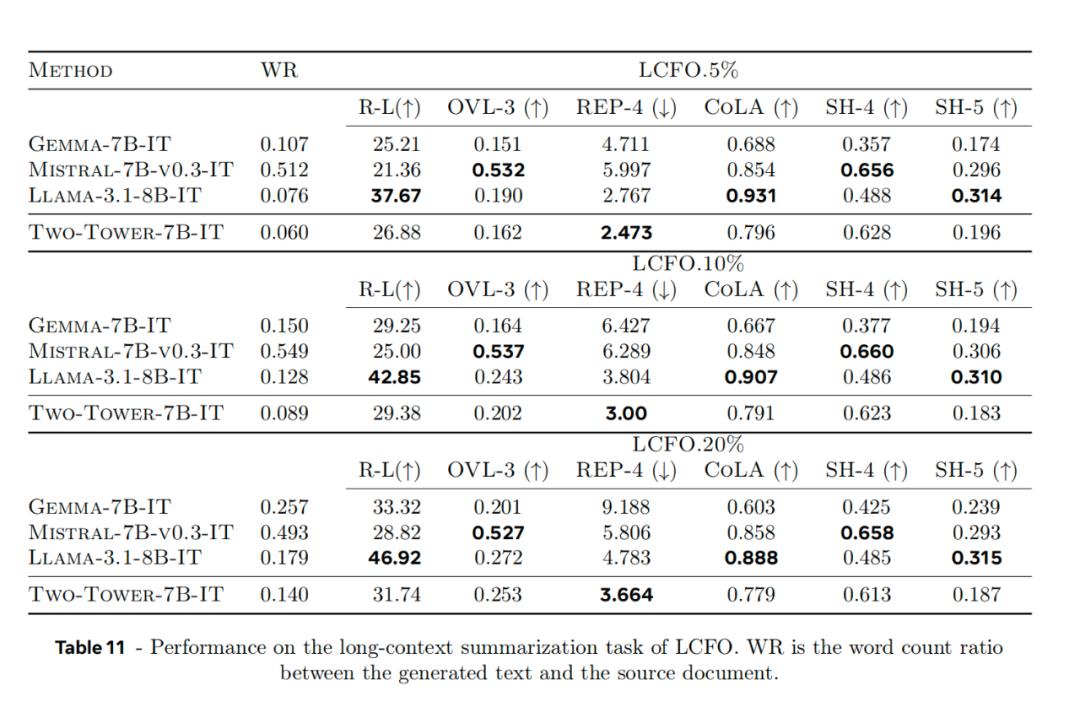
其结果也说明了这条改变token的路径也是可行的。根据论文,BLT-Entropy 模型在 7 项任务中的 4 项上的表现优于 Llama 3 模型。
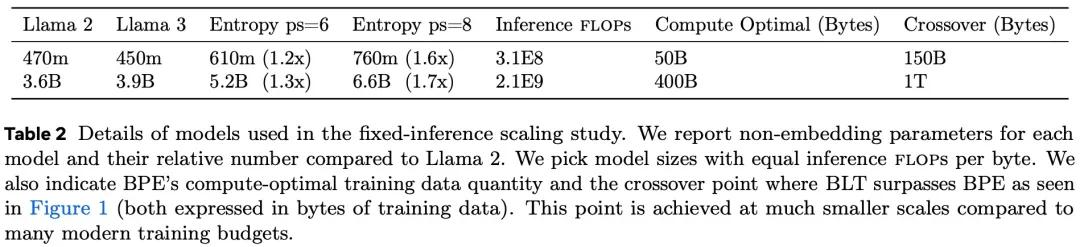
这主要是因为动态 patch 能更好地利用计算量,准确细腻的还原字节间的关系。另外, patch 比 token 本身也更容易扩展,避免了静态token词表的限制。
因为这一项研究的潜力看起来相当大,知名AI研究者Chubby评论说,2025年也许会因此成为Tokenization终结之年。

Cocunut:用想法代替语句去做推理
而在这之前,12月9日,田渊栋带领的团队则试图通过改变潜空间的表达,加强模型的推理能力。

他们采用的是另外一种路径:避免了强制将中间推理过程转换成具体的语言token,而是直接用推理状态(Meta团队称为“想法”)在潜空间里展开思维链推理。
这一方法同样是放弃了token,只不过是限制在思维链这个场景中。
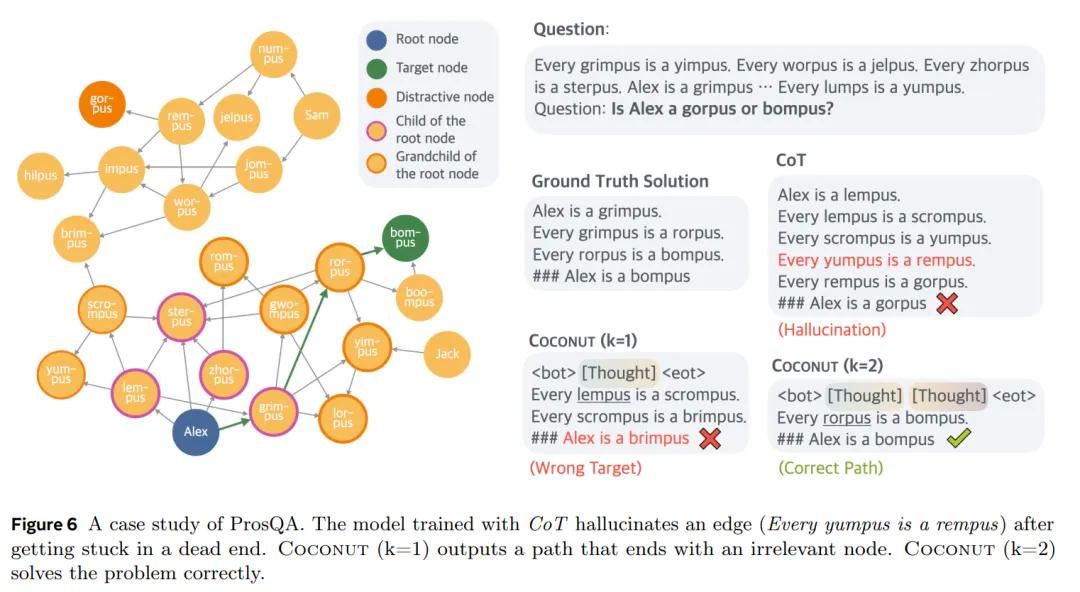
在这个叫Coconut的思维链中,Meta的研究员直接利用最后一个隐藏状态(即“想法”)作为下一个输入嵌入。整个推理过程是连续可微的,可以通过梯度下降来优化。
这就像是让模型在"想法"的空间中直接推理,而不是必须把每一步都转换成具体的语言来表达。

它的逻辑训练方式也一样相对特殊,在前几步训练时,它还是采用一般思维链的方式训练,用话语和token作为要素训练模型,在之后他们逐渐加多“想法”的占比,直到最后完全用“想法”取代token形成的语句。

这一方法有效提高了大语言模型的推理能力,在部分测试项目上甚至高于传统的CoT。

而且通过这一方法,LLM 推理就不光再是链式的,而是一个由最后一个隐藏状态引发的树状搜索序列,可以一次性选择多个潜在节点。更不容易出现由于第一个步骤确定后,无法引向正确节点的幻觉。
一场针对“潜空间”的范式转变
为什么说,Meta最近的研究对于大语言模型界是一场范式变革的开始?
因为不论是token、字节patch、还是概念,他们对应的都是语言模型的潜空间。换一种方法,潜空间的排列就会完全不同。而模型整个的思维表征也就会被由此改变。
潜空间(Latent Space)这个词听起来也许有些玄妙,但它实际上是现代大语言模型的"思维殿堂"。通过潜空间,大语言模型将人类语言中浩如烟海的概念、情感和知识,编织成一张精妙的多维网络。
在这个无形的空间中,词语和概念不再是孤立的个体,而是以一种概率的方式彼此呼应。相关的概念都被放在附近——"狗"和"猫"离得近,因为都是宠物;"开心"和"快乐"挨着,因为意思相近。这些概念之间还能做"计算"。比如"国王-男人+女人=王后"这样的类比关系,AI就是靠这种空间里的"计算"来理解和生成文字的。
而Meta对潜空间的改变,就是在重塑AI的"思考空间"。
比如BLT这种方法对潜空间的改造就让语言模型的理解变得更灵活多变,更接近“概率”的本质。而对于LCM来讲,则是转向让语言模型按更接近人类的概念思维。至于Coconut,让推理在潜空间中进行,给了语言模型更宽广的思路。
这其中LCM的尝试最为大胆:它意图粘合符号主义和连接主义,首次尝试让AI突破词符层面机械的思维方式,转而在语义空间中进行推理和生成。
而这种架构上的革新带来了很多可能性:它为AI系统提供了一种与语言无关的思维方式,使跨语言理解成为其与生俱来的能力;它简化了长篇文本的连贯表达,因为概念之间的关联往往比词符之间的关联更加清晰;更重要的是,它为实现更高层次的抽象推理铺平了道路。
当我们站在2024年的尾声,屡屡听到预训练碰壁之时,也许打破一些过往的常规,才能让AI再次进化。


