

如果对比去年同期,你会发现今年12月是大模型行业的一个热闹峰值。
从11月中旬开始,OpenAI、微软、谷歌、字节跳动、百度和智谱等科技公司都召开了与大模型相关的发布会,推出了一系列新模型、新应用和新产品,其中OpenAI的12天连续直播更是开启了科技公司发布会的新流行。
热闹之下,比起去年技术层和竞争层的种种不确定性,当下模型厂商们的心态和预期好很多。一方面,在技术侧,一场推理AI竞赛已经开打;另一方面,应用层包括AI Agent、搜索等方向也已经明确。
我们整理了12月大模型行业里的五个趋势,记录这个疯狂月份里的兴奋和失落。
1、OpenAI 扣动扳机,开启推理AI竞赛
随着OpenAI相继发布o1和o3模型,一场推理竞赛正在模型厂商间展开。
据OpenAI发布的o3系列时给出的评测数据,在数学、编码、博士级科学问题等复杂问题上的表现,o3均展现出了强大的实力,例如在陶哲轩等60余位全球数学家共同推出的最强数学基准的EpochAI Frontier Math中,o3 创下新纪录,准确率高达25.2%,而其他模型都没有超过2.0%。
而在OpenAI没放出o3前,国内外科技公司的目标无疑是追赶o1,谷歌此前发布全新测试模型Gemini 2.0 Flash Thinking。
今年11月,月之暗面Kimi的新一代数学推理模型k0-math、DeepSeek的推理模型DeepSeek-R1-Lite预览版、阿里云通义的QwQ-32B-Preview也相继发布,在一些数学和编码评估表现中,它们的分数比o1还要高。
但一个问题是,目前尚不清楚o3是否会为普通用户带来很大帮助,从模型能力来看更适合推编码、数学和科学领域的研究人员,除此以外,推理模型也很昂贵。在Keras之父François Chollet发起的ARC-AGI基准测试显示,尽管o3在高计算模式下得分率为 87.5%,但研究人员在该模式下每个任务花费达到数美元,任务成本很高。
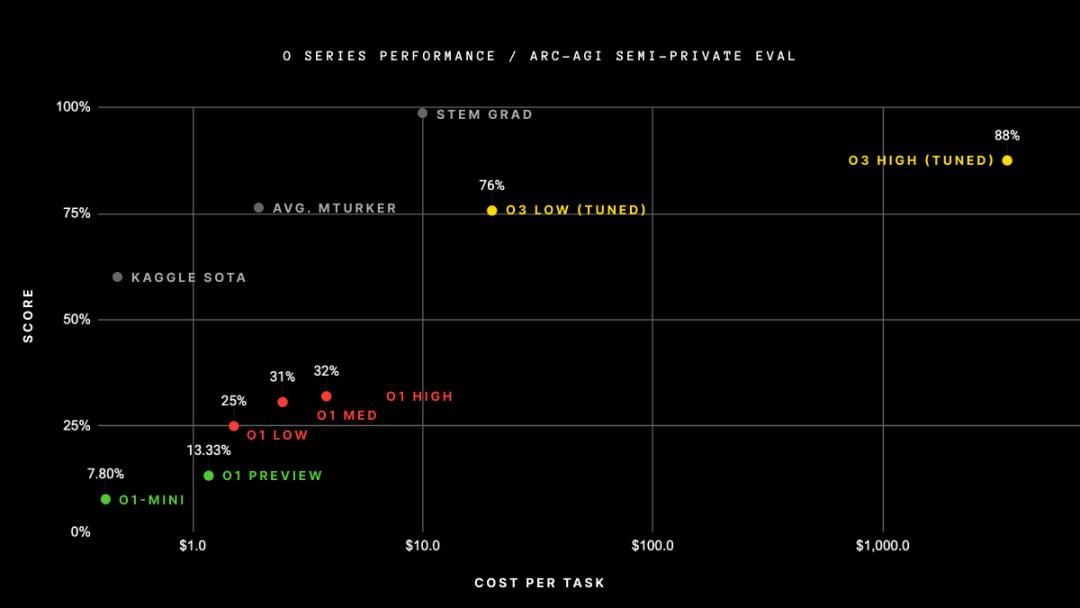
ARC-AGI测试标准 图源:X@arcprize
但成本也只是一个相对的概念。近期,清华NLP实验室刘知远教授团队提出了大模型的密度定律(densing law),该定律表明,大约每过3.3个月(100天),就能用参数量减半的模型达到当前最先进模型的性能水平,这意味未来推理成本还会快速降低。
但至少从技术端来看,至少OpenAI再度验证了Scaling Law没有消失,只不过是从预训练端转向了推理端,通过强化学习和更多的思考时间,提升模型的复杂推理能力,这条路是可行的。
对国内外基础模型厂商而言,它们需要追赶的新目标又出现了。
2、降价还在继续,甚至卷到了「视频模型」
继5月、9月后的两轮大模型「价格战」后,OpenAI和火山引擎(字节跳动旗下云厂商)又掀开了第三轮「价格战」。
在OpenAI第九天的发布会上,针对GPT-4o音频模型,4o音频价格降低了 60%,降至输入40美元/百万tokens、输出80美元/百万tokens,文本价格为输入2.5美元/百万tokens、输出10美元/百万tokens。

OpenAI 12天直播图源:官网
为了讨好开发者,OpenAI还把价格战打到了更有性价比的小模型GPT-4o mini上,音频费用是4o的四分之一。“我们听到了开发者关于成本的反馈,我们正在降低成本”。OpenAI开发者平台负责人Olivier Godement在直播中这样说。
另一边的火山引擎则是把「价格战」带到了视频模型上,其发布的豆包视觉理解模型输入价格为0.003元/每千tokens,比行业平均价格降低85%,火山引擎称将视觉理解模型带入了「厘时代」。
「厘时代」的说法并不陌生,今年5月火山引擎就宣布豆包主力模型将推理输入价格降至「厘时代」,打响大模型推理算力价格战,此后阿里云、百度智能云和腾讯云均迅速跟进,大模型推理算力价格下降了90%以上。

降价并不是国内模型厂商的独有特色,OpenAI也曾多次降价。但区别于国外厂商,国内大模型玩家的特点是:降价幅度更狠,且多为云厂商主导。
降价的原因主要有三:首先,以价换量,以价格带动推理算力消耗量增长,这也是为什么降价主要集中在云厂商的原因。
火山引擎方面,5月豆包通用模型的日均tokens使用量为1200亿,截至12月中旬,日均tokens使用量已超过4万亿,较七个月前首次发布时增长了33倍。百度5月日均Token消耗量是2500亿,截至11月初,百度文心大模型的日均处理Tokens文本数超过1.7万亿,不到半年增长了6.8倍。
其次,随着底层大模型成本、价格的降低,吸引开发者,加速AI进入外部企业,抢占应用生态。
零一万物创始人李开复在近期的一场采访中对比去年和今年的模型价格,这样说:“一年半的时间内,价格差了500倍,同时模型能力还有很大程度的提升。今天如果你还觉得贵,明年99%的概率就不贵了,再过一年可能不但不贵,而且能够支撑你做想要的应用。”
最后,技术本身的优化也带来降本的空间。谭待提到,降价是算法、软件、工程和硬件结合的结果,例如模型结构的优化,在工程手段上,针对不同客户场景集中规模化处理模型调用任务以及采用多种工程化手段,还有通过以异构资源池化的解决方案,提升芯片利用率等。
谭待谈到驱动两次降价的两个内部决策因素,提到两个核心因素,一方面会了解开发者、企业在使用过程中对成本痛点,价格降到多少,他们就能用起来,另一方面,火山引擎也在通过技术优化能把成本打到多低:“这两个值的中间段就是火山引擎可以定下的价格”。
据华泰证券此前预测,降价或还会蔓延,且已呈现出向主力模型降价的趋势。但降价是面子,模型能力才是里子,模型厂商需要回答的核心问题有两个:一是以价换量是否会影响利润表现(国内云厂商这些年均强调利润),二是模型效果是否能真正让客户买单,因为一切竞争的原点都还会回归模型的推理能力上。
3、大模型应用爆发了,但「能用」到「好用」间还有鸿沟
计算成本的下降和基础模型选项的增加,让大模型应用层进入了一个飞速发展的时期,风险投资公司Lerer Hippeau管理合伙人Ben Lerer甚至这样说:
“如果你是一家初创公司,你可以选择当下流行的方案,不仅仅是做ChatGPT包装器、Claude包装器、Gemini包装器,或者随便什么,你可以将所有这些包装器组合起来,以优化功能、结果和这些结果的成本。”
「套壳与否」已经不再成为市场关注的重点,国外应用层玩家的「通用大模型套垂直小模型」的「鸡尾酒打法」也已复制到中国。
以国内AI玩具厂商跃然创新为例,创始人李勇就提到,在通用大模型上和MiniMax、豆包、智谱均有合作,“各家效果都挺好,儿童场景也够用”,现阶段使用MiniMax比较多是因为“给了跃然创新早期用户很多免费tokens”。
比起外界对「何时出现杀手级应用」的追问,各家厂商有自己的判断,此前字节管理层判断AI对话类产品可能只是AI产品的「中间态」,而百度创始人李彦宏则对外反复谈到,Agent是他最看好的AI应用发展方向。
整个12月,大模型玩家们围绕应用层的探索形成了「2+X」的确定性方向,其中「2」指的是AI Agent(智能代理)和AI搜索,而「X」则是包括AI玩具、AI耳机、AI眼镜等诸多AI软/硬件产品。
在AI搜索上,姗姗来迟的OpenAI终于在12天直播中宣布在ChatGPT新增了搜索功能,而据外媒报道,谷歌在推出AI Overviews后,近期也在考虑在Chrome浏览器中增加「AI模式」选项。而在不久前,AI搜索领域的巨头Perplexity AI也完成了新一轮5亿美元的融资,估值已升至90亿美元。

搜索这块「旧蛋糕」一直是大模型应用的必争之地,如今战火更盛的原因一是大模型推理技术能力的提升,二是对商业化的迫切需求让玩家们加大了对搜索这一「离钱更近」场景的争夺。
而与AI搜索关系「暧昧」的AI Agent也在12月成为最火的应用落地方向。
Anthropic推出的Computer Use功能和智谱近期发布的AutoGLM都展示了端侧Agent的交互性、自动化和主动性等特点,国内外科技大厂也几乎都有自己的 Agent平台。
在科技企业的各种演示中,AI Agent似乎已经能融入用户的工作和生活,不仅在手机端能执行预定酒店、点外卖等指令,还可以成为用户的工作助理,智谱AI CEO张鹏将AI Agent比作大模型通用操作系统LLM-OS的雏形,它的潜力在于大模型公司可以以此搭建自己的生态圈,在手机、PC等端侧找到落地的入口。

“(AI Agent)实现大模型的互联互通,理论是没有边界的”。张鹏表示。
但也请对科技公司的理想保持冷静。现阶段,他们尚未解决的问题还有很多。比如商业模式,在C端,智能体目前尚没有形成新的商业模式,依旧靠高流量带来的付费转化,百度、字节等大厂的智能体还需要靠自己已有的流量阵地完成分发。
而在B端,红杉在近期一份报道中指出,随着代理(Agent)应用很快变得更加复杂,对于任何给定的领域,收集现实世界的数据、编码领域和应用特定的认知架构也将成为更多玩家摆在眼前的挑战。
当然,在「X」上也涌现出更多的尝试。除了我们已熟悉的AI手机、AI PC外,红极一时的AI Pin不见了,新的风口属于AI玩具和AI耳机。
字节的显眼包,已经开卖的AI毛绒玩具,究竟是风口,还是刚需,销量和复购数字会给出答案。
一句话总结,在强调「应用优先」的共识里,从能用到好用,还有许多鸿沟。
4、资金大分裂继续,穷人富人已经出现
热闹的年终发布月里,久违的大模型融资热又来了。
上个月底,在OpenAI和Anthropic完成新一笔融资后,据我们不完全统计,12月初,又一批国内外的明星AI企业们拿到了「过冬钱」。
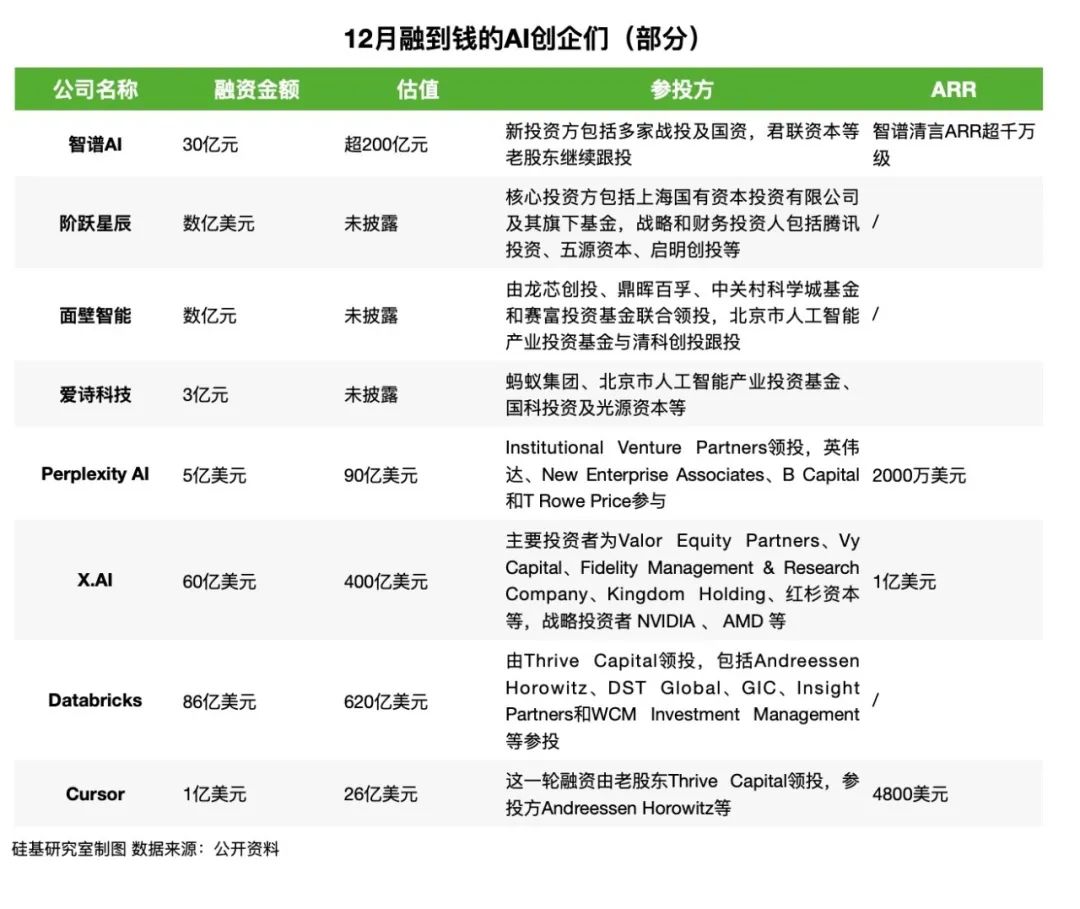
国内大模型企业中,面壁智能、智谱AI、阶跃星辰完成新一轮融资,至此也将国内基座大模型的估值抬升至200亿元门槛,随着单笔融资的提升,我们发现接住国内大模型公司已经变成了老股东、国资和科技大厂。
国外企业中,模型层、应用层和几基座层均有新融资出现,Perplexity AI、X.AI、Databricks、Cursor等公司都拿到了新一笔钱。
拿到钱该如何分配,是这些公司下一步的重点,加码技术研发和基础设施建设还是主线。X.AI在本次融资公告中就提到,主要用途预计是采购另外10万块英伟达 GPU,以进一步扩充其算力规模。
融资的牌桌上,有富人,就有穷人。风险机构Northzone合伙人Molly Alter预测:“「最诱人」的交易将继续以极高的估值进行,但对于其他公司而言,则需要展示非常具体的指标才能获得高估值。「富人」和「穷人」将出现巨大的分化。”
分化的结果将是,我们会看见,寻求退场或倒闭的初创公司会增加,大型科技公司和头部企业的整合速度也会加快。
如Perplexity AI在本月收购了一家名为Carbon的小型初创公司,Cursor背后的开发商Anysphere也将另一款AI编码助手Supermaven收入囊中。
「The information」此前曾提出,衡量那些短期内不太可能被收购的公司主要有以下几点因素:收入和利润、增长、员工人数、筹集的总资金以及公司是否从可能成为收购者的战略投资者那里筹集了大量资金。
5、回流与出走,所有人都面临“人”的问题
人、钱、事,是所有公司的三要素,而在大模型行业,人又是最关键的因素。
围绕大模型组织的整合、人才的回流和出走,成了年末的焦点话题。
此前我们在《大模型狂飙两年后,“六小龙”开始做减法》曾报道过,大模型「六小龙」中已经不断有人员离开,他们离职的方向包括但不限于——回流大厂、再创业。
而再创业的方向基本也和AI相关,零一万物前联潘欣在近期以闪极AI合伙人身份投身AI眼镜浪潮,月之暗面前产品负责人王冠的新创业项目ONE2X也在11月完成天使轮融资。
而「人」也是过去一年里OpenAI头疼的问题。不久前,「GPT之父」Alec RadfordAlec Radford也宣布从OpenAI离开,宣布将开启自己独立研究生涯。搜索负责人Shivakumar Venkataraman也在加入公司七个月后离职,他领导了OpenAI企业客户的搜索和人工智能的开发。
类似的整合也出现在大厂内部,它们需要以更灵活的姿态应对竞争。此前据《智能涌现》报道,阿里旗下的AI应用「通义」也从阿里云分拆,并入阿里智能信息事业群。
可以肯定的是,随着竞争激烈,组织和人才整合和分化不会停止。
时间拨回去年12月,在经历了内斗动荡后,重回管理层的Sam Altman或许不会想到,此刻的OpenAI已经历了一轮人才的大换血。
一年前,人们讨论的话题是创业公司和大厂间的竞争,技术上聚焦长文本窗口,流行大模型是一把手工程,一年过去,这些话题还在讨论,但有些问题已经随技术更迭成为共识。
即便人们对AI依旧怀疑,但它确实已走入人们的生活,这个趋势将无法阻挡,正如Sam Altman在12天直播发布会后所说的那样:
“You can just do things。”


