

【导读】李飞飞、谢赛宁团队又有重磅发现了:多模态LLM能够记住和回忆空间,甚至内部已经形成了局部世界模型,表现了空间意识!李飞飞兴奋表示,在2025年,空间智能的界限很可能会再次突破。
就在刚刚,李飞飞、谢赛宁等发现:多模态大语言模型居然能记住和回忆空间。
更震撼的是,MLLM的空间推理能力虽然仍是瓶颈,但这些模型中,已经出现了局部世界模型和空间意识的迹象!

论文地址:https://arxiv.org/abs/2412.14171
共同一作:Jihan Yang,Shusheng Yang,Anjali W. Gupta,Rilyn Han
李飞飞表示,非常喜欢这项「空间思维」(Thinking in Space)的研究。空间推理对于人类智能来说,至关重要。在2025年,空间智能的界限很可能会再被突破。
谢赛宁也表示,大家和李飞飞进行的关于空间智能的有趣头脑风暴,已经发展成了NYU、耶鲁和斯坦福之间的惊人合作。
他们相信,视觉空间智能在现实世界中的应用,比以往任何时候都更近了。比如AI眼镜,它可以向我们显示去过的地方,还能定位、导航。
因此,这个领域实在太令人着迷了。
前不久Ilya曾说,预训练结束了,数据如同化石燃料般难以再生,但不少研究者出来反驳说,人类只是用完了文本,海量的视频还在眼前。
此时李飞飞和谢赛宁的研究,可谓相当应景了。
更巧的是,就在不久前,谢赛宁还和LeCun等人合作完成了一项MetaMorph的工作。他们发现:LLM离理解和生成视觉内容已经不远了。
这些测试,大模型被人类完败

在项目主页一开始,团队就放出了非常有趣的人类AI大pk。
内容就是,和Gemini来比拼空间智能能力。

- 相对方向
比如这道题是,「如果我站在冰箱旁,正对着洗衣机,那么炉子是在左边、右边,还是在后面?」
备选答案是:A. 后面 B.右边 C.左边
Gemini 1.5 Pro给出了错误答案:左边。

- 相对距离
问题:从每个物体的最近点测量,这些物体(桌子、凳子、沙发、炉子)中哪一个距离电视最近?
正确答案是桌子,模型回答的却是沙发。

- 绝对距离
从每个物体的最近点测量,桌子和钢琴之间的距离是多少?
正确答案是2.3米,但模型回答的是0.1米。

- 房间面积
这道题问的是房间面积多少平米。
正确答案是29,但Gemini 1.5-Pro回答的是50。

- 数数
这道题问的是,房间里有几把椅子?
正确答案是3把,但Gemini 1.5-Pro却只数出2把。

- 出现顺序
问题:视频中以下类别(毯子、垃圾桶、微波炉、植物)的首次出现顺序是什么?
模型依然数错了顺序。

总之,在这些pk中,模型被人类完爆。
多模态大模型已经展现出空间思维
毫无疑问,视频理解就是下一个前沿领域,然而,并非所有视频都是相似的。
现在,模型还可以根据YouTube剪辑和故事片进行推理,但对于日常生活中的空间,我们以及未来的AI助手能够作何应对呢?
为此,谢赛宁团队进行了一项最新研究,探索多模态大语言模型(MLLM)如何感知、记忆和回忆空间的。


在视觉领域,我们人类能够处理空间,却很少进行推理;而多模态大语言模型则善于思考,却往往忽略了空间逻辑。
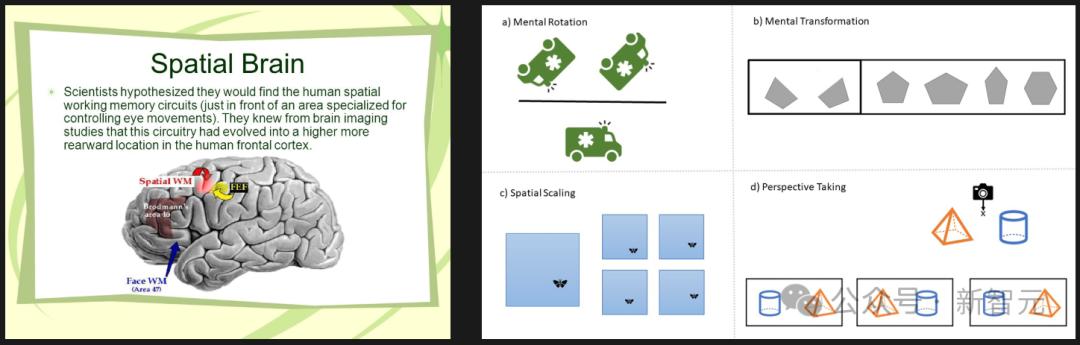
然而,对于人类来说,无论是参加心理旋转测试,还是为新家挑选家具,我们都极度依赖于空间和视觉思维,而这种思维方式,却并不总能很好地转化为文字。

视频是一种自然媒介,反映了我们体验世界的方式,并且需要更长形式的推理,以及世界建模。
为了探索这一点,团队研究了涵盖各种视觉空间智能任务(包括关系和度量任务)的新基准。
所以,这个过程是如何获取数据和注释的呢?团队在之前CV工作的基础上,重新利用了已有的空间扫描视频(起初是用于3D重建),使用其真实注释来自动生成VQA问题。
同时,人类仍然参与其中,进行质量控制。

超过5000个问答对显示,MLLM居然展现出了具有竞争力的视觉空间智能!
其中,Gemini Pro的表现最为亮眼。
当然,它们仍然和人类存在差距。
这些任务对人类而言也并非易事(毕竟,我们自己也经常迷路),不过,人类会通过调整和优化自己的心智模型来适应,而目前的LLM,暂时还无法做到这一点。
谢赛宁表示,自己在研究中最喜欢的部分,就是分析这些任务跟以语言为中心的智能有多么不同。
当被要求解释自己的推理过程时,LLM就暴露出了自己的弱点:空间推理是它们的主要瓶颈,而非物体识别或语言能力。
在换位思考、第一到客观视角的转变上,它们通常表现得极其困难,并且在更长时间的推理过程中,容易失去对物体的追踪。

团队的另一个发现是,语言提示技术在这一领域并不奏效——像CoT或多数投票等方法,居然对任务产生了负面影响!
然而,这些技术在一般的视频分析任务(如VideoMME)中,却是很有效的。
这就再次突显出一个重要区别:并非所有视频都是相同的,理解电影情节这样的任务更多依赖于基于语言的智能,而非视觉空间智能。
而最后这个结论,就更震撼了。
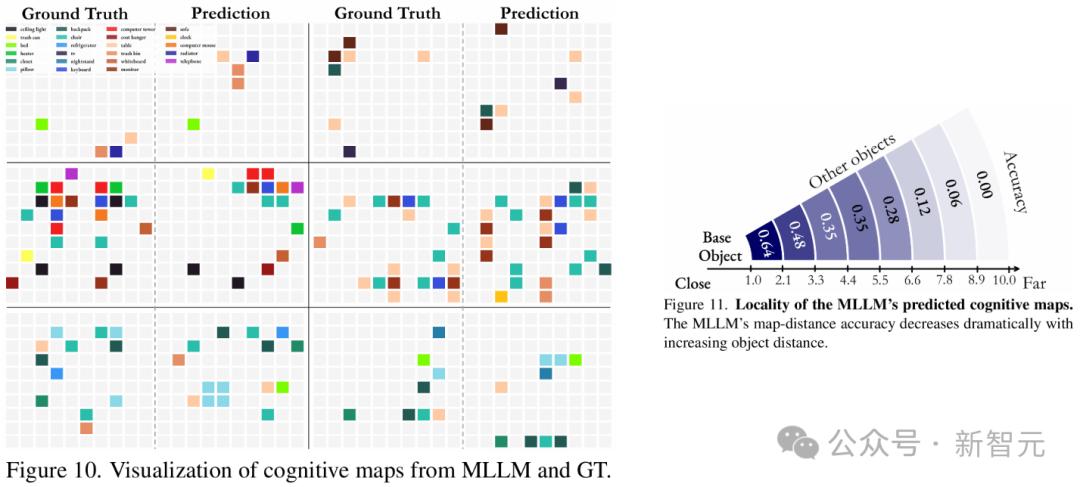
团队通过提示模型在笛卡尔网格上「可视化」其记忆,来探测它的能力,其中每个被占据的单元格代表一个物体的中心。
研究结果表明,在处理空间信息时,MLLM并不是构建一个连贯的全局模型,而是从给定的视频中生成一系列局部化的世界模型。
但问题涉及相距较远的对象时,模型的性能会迅速下降,此时这种限制尤为明显。
这些观察表明,该领域未来研究的一个关键方向,就是开发更有效的空间记忆机制。
网友表示,这项关于「空间思维」的见解实在太精彩了。提高MLLM的视觉空间智能,可能会彻底改变AI助手。AI在日常空间中的未来,实在令人兴奋。

有人说,从基于主观事实的模型中提取客观事实,看起来比LLM跟特斯拉FSD相结合更具挑战性,因为后者已经推理出了客观事实。

不过也有人说,视频理解的确是下一个前沿,但MLLM恐怕无法真正代表人类智能理解动态视觉信息的方式。
项目介绍
研究者想探讨的问题就是,当MLLM看视频时,它们是否在进行「空间思维」呢?
它们能否构建一个准确的、隐含的「认知地图」,来回答关于空间的问题?
使用MLLM增强空间智能,有哪些优势和局限性?

为此,研究者为MLLM准备了可供观看的视频数据,建立了视觉问答(VQA)基准,来探索它们在此过程中究竟实际记住和理解了什么。
他们开发了一个新颖的视频视觉-空间智能基准(VSI-Bench),包含超过5,000对问答对,发现MLLM虽有竞争力,但仍低于人类水平的视觉-空间智能。
为了更好地理解其行为,研究者探索了MLLM是如何从语言和视觉两个方面来表达空间思维的。
可以发现,尽管空间推理能力仍是其主要瓶颈,但MLLM已经逐渐显现出了局部世界模型和空间意识。
VSI-Bench
研究者开发了VSI-Bench,这是一个基准测试,用于通过超过5,000对问答对,来评估MLLM的视觉-空间智能。
这些问答对来源于公共室内3D场景重建数据集ScanNet、ScanNet++和ARKitScenes验证集中的288段第一视角视频。
VSI-Bench包含八项任务,分为三种任务类型:配置类、测量估算类和时空类。
图2显示了有关VSI-Bench任务的概览;图3显示了有关数据集的统计信息。

图2 VSI-Bench的任务演示
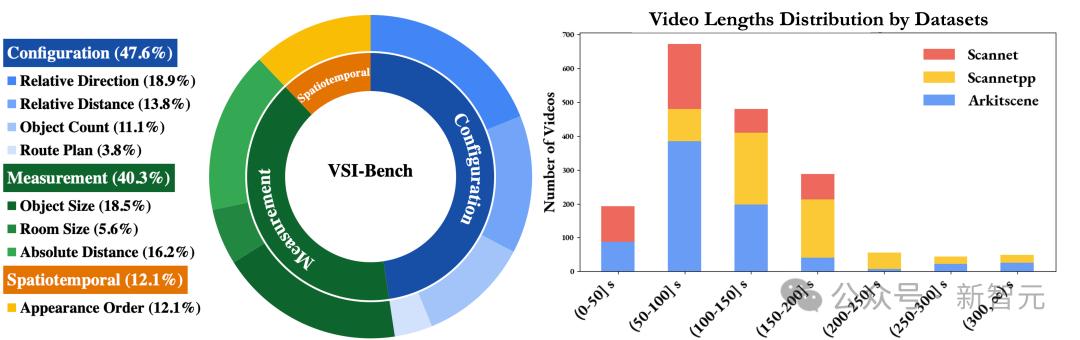
图3 基准统计信息。左:三大类任务的分布;右:视频长度统计
通过迭代优化提升质量,VSI-Bench为研究MLLM与3D重建之间的联系奠定了基础。
研究者开发了一套稳健的流水线来构建VSI-Bench,以支持大规模生成高质量的问答对。
从数据收集与统一化开始,他们将多样化的3D室内场景数据集标准化为统一的元信息格式,整合对象类别、边界框和视频规格,以支持与数据集无关的问答生成。
问答对通过从元信息中自动注释和基于任务的问题模板生成,其中路径规划任务由人工注释完成。
为确保质量,研究者审查流程由人类参与,通过解决评估者标记的歧义和错误,对问题模板、注释和问答生成规则进行迭代优化。
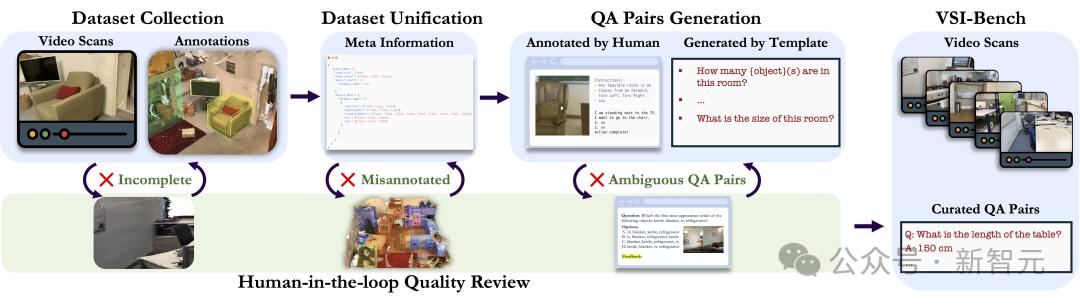
图4 基准策划流水线。该流水线将数据集统一为标准化格式和语义空间,以确保一致性处理
VSI-Bench评估
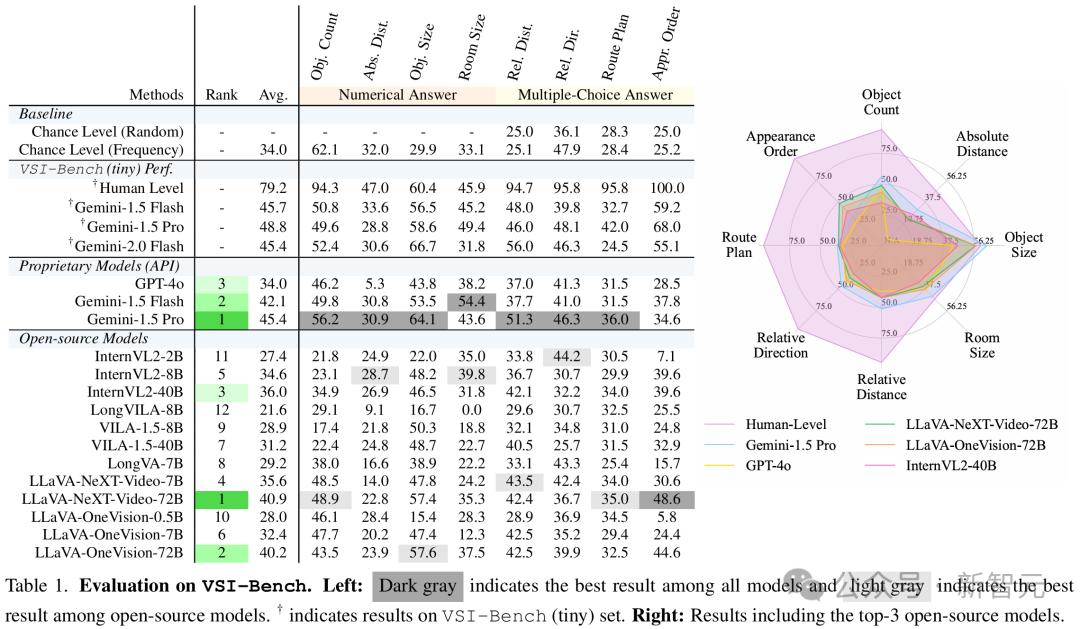
研究者对来自不同模型家族的15种支持视频的MLLM进行了基准测试。
闭源模型中,他们评估了Gemini-1.5和GPT-4o。开源模型中,他们评估了InternVL2、ViLA、LongViLA、LongVA、LLaVA-OneVision和LLaVA-NeXT-Video的模型。
所有评估均在零样本学习设置下进行,使用默认提示词和贪婪解码,以确保结果可复现。
任务采用多选答案(MCA)准确率,或研究者提出的数值答案(NA)任务的平均相对准确率(MRA),来进行评估。

基线包括随机选择和基于频率的选项选择,以识别因分布偏差带来的性能提升。
此外,他们还在随机抽样的400个问题子集(VSI-Bench tiny)上评估了人类的表现,并与Gemini-1.5 Pro进行了比较。
- 结果
结果显示,人类评估者的平均准确率达到了79%,比最佳模型高出33%,在配置类和时空类任务上表现接近完美(94%-100%)。
然而,在需要精确估算的测量任务上,这一差距却缩小了,MLLM在定量任务中表现出相对优势。
在闭源模型中,Gemini-1.5 Pro的表现突出,显著超越随机基线,并在绝对距离和房间大小估算等任务中接近人类水平,尽管它仅仅接受过2D数字数据的训练。
表现最好的开源模型如LLaVA-NeXT-Video-72B和LLaVA-OneVision-72B的表现也很亮眼,仅仅比Gemini-1.5 Pro低4%-5%。
然而,大多数开源模型(12个中的7个)都低于随机基线,暴露出在视觉-空间智能方面的巨大缺陷。
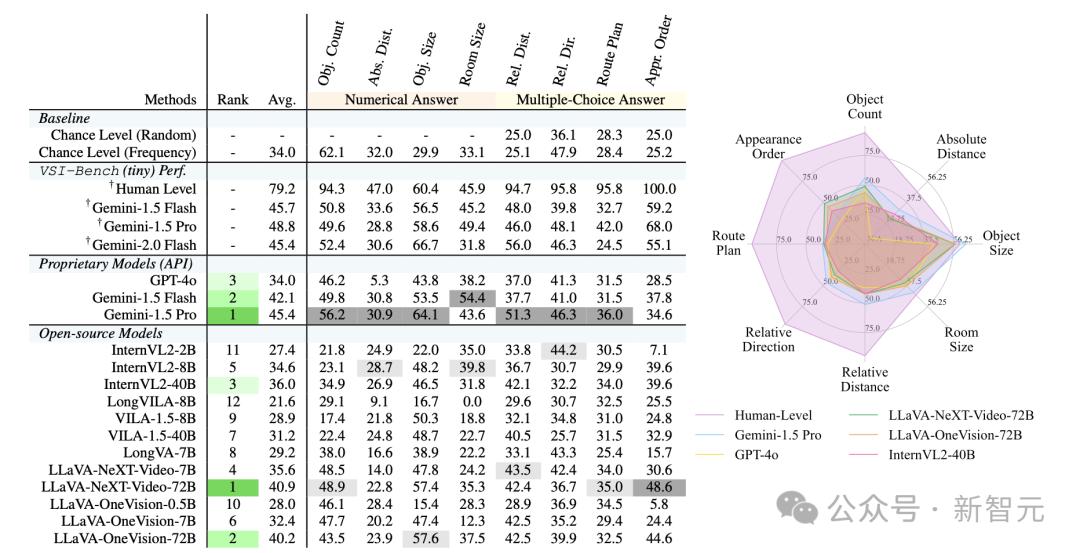
表1 VSI-Bench的评估结果。左:深灰色表示所有模型中最佳结果,浅灰色表示开源模型中的最佳结果;右:人类、两个闭源模型以及Top 3开源模型的结果
- 盲测
研究者将MLLM的表现与「随机水平(基于频率)」和「禁用视觉模式」结果进行了比较,对六个顶级模型(三个开源模型和三个闭源模型)进行了平均。
在「启用-禁用」模式下的一致改进以及「禁用-随机」模式下的普遍退化,凸显了视频输入对VSI-Bench的重要性,因为禁用视觉模式的模型表现低于随机水平。
然而,MLLM在绝对距离估算、路径规划和相对方向等任务上难以超越随机水平,这反映了这些任务的固有难度。
有趣的是,禁用视觉模式的模型在物体大小任务上显著优于随机水平,这可能是因为语言模型训练中已经整合进了常识知识。
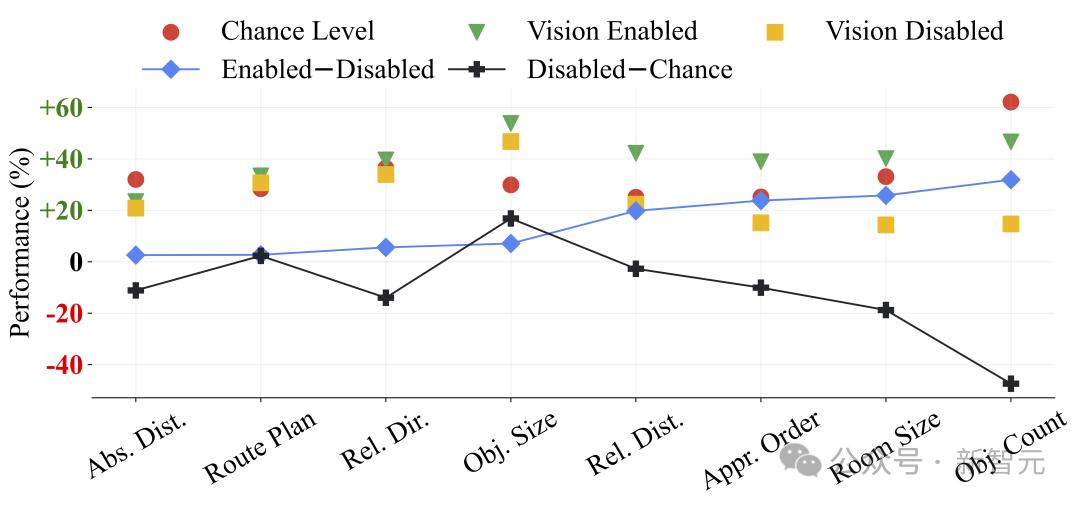
图5 视觉启用(有视频)、禁用视觉模式(无视频)和随机水平(基于频率)之间的比较
在空间中,MLLM如何以语言思考
为了更好地理解模型何时以及为何会成功或失败,并阐明它们所具备的视觉-空间智能的各个方面,团队研究了MLLM如何在空间中以语言进行思考。
在成功的示例中,模型展示了高级的视频理解能力,提供了准确的时间戳描述和正确的逐步推理过程。
全局坐标系的使用表明,MLLM可能通过整合空间上下文和推理,构建了出了一些隐式世界模型。
在错误的案例中,模型在第一与客观视角之间的转换中失败了。由于依赖第一视角错误地解读了视频序列,从而导致了错误的空间推理。

图6 MLLM在自我解释中展示了自己是如何思考的
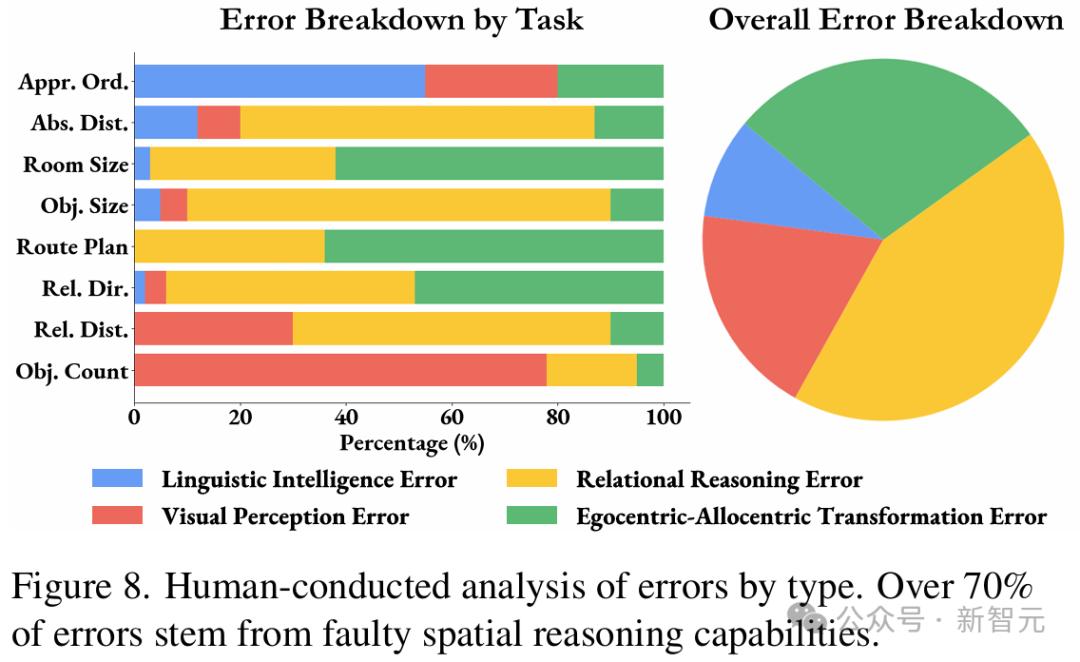
- 错误分析
对在VSI-Bench tiny上表现最好的MLLM的错误分析显示,主要存在四种错误类型:视觉感知、语言智能、关系推理,以及第一与客观视角之间的转换。
图7显示,71%的错误源于空间推理,特别是在理解距离、大小和方向等方面。
这表明,空间推理仍然是提升MLLM在VSI-Bench上表现的关键瓶颈。
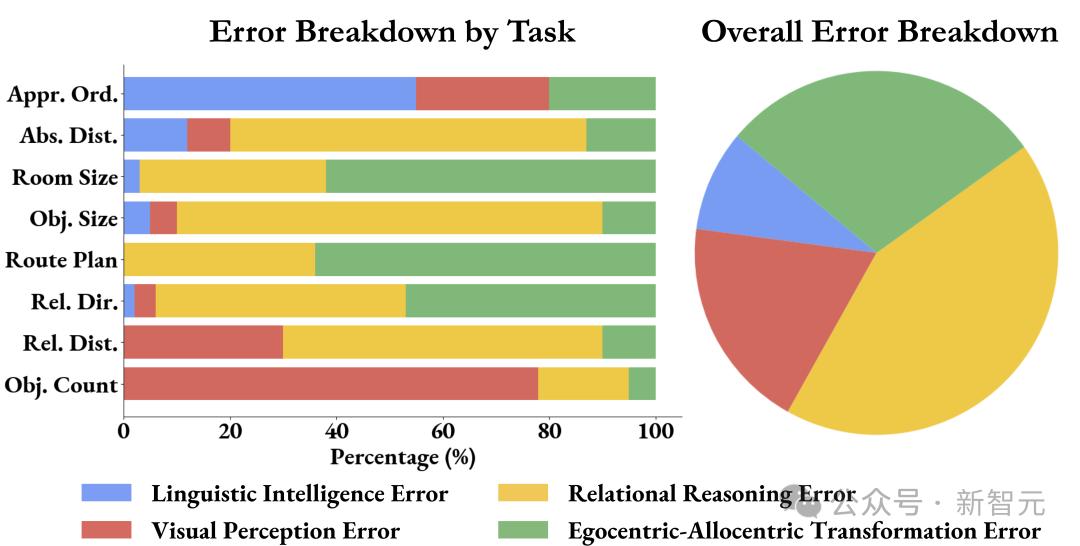
图7 按类型进行的人类错误分析
发现 1:空间推理是MLLM在VSI-Bench上表现的主要瓶颈
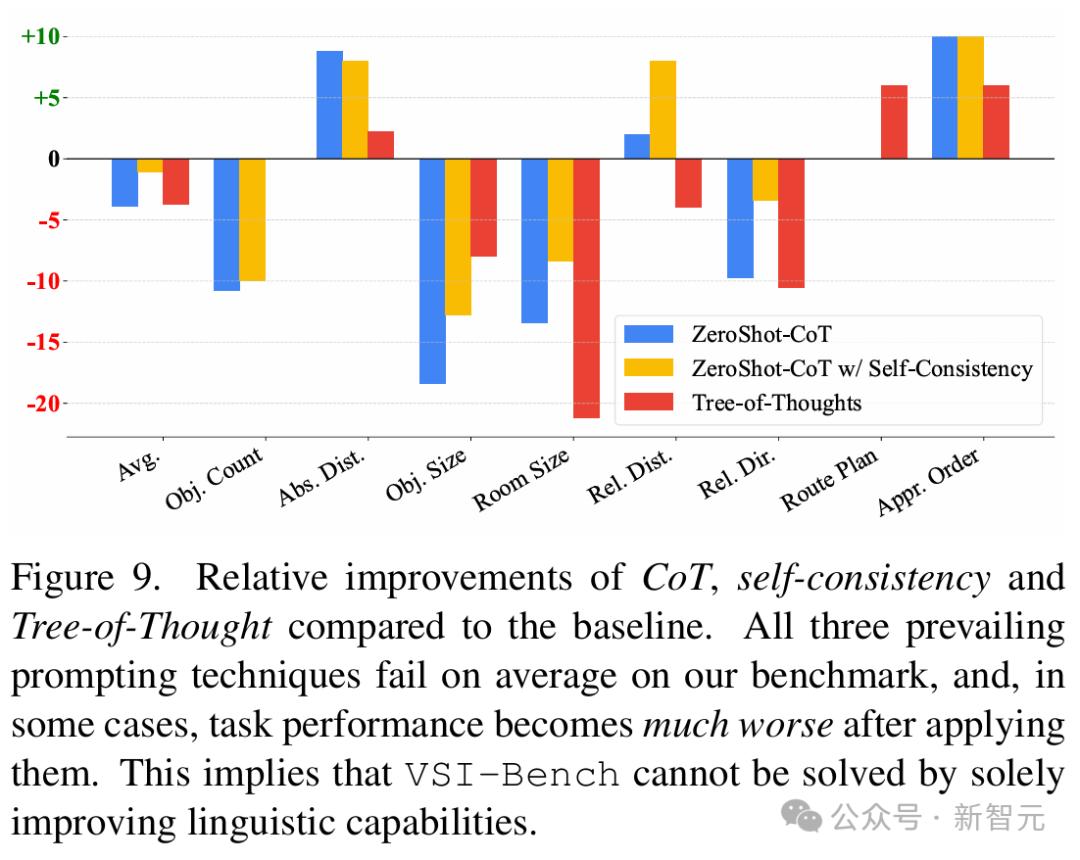
- CoT方法在视觉空间任务中的局限性
团队研究了三种提示词技术——零样本CoT(Zero-Shot CoT)、带自洽性的CoT(Self-Consistency with CoT)以及思维树(ToT),以改进MLLM在VSI-Bench上的推理能力。
令人惊讶的是,这三种方法都导致了性能下降(见图 8),其中零样本CoT和ToT使平均性能下降了4%,而带自洽性的CoT则比基线低了1.1%。
尽管在任务顺序和绝对距离估算任务中,由于语言错误的减少而略有改善,但房间大小和物体大小任务的性能却大幅下降了8%至21%,表明鼓励模型进行更多推理不仅不可靠,甚至可能有害。
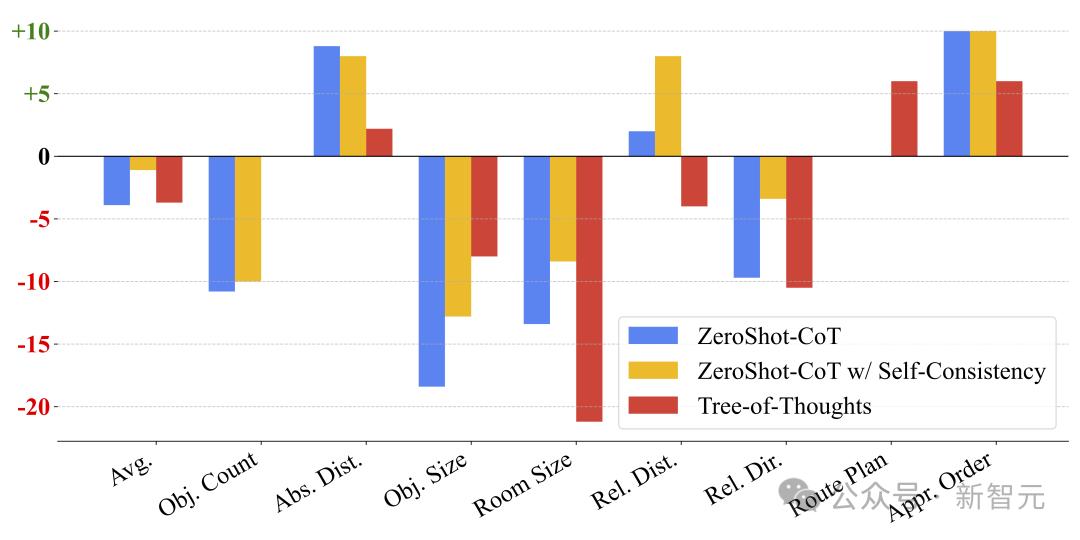
图8 CoT、自洽性和思维树相较于基线的相对改进
同时,如表2所示,零样本CoT在通用视频理解基准VideoMME上,实现了1.6%的性能提升。

表2 Gemini-1.5 Pro在VideoMME的500个问题子集上的CoT表现
发现2:尽管语言提示技术在语言推理和通用视觉任务中有效,但对空间推理而言往往有害。
在视觉上,MLLM如何思考空间
人类在进行空间推理时,会下意识地构建空间的心理模型。
那MLLM是如何记忆空间的呢?
- 通过认知地图进行探测
团队通过提示Gemini-1.5 Pro基于视频输入,预测10×10网格中物体中心位置的表现,评估了MLLM创建认知地图(一种空间表征框架)的能力。
测量准确性,靠的是比较预测的物体距离与真实值(GT)地图的偏差,偏差在一个网格单位以内的,都被视为正确。
结果显示,模型在定位近距离物体时达到了64%的准确率,展示了强大的局部空间感知能力。
然而,当距离变得较大时,模型就显得困难重重了,这也反映出模型从离散的视频帧中构建全局空间模型表征的挑战。
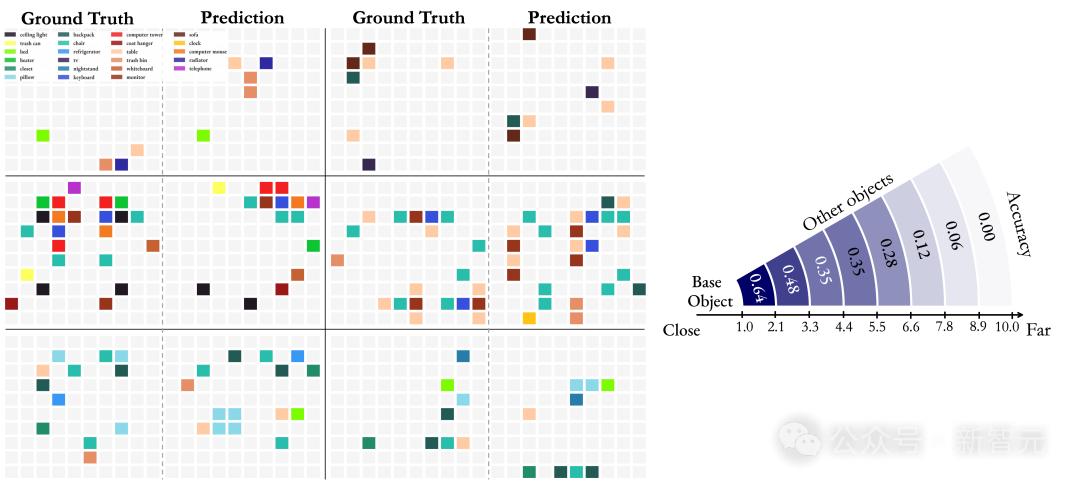
图9 左:MLLM和真实值(GT)认知地图的可视化。右:MLLM预测的认知地图的局部性
发现 3:在记忆空间时,MLLM从给定视频中在其「脑海中」形成一系列局部世界模型,而非统一的全局模型
- 通过认知地图改进距离推理
团队通过提示Gemini-1.5 Pro从视频输入生成地图并使用其回答相对距离问题,探索了认知地图是否可以增强MLLM的空间推理能力。
结果显示,使用模型自身生成的地图,准确率提升了10%;使用真实值(GT)地图,准确率提升了20%-32%,这突显了准确的心理图像在强化全局场景拓扑中的价值。
这表明,认知映射是一种改进MLLM视觉-空间推理的极有前景的方法。
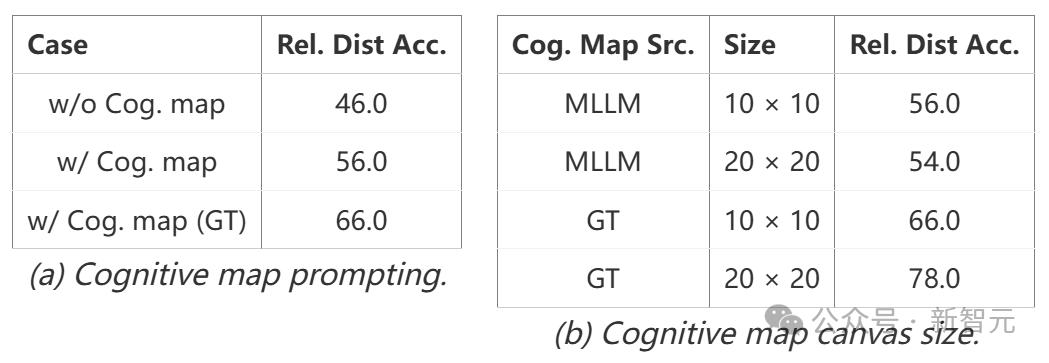
表3 基于认知地图的相对距离任务分析
LLM距离「既能理解,又能生成」视觉内容,还有多远?
无独有偶,谢赛宁和LeCun的团队,前不久还刚刚提出了一种全新的多模态理解与生成模型——MetaMorph。
简单来说,当与视觉理解任务联合训练时,仅需极少量的生成数据即可激发LLM的视觉生成能力。

论文地址:https://arxiv.org/abs/2412.14164
通讯作者:Shengbang Tong,Zhuang Liu
在这项工作中,团队将视觉指令微调扩展成了视觉预测指令微调(VPiT)——让LLM可以对视觉和文本token进行预测,而无需对模型架构进行大幅修改或进行额外的预训练。
其中,关键发现有三点:
1.生成和理解是相辅相成的。实验结果显示,随着模型理解能力的提升,视觉生成也会自然涌现——在联合训练的情况下,仅需要200K个样本即可实现,而传统方法通常需要数百万样本。
2. 视觉预测指令微调(VPiT)将现有的指令微调进行了扩展,使其能够同时预测连续的视觉token和离散的文本token。如此一来,便可在保持指令微调高效性的同时,显著增强模型的多模态能力。
3. 经过VPiT训练后的模型,展现出了一种「模态统一」的有趣现象——模型不仅能够利用大语言模型的知识进行生成,还能在生成视觉token之前进行隐式推理推理。
LLM距离成为「统一模型」已经非常接近了!
参考资料:
https://x.com/sainingxie/status/1870877202595958791
https://vision-x-nyu.github.io/thinking-in-space.github.io/
https://x.com/TongPetersb/status/1869590175195558132
