

AI革命正在耗尽数据 研究人员能做些什么?
2 周前
/ 阅读约2分钟
来源:cnBeta
互联网是人类知识的浩瀚宝库,但它并非取之不尽。人工智能(AI)研究人员正在迅速耗尽其中的资源。过去十年,AI领域的飞速发展在很大程度上得益于神经网络的扩展以及它们在海量数据上的训练。这种方法在开发大型语言模型(LLM)方面非常有效,例如驱动聊天机器人ChatGPT的模型。然而,一些专家警告称,这种规模扩展正接近极限。除了不断增长的计算能源需求,另一个原因是LLM开发者正在耗尽传统数据集。
互联网是人类知识的浩瀚宝库,但它并非取之不尽。人工智能(AI)研究人员正在迅速耗尽其中的资源。过去十年,AI领域的飞速发展在很大程度上得益于神经网络的扩展以及它们在海量数据上的训练。这种方法在开发大型语言模型(LLM)方面非常有效,例如驱动聊天机器人ChatGPT的模型。然而,一些专家警告称,这种规模扩展正接近极限。除了不断增长的计算能源需求,另一个原因是LLM开发者正在耗尽传统数据集。
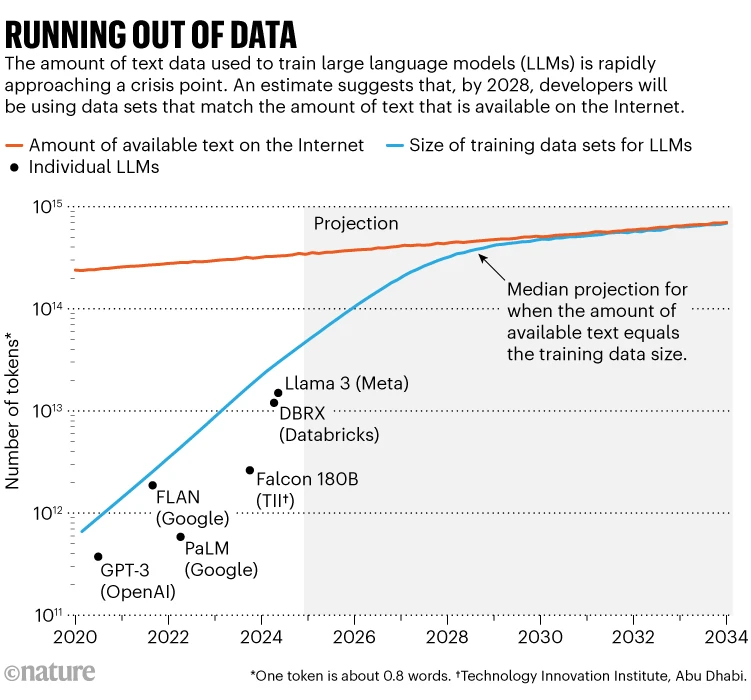
最近,一项引人注目的研究对此问题进行了量化分析,引发了广泛关注。虚拟研究机构Epoch AI的研究人员预测,到2028年左右,用于训练AI模型的典型数据集规模将接近互联网可公开获取文本的总量。换句话说,AI可能在四年内耗尽可用的训练数据。与此同时,内容所有者(例如报纸出版商)正开始采取更严格的措施限制数据的使用,进一步加剧了“数据共享”危机。
尽管这些限制可能会减缓AI系统的发展速度,但开发者正积极寻找应对方案。例如,OpenAI和Anthropic等知名AI公司已经公开承认这一问题,并暗示它们计划通过生成新数据或寻找非常规数据源来解决这一困境。一位OpenAI发言人表示:“我们使用了多种来源,包括公开可用的数据、与合作伙伴共享的非公开数据、合成数据生成,以及AI培训师提供的数据。”
尽管如此,这场数据危机可能迫使人们改变生成式AI模型的开发方式,从大型、通用的大型语言模型转向更小、更专业化的模型,进而改变整个AI生态系统的格局。
-
 C114通信网
C114通信网 -
 通信人家园
通信人家园
