

打响空间智能第一枪!李飞飞3个月拿下10亿估值。
生成式AI再次迎来里程碑时刻!
就在今天凌晨,斯坦福教授、“AI教母”李飞飞携手其新团队World Labs发布首个空间智能AI模型:从单个图像一键生成3D世界。
只要用户上传一张图片,该模型就能围绕这张图片的环境信息,生成一定范围内的3D虚拟世界。用户可以直接在网页端通过鼠标或者键盘观看3D世界。

目前,大多数的GenAI工具都以制作2D内容,如图像或视频等为主。当AI自动生成3D内容,将会提高3D内容的一致性,将极大简化了电影制作、游戏制作、VR游戏制作等内容素材的制作流程。
World Labs由李飞飞与三位联合创始人Justin Johnson、Christoph Lassner、Ben Mildenhall今年9月共同创立,致力于构建大型世界模型,生成、感知、交互3D世界,这也是李飞飞的首个AI创业项目。
目前,该模型还处于早期阶段,用户可通过名单候补的方式获得体验机会,产品正式上线预估到2025年。
从Midjourney,到Sora,再到World Labs,一个又一个的AI模型出现,宣告着AI内容创作的边界不断拓宽。
英伟达高级研究科学家Jim Fan用一句话总结了这段AI内容进化史:“GenAI正创造更丰富层次的环境缩影;Stable Diffusion是2D缩影;Sora是2D+时间维度的缩影;而World Labs是3D、沉浸式的缩影”。
01 由图片一键生成3D环境,World Labs借力打力
从文生图模型诞生以来,一直都有人尝试用AI打造3D模型,尽管行业类出现的模型并不算太少,但始终难有一个标志性的产品出现。
一方面是,现有的3D模型数据集太少,很难有足够的优质数据去训练出合适的模型。另一方面即便生成出3D内容,其展示的内容逻辑性以及画面质量都很难真正用到相应的电影、动画中去。
World Labs的空间智能AI模型 ,与大多数的AI生成3D模型不同,并非是通过文字提示生成3D内容,而是从图像生成3D内容。
李飞飞团队直接借助了现有文生图模型如FLUX、Midjourney、Ideogram、DALL-E等模型实现文字生成图像这一过程 。
这不但让World Labs直接兼容各种图片风格,不同模型生成图像会有不同风格呈现,而且新的AI系统可以继承风格特征,在3D世界中进一步展现。
此外,使用AI模型生成的图片打造3D环境的另一大好处是,由于基础的环境背景生成来源于此前的文生图AI模型,从一定程度上World Labs能够规避内容版权问题的风险。
比如说,在FLUX、Midjourney、Ideogram、DALL-E四款文生图模型中同样给出如下文字提示:
一间充满活力的卡通风格青少年卧室,床上铺着色彩鲜艳的毯子,书桌上摆放着一台电脑,墙上贴着海报,还有散落的运动装备。一把吉他靠在墙上,中间放着一张舒适的带图案地毯。窗户透出的光线给房间增添了温暖、年轻的氛围。
则会会得到四种不同风格的AI图像信息:

*从左到右分别由FLUX、Midjourney、Ideogram、DALL-E生成
空间智能模型则能够分别根据这四张图片生成一定范围内的3D环境。
比如说,由FLUX图片生成出来的环境则是:

由Midjourney图像生成出来的3D环境是:

由Ideogram图像生成出来的3D环境是:

由 DALL-E图像生成出来的环境是:

可以从预览的画面看出,首先生成出来3D环境是360度全景图像,在生成的3D环境内部,有一定范围的探索空间,基于网页端设置,可用键盘和鼠标进行新的探索。一旦超出探索范围,画面会显示“越界”提示用户。
其次,在风格上,生成的内容环境会继承原有的图形风格,整体3D内容的风格较为统一,多数物品的位置摆放没有特别违背常理的地方。
最后,在生成3D内容的过程中,新生成的AI世界将遵循3D几何形状的基本物理规则,具有实物感,与某AI生成的视频 梦幻感对比鲜明。
Eric Solorio展示了World Labs的模型如何填补其创意工作流程中的空白:用户可以安排角色在不同场景中出现,并指导精确的摄像机运动。“尽管我们只是参与到World Labs模型早期的角色当中,但是一切都是如此不可思议。”
Eric Solorio谈到现在有些动漫会采用AI制作背景画面,但是大多数的模型很难同时生成不同风格的3D环境内容,多数仅采用1至2种风格。但World Labs可以根据图片生成对应的风格画面。
02 打造四大玩法,让3D世界活起来!
从文生图模型诞生以来,一直都有人尝试用AI打造3D模型,尽管行业类出现的模型并不算太少,但始终难有一个标志性的产品出现。
造一个AI 3D模型并非难事,但World Labs选择了更进一步,不但让AI创造了一个3D世界,同时让AI帮助这个创造的3D世界更加有趣,在画面显示风格、交互玩法等多个方向进一步提供了一些方向性指引。
1、预测用户焦点走向,减小渲染压力
World Labs模型能够预测用户关注的焦点走向,这将较大减少实时渲染的计算压力。
一旦3D世界生成,虚拟世界的布局将会保持不变,一直存在。这也意味着如果用户把视线移开然后又回来,场景不会随时随地发生变化。这一方向,与VR世界里的注视点渲染技术相类似,从一定程度上能够减少设备渲染的压力。
同时,用户可以实时控制生成的3D内容。生成场景后,用户可以实时在场景中自由移动,既可以仔细观察花朵的细节,也可以偷看角落里露出的物体细节。
World Labs模型还能够将通过深度图将3D场景可视化,并且每个像素根据其与相机的距离着色,增强深度感。
2、提供三大动画效果,展示不同画面语言风格
在生成3D内容的基础上,World Labs还为生成的3D内容准备了多种画面呈现方式,为用户直观展示不同3D内容动画效果。
比如说,波浪形的效果下,画面里的樱花林和树木全部都在以波浪形“游动”。

再比如说,低像素沙画风格:

其中,Brittani Natali将World Labs技术与Midjourney、Runway、Suno、ElevenLabs、Blender和CapCut等工具相结合,并精心设计了摄像机路径工作,在一段视频中展示了不同的情绪风格。
3、提供四大交互方式,点击即可简单交互
用户可利用3D场景结构来构建交互效果。聚光灯场景下,生成的内容画面显示为:
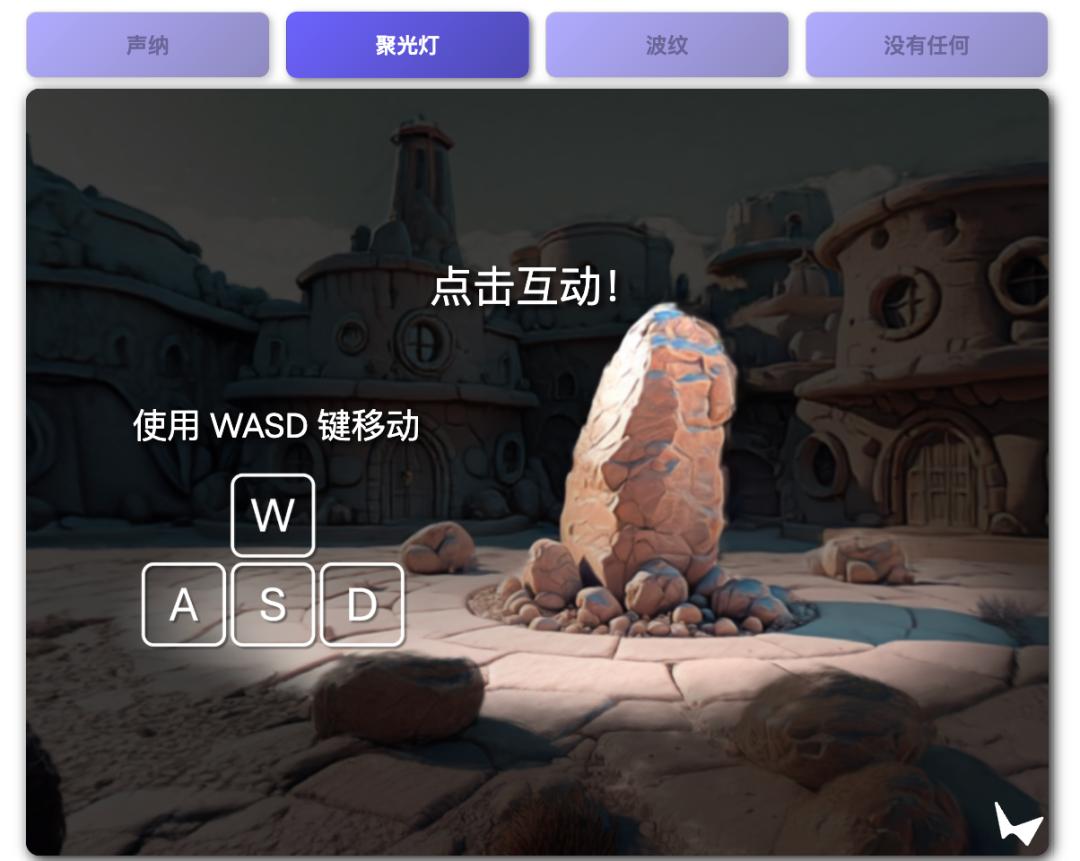
在声纳的显示 效果之下,用户可以每次点击3D世界的场景,能够看到交互画面中显示出一圈圈的声音波动信号,提示交互成功。

4、打造虚拟摄像头,自由控制焦距远近变幻
World Labs生成场景后,用户可以使用虚拟摄像头在浏览器中实现实时渲染,用户精确控制摄像头的角度时,还能够实现艺术摄影效果。
比如说用户可以模拟场景的景深,其中只有距离相机一定距离的物体才能聚焦:

*从近及远调整焦距画面变化
同时,用户还可以模拟推拉变焦,同时调整摄像机的位置和视野:

*从远及近调整焦距画面变化
03 3个月融资10亿,李飞飞瞄准“空间智能”
在诸多AI明星初创公司中,World Labs脱颖而出的理由离不开其明星人物——“AI教母”李飞飞以及强大的团队研发背景。
公司目前有20名成员,不仅包括CV和图形学领域的研究人才,还有系统工程、产品设计等职位,致力于在空间智能的基础模型和产品之间构建反馈闭环,从而让产品落地、服务用户。
World Labs9月正式亮相后,就迅速完成了2.3亿美元的融资,得到了AI大牛Geoffrey Hinton、Jeff Dean、谷歌前CEO Eric Schmidt等人的鼎力支持,公司估值已超过10亿美元。如此高额的估值和关注度,也能够说明业内对李飞飞的团队以及研究方向认可。
在官网页面中,World Labs提到致力于构建大型世界模型(Large World Models, LWMs),以感知、生成和与3D世界,并与之进行交互。公司目标是将AI模型从2D像素的平面提升到完整的3D世界,包括虚拟和现实世界,并赋予这些模型与人类相似的空间智能。
如今,首个AI项目成果一出,我们能够更加清晰地看待李飞飞在这一领域的坚定决心。
在今年10月,李飞飞接受了a16z的专访谈到自己对空间智能的理解。她认为,空间智能不同于苹果提出的空间计算,但空间计算需要空间智能。空间智能势必会推动着新AI硬件发展,但具体是眼镜,头显还是新的硬件产生,具体目前无法确定。
“空间智能是指机器在三维空间和时间中感知、推理和行动的能力,理解物体和事件在三维空间和时间中的位置,以及世界中的交互如何影响这些三维位置,以及在空间和时间上的位置,感知、推理、生成、交互,真正将机器从大型机或数据中心中解放出来,让它进入现实世界,并理解这个丰富多彩的三维、四维世界。”李飞飞说到。
“什么可以将机器人大脑的学习和行为与现实世界的大脑连接起来的呢?它必须是空间智能。”


