

AI六小虎中第一家拥抱DeepSeek的玩家出现了,是零一万物。
他们直接掏出了能迅速落地、迅速变现的产品:内置DeepSeek的企业大模型一站式平台“万智”,剑指toB商业化。

今天上午,零一万物线上举行了新春产品发布会,公司CEO李开复、COO黄蕙雯等多位核心人物悉数露面,为万智站台。
基于新平台带来的软硬件协同能力,零一万物也成为又一家可提供企业级DeepSeek部署定制解决方案的厂商。
万智平台目前已在零一万物官网上线“商务合作”入口,有需求的用户可以提交“提供服务”、“探索合作”和“其他”三种申请,公司全球解决方案与交付总经理表示,定价很快就会发布,“会给企业用户提供非常有竞争力的价格,比大厂更有优势”。
据AI蓝媒汇统计,在DeepSeek走红之后、零一万物“万智”发布之前,DeepSeek概念加持下的一体机领域,其实已经涌入了包括不仅限于百度、华为等众多一线大厂,以及像是京东云、联想、浪潮、中科曙光等同属头部集团的知名企业,赛道日趋拥挤。
分析人士指出,各家将软硬件打包成封装、集中发布一站式解决方案的目的其实完全一致,就是要抢抓这波DeepSeek带来的国产ChatGPT时刻,把市场中高涨的兴趣、涌现的需求落到手里,成为实打实的订单。
“基模能力与市场教育到位的当下,中国大模型产业亟需成熟的企业级解决方案,来推动大模型从通用能力向垂直行业深度融合。”
简单概括,就是卷应用,向钱看。
相关资料显示,2024年零一万物公司的整体收入已经超过了一亿元,其中B端业务占到整体收入的七成左右;C端的收入主要来自海外的To C付费应用(PopAi等),且已接近实现盈利。
资金层面,李开复年初透露称,去年七月份完成一笔融资后,目前公司账上现金充沛。并且团队内部其实更早就开始复盘和推演Scaling Law的上限问题,对现金的调配似乎相当审慎。
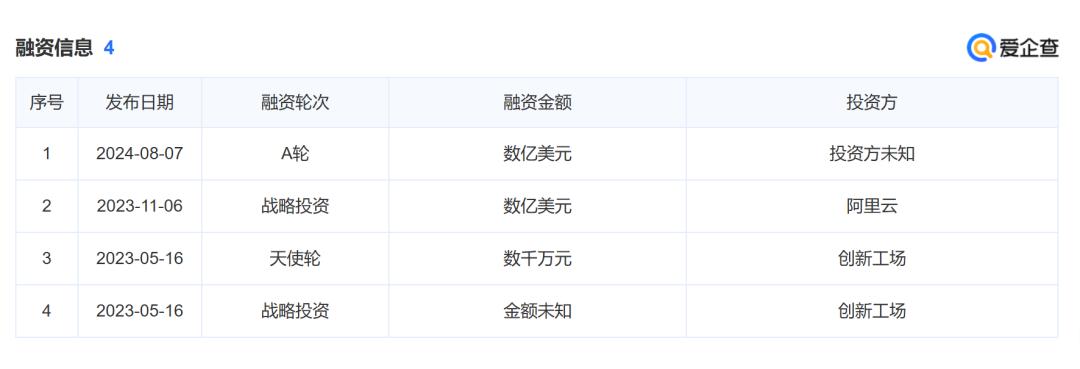
爱企查显示,零一万物先后完成四轮融资,但前两轮均为同样由李开复创办的创新工场出手,公开可查的其余资方似乎仅有阿里云。
此前AI蓝媒汇曾报道过断尾求生聚焦医疗的百川智能,这一次,同在DeepSeek浪潮下遭到冲击的零一万物选择了另一套解法:放低姿态,从百模大战的“参赛者”转换为“服务商”。
这个淡化自家技术模型声量、以DeepSeek为卖点、将超头模型封装成可落地toB产品的解决方案,是零一万物作为头部AI初创在AI大模型赛道的淘汰赛枪声中不得不面对的重新选位。
转变身份,用相对务实的姿态,叩开大规模toB商业化的门。
拼落地
零一万物的转型核心,就是这个面向企业的大模型一站式平台。
平台并非简单技术集成,而是针对企业落地大模型的三大痛点,部署难、定制难、应用难,依次提供了系统性解决方案,开箱即用。
过往企业接触AI,必须要提前考虑的一个问题就是安全:数据是否在本地,必须上云的话链路和存储分析是否封闭、是否安全。
零一万物联合头部硬件厂商推出的软硬集成式一体机方案,内部预装高性能了GPU并内置DeepSeek全系列模型,支持本地化推理与数据隔离,满足金融、政务等对数据安全敏感行业的需求。这种方案抹平了起步阶段的技术门槛,全链路的本地化部署也消除了企业对数据泄露的顾虑。
接下来的问题,幻觉。
DeepSeek-R1推理模型生成内容时所产生的幻觉,体验过的人有目共睹,它更擅长输出观点、情绪、华丽辞藻,但对于摆事实讲道理这一块,推理过程中产生的一些“奇思妙想”往往容易造成文不对题甚至 胡编乱造,所有这些信息失实统称“幻觉”。
业内一份幻觉测试结果显示,DeepSeek R1幻觉率高达14.3%,作为对比谷歌Gemini 2.0 Flash的这项数值仅有0.7%——复杂问题解决能力提升的代价就是在处理“开放性问题”时,DeepSeek-R1这类推理模型会强行构建逻辑链,从而导致虚构事实,且“推理能力与幻觉风险呈正相关,并且仅能通过优化训练策略改善,无法彻底消除幻觉”。
涉及业务数据甚至企业决策的AI,必须要最大程度降低幻觉发生的可能,避免出错。
这一点上,零一万物此前一款出海的C端AI搜索应用其实已经证明了团队在降低幻觉方面的功力,搜索准确性高达88%,校正幻觉的能力优于以搜索性能强著称的Gemini (73%)、Perplexity (73%)、ChatGPT Search (64%)等国外一线模型。

基于企业客户需求,新发布的“万智”平台整合了联网搜索、知识库RAG、智能体Agent等成熟组件。部署和实施速度大幅提升,引入Rewrite和Rerank模型后,结果召回率提升60%,准确率提升30%,幻觉效应大幅降低。
最后是定制适配,DeepSeek有两个硬伤:不支持 Function Call(工具调用)、不支持JSON Output(JSON 格式的字符串输出)。用做饭场景举例,这个AI理论上能熟练烹饪全球各国料理(数学/代码/自然语言推理),但一不会使用厨房工具(缺乏Function Call),需要用烤箱烤牛排时,它无法自动调用烤箱设备,必须人工操作;二只会口头报菜名(缺乏JSON Output),需要打印标准菜谱时,AI只能口述而无法输出格式化的电子文档。
两大企业刚需能力的缺失,让DeepSeek在落地工作场景时常常受限。零一万物则在“万智”平台上率先给出基于DeepSeek-R1的成熟微调方案,企业能够基于自身企业数据库对AI进行模型微调,准确对接垂直领域的具体业务需求。
整体来看,“万智”平台无论是宣发还是设计,都摆出一副老老实实给DeepSeek打辅助的姿态——聆听市场需求然后针对性设计。
李开复在采访中强调了“尊重商业规律”,按需设计产生按需购买,或许就是其中一条:你(企业)拿到了好用的DeepSeek创造价值,而我(AI公司)拿到了AI本身带来的商业价值。
退居“1.5线”,是出路吗?
发布会结束后,关于会上被问及的关于“是否还在做预训练模型”的问题,零一万物方面又单独做了一次澄清:我们是不做“万亿以上”超大参数基模,不是放弃自研,轻量化模型还是在做的。
两个信息:一,零一万物并未放弃自己的技术积累,头部模型和自研并行;二,自研技术确实在收缩。
听起来有些消极,但务实、理智、活下来,才是所谓六小虎等资源并不足够充足的玩家,在大模型淘汰赛现阶段所必须接受的局面。
大浪淘沙,自家模型没有跑出来的几位势必做出转型,要么退居二线继续换个姿势继续参与游戏,要不等到热度和资源挥霍殆尽彻底下桌。
零一万物这个目前还比二线更靠前一些,暂且算作一点五,接入阿里、收缩业务的李开复团队显然还是有心再搏一搏。
策略上规避超大模型的研发风险,但不彻底放弃技术层面主动权(自研),最重要的一点,务实、逐利,在AGI实现的那一天到来前,别彻底下桌。

李开复透露称,零一万物聚焦toB业务去年有超一亿元收入,今年第一季度的收入则已经接近了去年全年收入总和,“运营模式非常良性,今天发布的万智企业大模型一站式平台也能够锦上添花。”
DeepSeek给行业带来的是技术层面的范式,也掀起了行业去泡沫化的进程。在更先进的底层技术有突破前,市场的价值锚点必然从技术迁移到场景,企业客户会更关注“能否解决实际问题”而非“是否自主研发”,零一万物通过将DeepSeek技术封装为可落地的解决方案,为的就是快速验证AI落地的商业可行性,以及同步来带来的利润回报。
至于前面统计的与同赛道内大厂、同行玩家的竞争,李开复很坦率的解释了零一万物的优势:对比一些硬件厂商、组装厂,我们有研发底层模型的经验优势,更懂AI;而对比大厂,我们的方案,更有性价比,更便宜。

离开一线、站稳中游、成为辅助角色,没什么不好。
分蛋糕前活下来,才是最好的。
-
 C114通信网
C114通信网 -
 通信人家园
通信人家园
