

当成本与能力不再矛盾,AI应用落地就不再是一个选项,而是必然会发生的事。
3月16日,百度正式发布了文心大模型X1、文心大模型4.5,两款模型目前已经在文心一言官网上线,免费向用户开放。
自2019年3月文心大模型1.0版本上线以来,文心大模型的迭代周期一直在领跑国内AI产业。2023年10月,文心大模型4.0发布后,文心一言的用户规模在两个月内突破了1亿。
因此,已经宣布提前免费的文心大模型4.5和X1,也有望成为国内大模型继续破圈的下一个支点。
而这一次,无论是百度还是整个AI领域,想实现的目标已经不仅仅是用户增量,还有AI应用的产业化价值。
01
应用爆发前夜,头部模型厂商继续卷基础能力和低价
从Grok到Google AI Studio中的Gemini,大模型行业的“主角”总在不断变化,唯一不变就是一切应用领域还都处于商业化、市场化的前夕。
也正是在这个节点上,百度连发两款前沿模型。足见其下一步的方向,就是以多模态的壁垒来迎接很可能会在2025年出现的AI应用爆发期。
文心大模型4.5作为百度下一代基座大模型,质变的创新点在于原生多模态。通过多个模态联合建模实现协同优化,多模态理解、文本和逻辑推理能力显著提升,在多项测试中表现优于GPT4.5,API调用价格仅为GPT4.5的1%。
文心大模型X1则是对标DeepSeek R1推理能力的深度思考模型,核心目标是将大模型从“生成工具”升级为“决策大脑”。X1目前的定价仅为DeepSeek R1的一半,与此同时,在测评效果中,X1在不少方面都体现出了比肩DeepSeek R1的能力。
比如,在语言生成的测评中,X1能够通过一段简单的背景描述指令,生成剧本杀级别的悬疑推理故事。
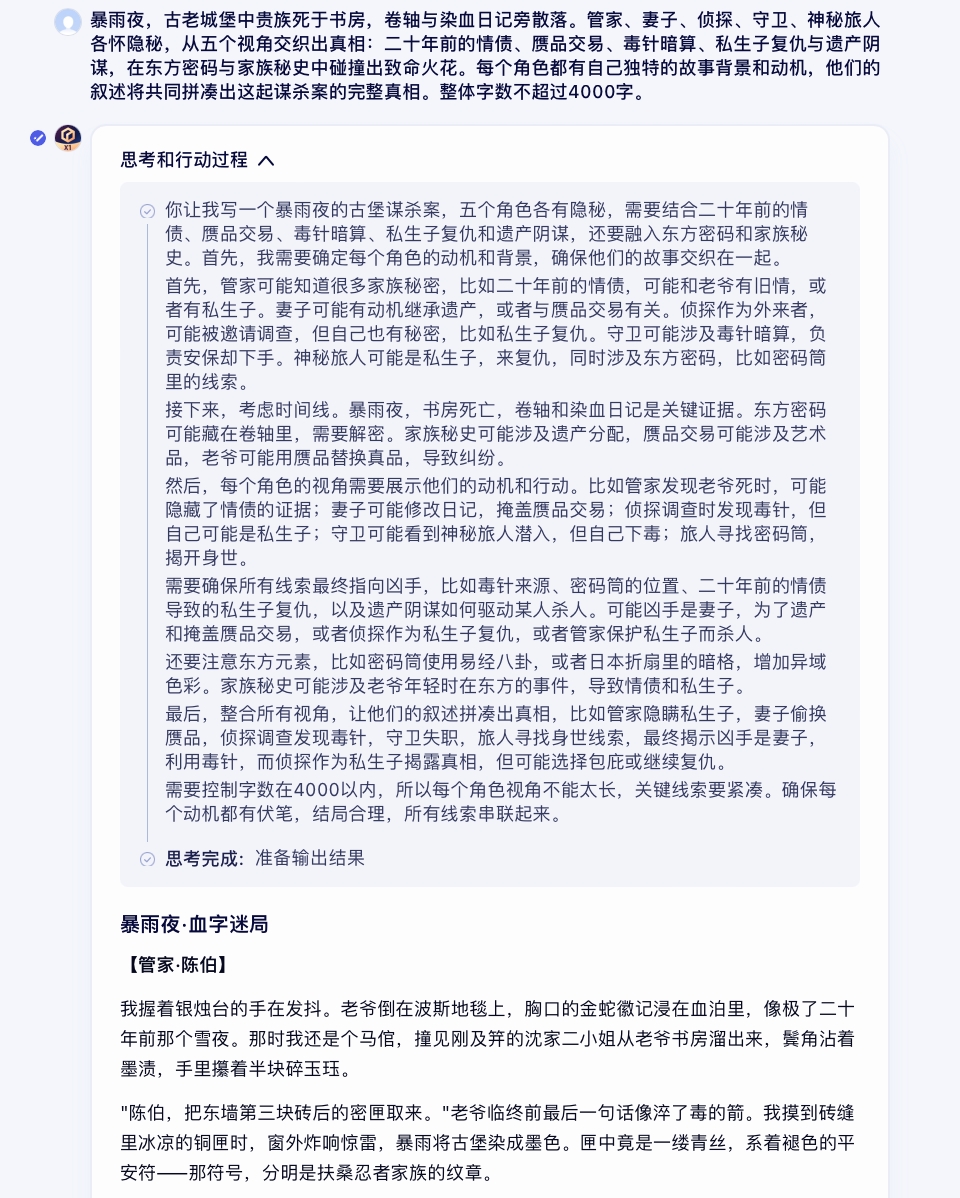
对于中文社交媒体“锐评”语气模仿的能力,也是测评中能感受到的一个亮点。相比用户对大模型的“端水”印象,X1的回答更具观点性,在一些需要态度的场景表现得更尖锐,也为多渠道内容运营的生产效率提供了新思路。

从文心4.0发布至今,不到一年半时间里,百度在投入研发的同时,也在致力于打造AI生态:提供开箱即用的AI开发支持;将文心大模型深度融入搜索、地图、网盘、文库等十几个产品。2021年,百度从“AI+云”的整合过渡阶段来到了云智一体的新阶段。
文心4.5和文心X1的低价乃至免费,不只是一种技术与市场的策略,背后是技术创新驱动的成本降低,也是应用爆发阶段采取的提速策略。此次百度发布并免费开放文心4.5的动作说明了三点趋势:
第一,作为全球为数不多从四层架构布局的AI公司,百度的研发效率和芯片层的“家底”使其有充分的长期市场化、商业化信心。
第二,除了大模型以外,国内大厂也在拼MaaS平台,即日起,企业和开发者已经能在千帆调用文心4.5API,文心XI即将上线。
第三,从整个国内AI领域的发展阶段来说,企业拥抱新技术的情绪空前高涨,百度作为头部厂商,也有意通过降低开发者和企业的接入门槛,加速AI产业化的生态构建。
02
原生多模态的生产力,由谁定义?
从下面这个复杂语义理解及联网分析的测评案例中能看到,去幻觉能力的显著提升,是文心4.5的另一个亮眼特性。

而之所以文心4.5去幻觉等能力表现出色,也是得益于FlashMask动态注意力掩码、多模态异构专家拓展技术、高知识密度的大数据构建技术等创新技术。
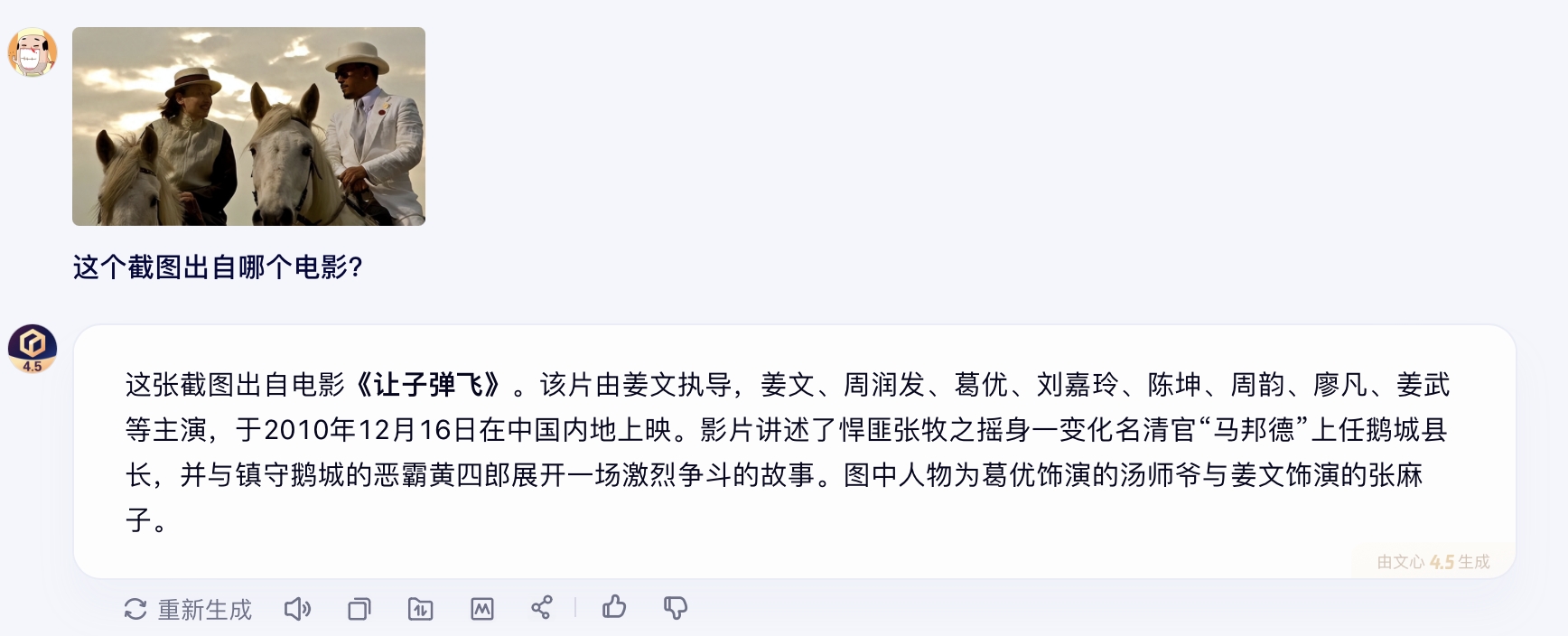
在我们的测试中,输入一张电影截图,文心4.5就能准确识别到它出自哪里。智能搜索、内容审核、影视文化等应用场景中,这一类能力将大有可为。
图表识别、理解,进而辅助决策的能力也可以体现其去幻觉后的多模态生成表现。

其实,业界对于多模态大模型的看好,早就不是什么秘密。
从多模态联合建模来切入图片、视频、文本,语义能得到统一的表达,从而解决大模型在聊天机器人模式下信息割裂的问题。
近期,MCP协议在blender上的vibe design智能化设计吸引了很多人的目光,通过多轮对话来调整设计模型,让大模型成为一个保持一致性从而“可控的工具”,而不是一个交作业的学生。
上周,Google AI Studio上基于Gemini能力的多轮对话、生成和编辑图像的表现,也使之成为不少开发者的“主力AI”,而Gemini正是靠多模态生成的表现占据舆论中心。
放眼国内,文心4.5是百度首个原生多模态大模型。在这个时间节点上的研发成果是全球前沿的。此外,这些新的风口都说明:大模型和AI产业化未来的趋势就是多模态生产力。
据悉文心X1也支持多模态,在中文知识问答、文学创作、文稿写作、日常对话、逻辑推理、复杂计算及工具调用等方面表现尤为出色。
文心X1的能力得益于不少强大技术,首先,通过递进式强化学习,在创作、搜索、工具调用、推理等场景综合提升应用能力。其次,针对目前大多数深度思考型AI应用还不擅长的深度搜索、工具调用等场景,文心X1进行了基于思维链和行动链的端到端训练,并建立了多元统一的评估系统。
而在成本方面,飞桨和文心联合在模型压缩、推理引擎、系统框架三个层面,通过面向长序列的注意力机制量化、低精度高性能算子优化、分离式部署架构等实现了深度压缩和推理加速。这也是文心X1能把成本压缩到DeepSeek R1一半的技术逻辑来源。
03
技术普惠,推动AI产业化
随着全球大模型进入“深度思考”时代,大模型产业化的成本一降再降,也让大多数企业对于AI不再只是观望。
当前企业推进AI产业化应用的核心痛点集中于两点:技术门槛高,成本难以承受。
中小型企业往往受限于技术成本,而中大型企业即便拥有技术团队,也常因训练成本高昂、场景适配复杂而陷入“投入产出失衡”的困境。
此前曾在较长一段时间里,企业落地AI的形态和对于技术边界的认知尚不明朗,确实存在大量的低效投入。但随着两年来各大模型厂商基础能力的提升,各大模型的生成效果已经让各行各业都开始拥抱大模型产业化的可能性。
百度文心4.5和X1的“低价+高开放性”策略,正是直击了这一矛盾。
过去一年里,百度智能云业务稳步增长,成为第二增长引擎,也说明了这一点。越来越多的企业能够通过MaaS、接入了基础大模型的工具等,可以不必在前期投入过重,直接运用不断迭代更新的基础大模型的能力来构建应用,从场景和业务的适配性中解构AI的价值。
以下是一段来自文心4.5的音视频内容分析测评,可以看出对于这种不需要深度推理的基于事实作答的多模态处理中,其表现仍然可圈可点。

这一案例也印证了百度以大模型应用来放眼整个AI产业化的思路可行性:开箱即用的通用能力和性价比,能够把AI产业化从重资产投入的事业变为一个轻量化的工具。比如从网盘里截取音视频到文心大模型中总结。
毫无疑问,能力更强的原生多模态大模型能够以创造性更强、门槛更低的方式来释放这种潜力。而随着文心4.5的,免费低价、工具调用、开箱即用这些特性正在成为大模型标配,AI产业化的最大障碍不再是“能不能做”,而是“敢不敢想”。
2023年3月,百度是国内第一家率先提出“用大模型重做全部产品”的大模型厂商。从那以后,百度开始坚定投入训练下一代基础模型,包括今天的原生多模态大模型。
2025年,被各行各业看好会是AI应用效应在企业内部显现的爆发年。而上升到企业管理和AI决策层面,在大模型的大规模使用中,准确度其实非常关键。因此文心4.5在去幻觉上实现突破。而在离企业本地化部署最近的RAG等技术方面,文心也一直在互联网、政务、医疗等不同行业场景中构建基于中文深度理解的搜索增强技术。
可以说,从百度自身的业务剖面来看,无论是垂类场景的数据整合还是,RAG、iRAG是其积淀多年的优势领域,同时也是大模型竞争的核心能力。
对于产业落地场景来说,很多时候能力全面比有长板更重要,这也是以Manus为代表的Agentic AI的理念之一。文心X1,就像是一个能够通过自主调用工具来拓展能力边界的多边形战士,集成了包括搜索、文档问答、代码解释器等在内的可调用工具。
AI应用领域,一个积极的态势是,大模型厂商们正在与企业共同朝着产业化落地演进,而不仅仅是一场卷参数的“竞技”。
2025年,百度有“搜索基因+技术壁垒+厂商工程化能力+AI生态先发优势”四重护城河,这些以往的优势和未来的发力方向也赋予了文心大模型本土场景理解与洞察的业务基因。
AI应用将去向何方,技术的演进轨迹似乎已经清晰可见:从辅助到决策,从“劳动力”到“大脑”,从单点突破到全链重构。而“一年磨一剑”的百度文心,就是在技术普惠的浪潮下,迎来了自己的大模型年。
-
 C114通信网
C114通信网 -
 通信人家园
通信人家园
