

IT之家 3 月 11 日消息,随着 DeepSeek R1 的推出,强化学习在大模型领域的潜力被进一步挖掘。Reinforcement Learning with Verifiable Reward(RLVR)方法的出现,为多模态任务提供了全新的优化思路,无论是几何推理、视觉计数,还是经典图像分类和物体检测任务,RLVR 都展现出了显著优于传统监督微调(SFT)的效果。
然而,现有研究多聚焦于 Image-Text 多模态任务,尚未涉足更复杂的全模态场景。基于此,通义实验室团队探索了 RLVR 与视频全模态模型的结合,于今日宣布开源 R1-Omni 模型。
R1-Omni 的一大亮点在于其透明性(推理能力)。通过 RLVR 方法,音频信息和视频信息在模型中的作用变得更加清晰可见。
比如,在情绪识别任务中,R1-Omni 能够明确展示哪些模态信息对特定情绪的判断起到了关键作用。


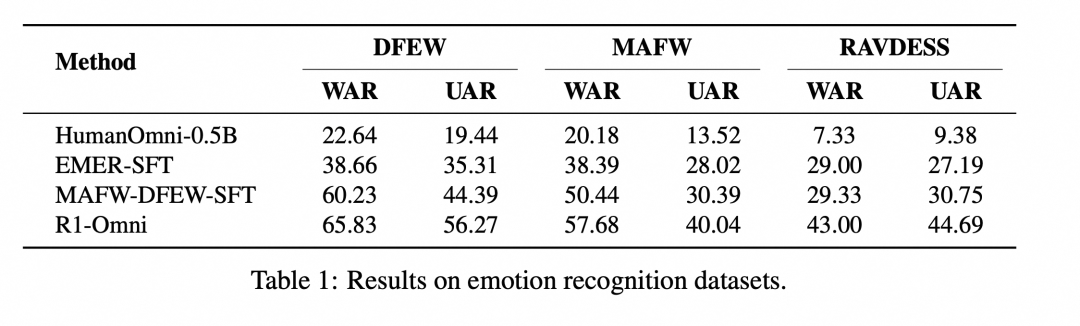
为了验证 R1-Omni 的性能,通义实验室团队将其与原始的 HumanOmni-0.5B 模型、冷启动阶段的模型以及在 MAFW 和 DFEW 数据集上有监督微调的模型进行了对比。
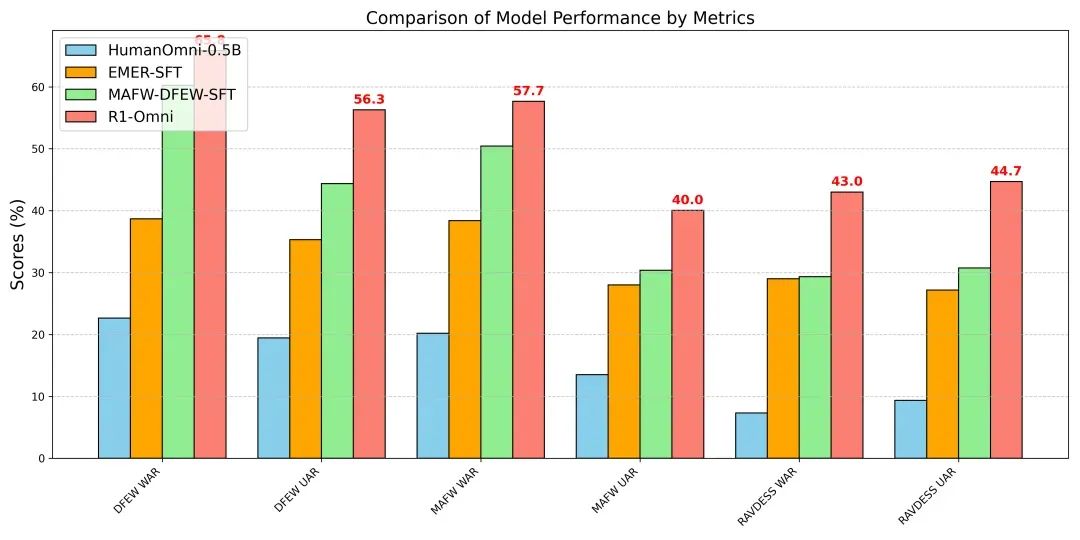
实验结果显示,在同分布测试集(DFEW 和 MAFW)上,R1-Omni 相较于原始基线模型平均提升超过 35%,相较于 SFT 模型在 UAR 上的提升高达 10% 以上。在不同分布测试集(RAVDESS)上,R1-Omni 同样展现了卓越的泛化能力,WAR 和 UAR 均提升超过 13%。这些结果充分证明了 RLVR 在提升推理能力和泛化性能上的显著优势。
IT之家附 R1-Omni 开源地址:
论文:https://arxiv.org/abs/2503.05379
Github:https://github.com/HumanMLLM/R1-Omni
模型:https://www.modelscope.cn/models/iic/R1-Omni-0.5B


