

Anthropic在今天2025年2月25日,全新发布Claude 3.7 Sonnet与编程助手,也被称为迄今为止最先进的人工智能模型。
最大亮点是,Claude 3.7 Sonnet 引入了“思考模式”切换功能,允许用户根据任务复杂性优化 AI 的响应时间。
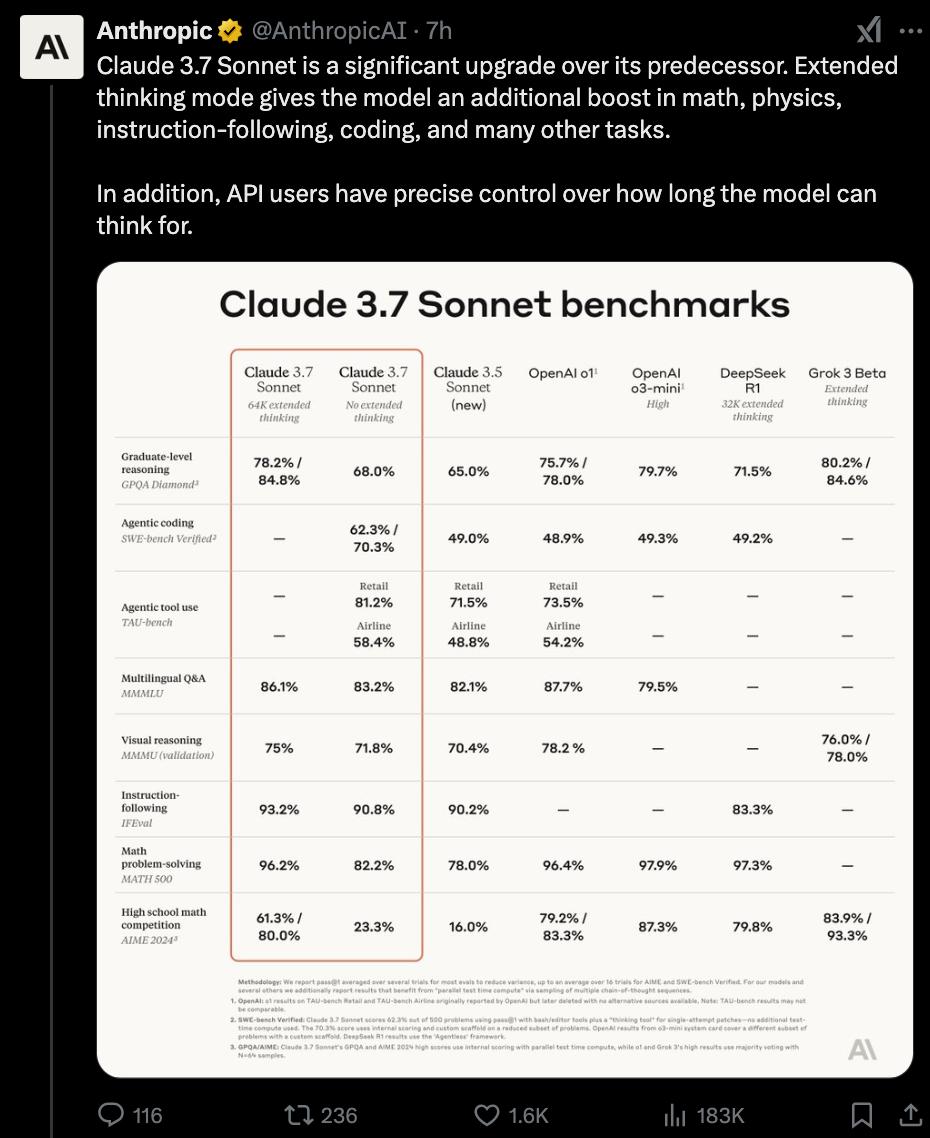
在扩展思维模式下,Claude 3.7 Sonnet在研究生级推理任务上实现了78.2%的准确率,挑战了 OpenAI的最新模型,并超越了DeepSeek-R1。
惊讶的是,即使增加了推理功能,Anthropic依旧保持了之前的定价,即每百万输入tokens3美元,每百万输出tokens15美元。
Anthropic对打OpenAI和Deepseek走出新的闭源之路——推理、规划和自我纠正不应该是独立的功能
在对Claude 3.7 Sonnet的总结介绍中,Anthropic使用了“将前沿推理变为实用技术”的描述。
指出他们开发Claude 3.7 Sonnet的理念与其他推理模型不同。
就像人类用一个大脑来处理快速反应和深度思考一样,他们认为推理应该是前沿模型的集成能力,而不是一个完全独立的模型。
Anthropic这种统一的方法也将为用户创造更无缝的体验。
接受采访时,Anthropic 研究产品管理负责人Dianne Penn也表示:
“我们只是认为推理是人工智能的核心部分和核心组件,而不是需要单独付费才能使用的单独功能。就像人类一样,人工智能应该既能快速响应,又能进行复杂思考。
对于‘现在几点了?’这样的简单问题,它应该立即回答。
但对于复杂的任务——比如计划为期两周的意大利之旅,同时满足无麸质饮食需求——它需要更长的处理时间。”
“我们并不认为推理、规划和自我纠正是独立的功能,”
“所以这本质上是我们表达这种哲学差异的方式……理想情况下,模型本身应该能够识别问题何时需要更深入的思考并进行调整,而不是要求用户明确选择不同的推理模式。”
从技术上看,Claude 3.7 Sonnet在以下几个方面体现了这一理念。
首先,Claude 3.7 Sonnet 既是普通的大型语言模型(LLM),也是一个推理模型:你可以选择让模型正常回答,或者在回答前进行更长时间的思考。
在标准模式下,Claude 3.7 Sonnet是Claude 3.5 Sonnet 的升级版本。
在扩展思考模式下,它会在回答前进行自我反思,从而提高其在数学、物理、指令遵循、编码和许多其他任务上的表现。
在这两种模式下,对模型的提示效果相似。
其次,当通过API使用Claude 3.7 Sonnet 时,用户还可以控制思考的预算:你可以告诉Claude思考的时间不超过N个 token,N的值可以达到其128Ktoken 的输出限制。
意味着你可以在回答速度(和成本)与回答质量之间进行权衡。
这就完全满足了现在很多用户“嫌弃”Chatbot在某些回答太慢的诉求!
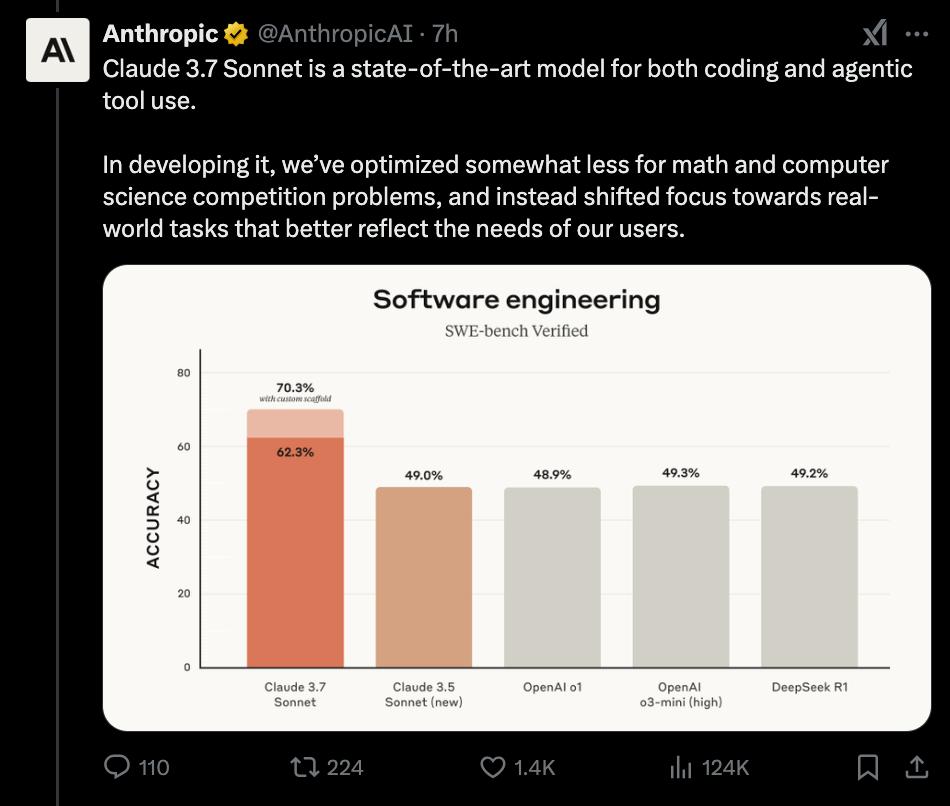
第三,Anthropic在开发推理模型时,对数学和计算机科学竞赛问题的优化较少,而是将重点转移到更真实世界的任务上,这些任务更好地反映了企业实际使用 LLM 的方式。
对于企业端而言,各家公司都在加大投入试图将人工智能融入其运营,而目前都在摸索和试错过程中。
Anthropic今天的混合模型提供了一条引人注目的中间路线:能够根据手头的任务微调人工智能的性能,从即时客户服务响应到复杂的分析。
说实话,Deepseek的横空出世,不少人呐喊,被影响最大的就是Anthropic,人人都在想,还有什么模式可以支撑他们走闭源……
今天…… 就来了……
和OpenAI与Deepseek不一样(OpenAI为不同的功能维护单独的模型,DeepSeek 则专注于性价比),Anthropic 追求能够处理常规任务和复杂推理的统一系统,并且强技术能力为这条路推山动土,且价格不涨……
AI coding还是Anthropic的天下?
自 2024 年6月以来,Sonnet其实一直是全球开发人员的首选模型。
前不久OpenAI的o3的发布,在编程领域取得许多突破,让人开始担忧Anthropic的编程地位。
今天,Anthropic同时推出了Claude Code,其联合创始人兼首席科学官贾里德·卡普兰 (Jared Kaplan) 也对外表示,新模型“在编码方面更加强大,特别是在接管和执行真正复杂的编码任务方面”,势必要夺回,AI coding的一哥地位啊!
Anthropic表示,他们的Claude Codd--也是他们首个代理编码工具——将进一步赋权开发人员,该工具以有限的研究预览版形式推出。
Claude Code 将作为一个积极的合作者,搜索和阅读代码、编辑文件、编写和运行测试、将代码提交和推送至 GitHub,并使用命令行工具——在每一步都让程序员保持参与。
讲真的,别人都在说,AI coding替代程序员、猛猛裁员、35岁危机,人家说“在每一步都让程序员保持参与,做你最好的助手和伙伴”……
你猜猜…………
他们到底用谁……
