

今天开始,我们正式进入 DeepSeek 开源周。
DeepSeek 开源项目第一弹 FlashMLA,已经在极短的时间内发酵到全网了,短短几个小时,该项目就已经收获了超过 3.5K Star,且还在不断飙升。
虽然 FlashMLA 里的每个字母都认识,连在一起就看不懂了。别急,我们整理了一份 FlashMLA 速通指南。
由 Grok 3 整理,APPSO 核实
让 H800 性能暴增,FlashMLA 到底什么来头?
据官方介绍,FlashMLA 是一个针对 Hopper GPU 优化的高效 MLA(Multi-Head Latent Attention)解码内核,支持变长序列处理,现在已经投入生产使用。
FlashMLA 通过优化 MLA 解码和分页 KV 缓存,能够提高 LLM(大语言模型)推理效率,尤其是在 H100 / H800 这样的高端 GPU 上发挥出极致性能。
说人话就是,FlashMLA 是一种专门为 Hopper 高性能 AI 芯片设计的先进技术——一种「多层注意力解码内核」。
听起来很复杂,但简单来说,它就像是一个超级高效的「翻译器」,能让计算机更快地处理语言信息。 它能让计算机处理各种长度的语言信息,而且速度特别快。
比如,你在用聊天机器人的时候,它能让你的对话更快地得到回复,而且不会卡顿。 为了提高效率,它主要通过优化一些复杂的计算过程。 这就像是给计算机的「大脑」做了一个升级,让它在处理语言任务时更聪明、更高效。
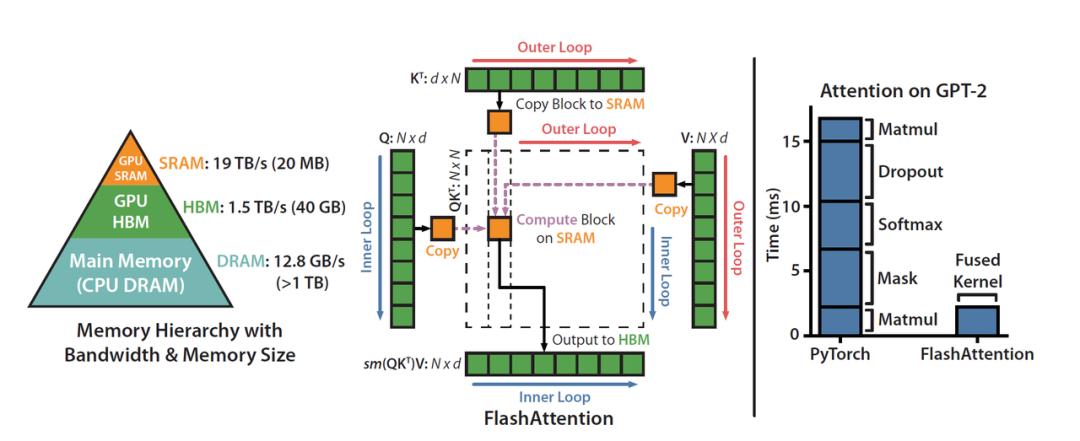
DeepSeek 官方特意提到,FlashMLA 的灵感来自 FlashAttention 2&3 和 cutlass 项目。
FlashAttention 是一种高效的注意力计算方法,专门针对 Transformer 模型(如 GPT、BERT)的自注意力机制进行优化。它的核心目标是减少显存占用并加速计算。cutlass 也是一个优化工具,主要帮助提高计算效率。
DeepSeek 的爆火出圈很大程度上是因为以低成本创造了高性能模型。
而这背后的秘籍主要得益于其在模型架构和训练技术上的创新,尤其是混合专家(MoE)和多头潜在注意力(MLA)技术的应用。

FlashMLA 则是 DeepSeek 公司开发的一种针对多头潜在注意力(MLA)技术的实现和优化版本。 那么问题来了,什么是 MLA( 多头潜在注意力)机制?
在传统的语言模型里,有一种叫「多头注意力(MHA)」的技术。 它能让计算机更好地理解语言,就像人用眼睛同时关注多个地方一样。
不过,这种技术有个缺点,就是需要很大的内存来存储信息,就像一个很能装的「仓库」,但仓库太大就会浪费空间。
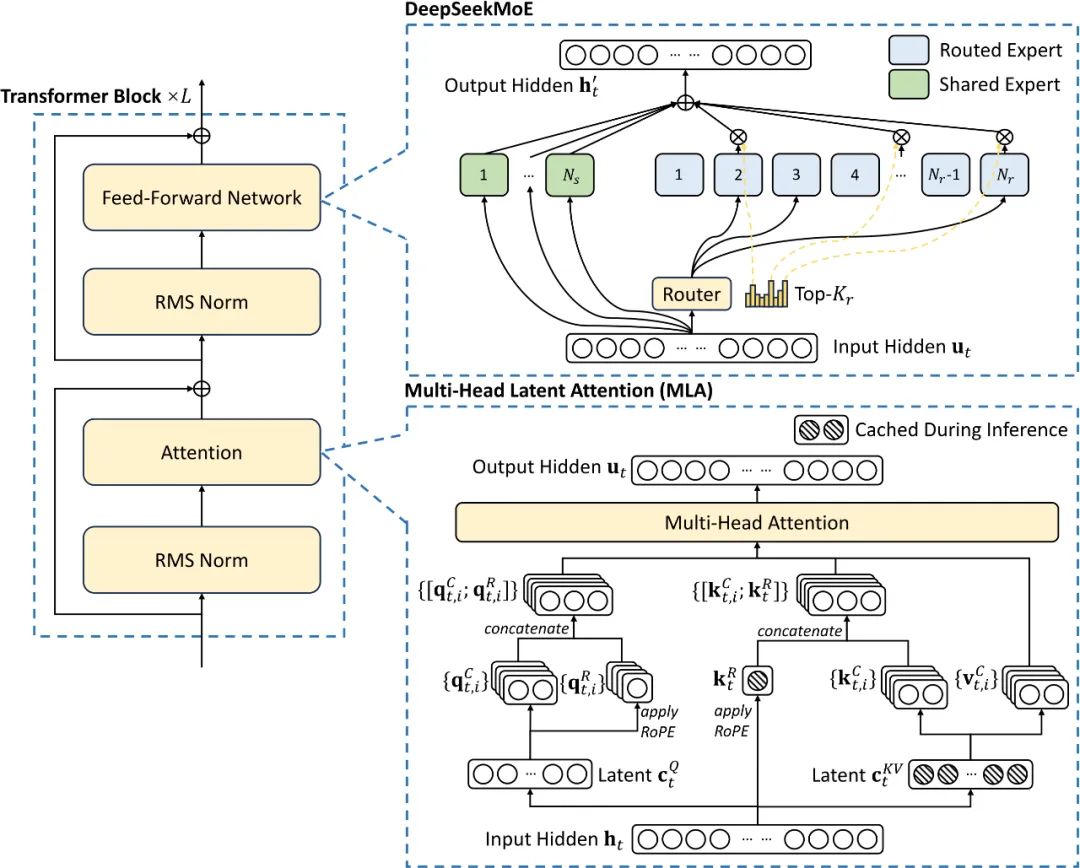
MLA 的升级之处在于一种叫「低秩分解」的方法。
它把那个大仓库压缩成一个小仓库,但功能还是一样好,就像把一个大冰箱换成一个小冰箱,但里面的东西还是能放得下。这样一来,在处理语言任务的时候,不仅节省了空间,速度还更快了。
不过,虽然 MLA 把仓库压缩了,但它的工作效果和原来一样好,没有打折扣。
当然,除了 MLA 和 MoE,DeepSeek 还用了其他一些技术来大幅降低了训练和推理成本,包括但不限于低精度训练、无辅助损失的负载均衡策略以及多 Token 预测(MTP)。
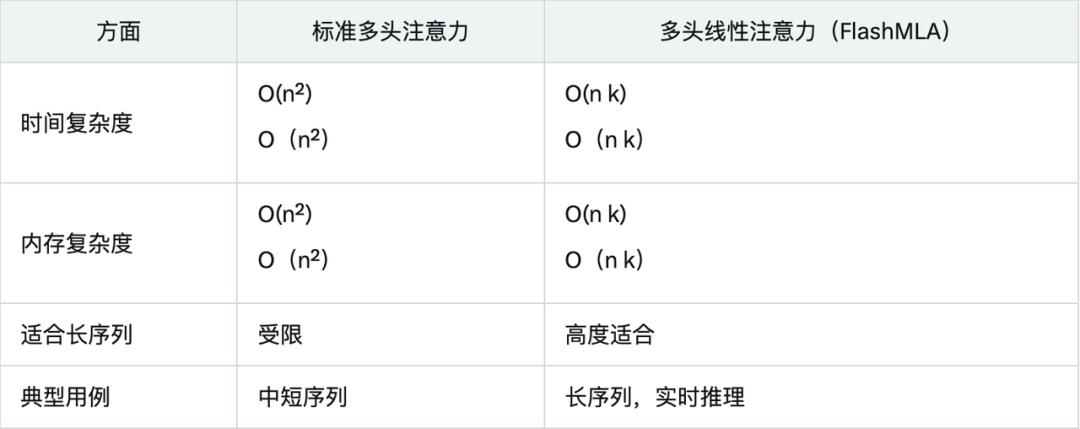
性能数据表明,FlashMLA 在内存和计算限制下的表现远超传统方法,这得益于其线性复杂度的设计和针对 Hopper GPU 的优化。
与标准多头注意力的对比,更是进一步凸显 FlashMLA 的优势:
FlashMLA 的主要应用场景包括:
- 长序列处理:适合处理数千个标记的文本,如文档分析或长对话。
- 实时应用:如聊天机器人、虚拟助手和实时翻译系统,降低延迟。
- 资源效率:减少内存和计算需求,便于在边缘设备上部署。
目前 AI 训练或推理主要依赖英伟达 H100 / H800,但软件生态还在完善。
由于 FlashMLA 的开源,未来它可以被集成到 vLLM(高效 LLM 推理框架)、Hugging Face Transformers 或 Llama.cpp(轻量级 LLM 推理) 生态中,从而有望让开源大语言模型(如 LLaMA、Mistral、Falcon)运行得更高效。
同样的资源,能干更多的活,还省钱。
因为 FlashMLA 拥有更高的计算效率(580 TFLOPS)和更好的内存带宽优化(3000 GB/s),同样的 GPU 资源就可以处理更多请求,从而降低单位推理成本。
对于 AI 公司或者云计算服务商来说,使用 FlashMLA 也就意味着更低的成本、更快的推理,让更多 AI 公司、学术机构、企业用户直接受益,提高 GPU 资源的利用率。
此外,研究人员和开发者还可以基于 FlashMLA 做进一步的优化。
过去,这些高效 AI 推理优化技术通常主要掌握在 OpenAI、英伟达等巨头手里,但现在,随着 FlashMLA 的开源,小型 AI 公司或者独立开发者也能用上, 更多人进入 AI 领域创业,自然也就有望催生更多的 AI 创业项目。
简言之,如果你是 AI 从业者或者开发者,最近在用 H100 / H800 训练或推理 LLM,那么 FlashMLA 可能会是一个值得关注或研究的项目。
与春节期间网友扒出 DeepSeek V3 论文具体提到了 PTX 的细节相似,X 网友发现 DeepSeek 发布的 FlashMLA 项目中同样包含了一行内联 PTX 代码。
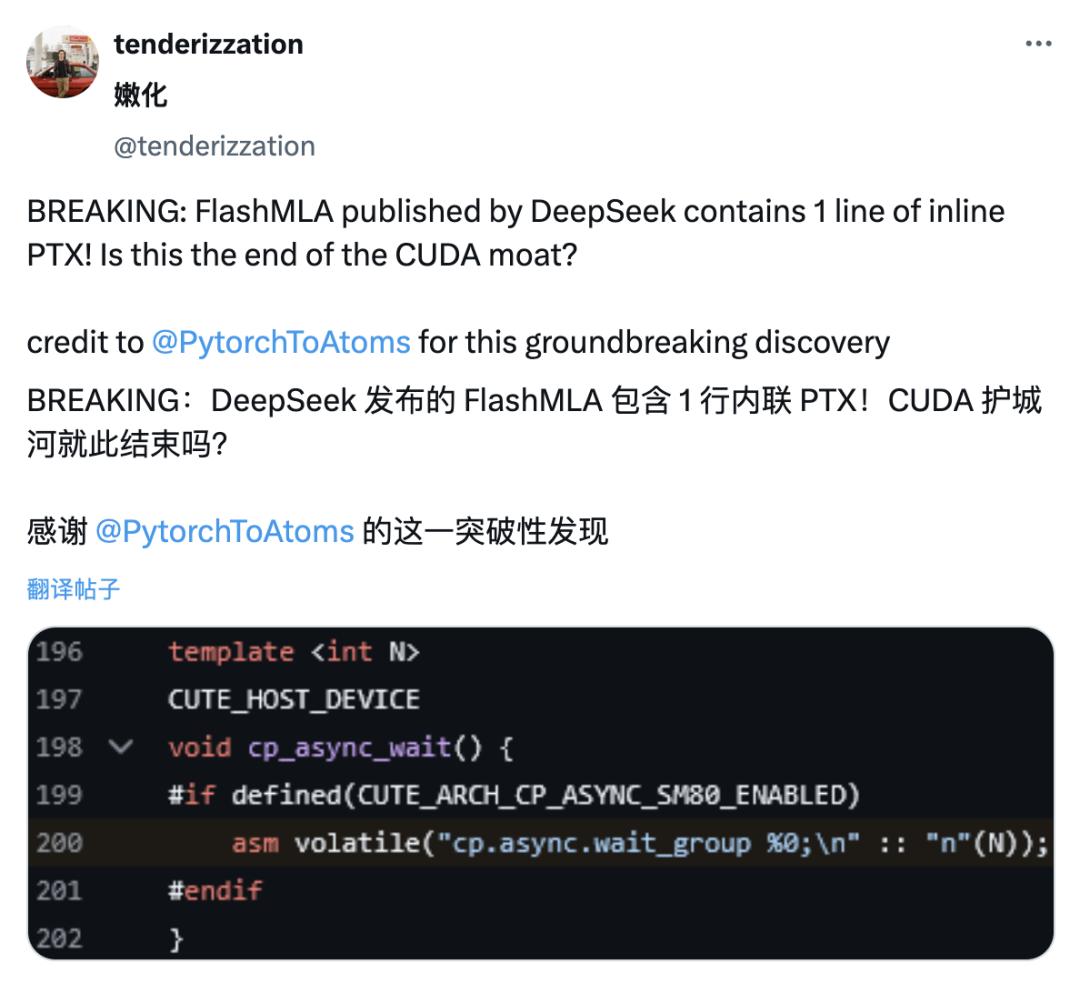
PTX 是 CUDA 平台的中间指令集架构,处于高级 GPU 编程语言和低级机器代码之间,通常被视为英伟达的技术护城河之一。
通过内联 PTX,这使得开发者能够更精细地控制 GPU 的执行流程,从而可能实现更高效的计算性能。
此外,直接利用英伟达 GPU 的底层功能,而不必完全依赖于 CUDA,也有利于降低英伟达在 GPU 编程领域的技术壁垒优势。
换句话说,这或许也意味着 DeepSeek 可能在有意绕开英伟达封闭的生态。
当然,如无意外,根据外媒的爆料,本周接下来预计还有 GPT-4.5、Claude 4 等模型的发布,去年年底没能看到的 AI 大战或将在本周上演。
看热闹不嫌事大,打起来,打起来。
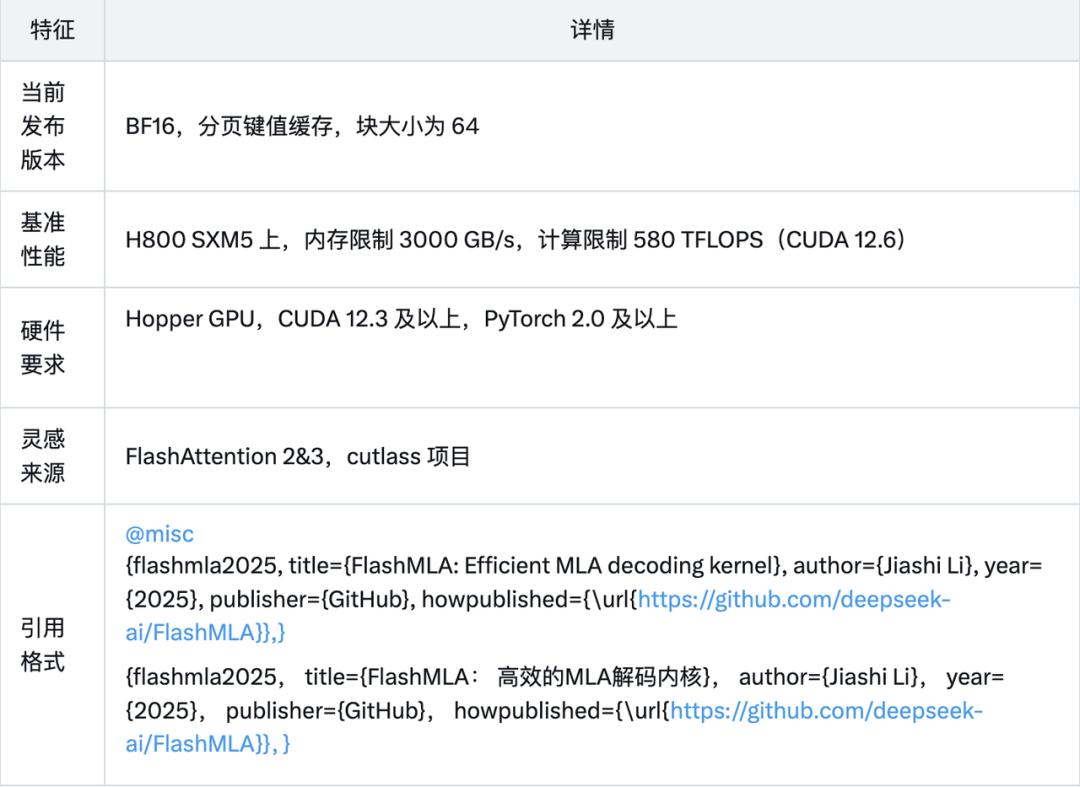
官方部署指南
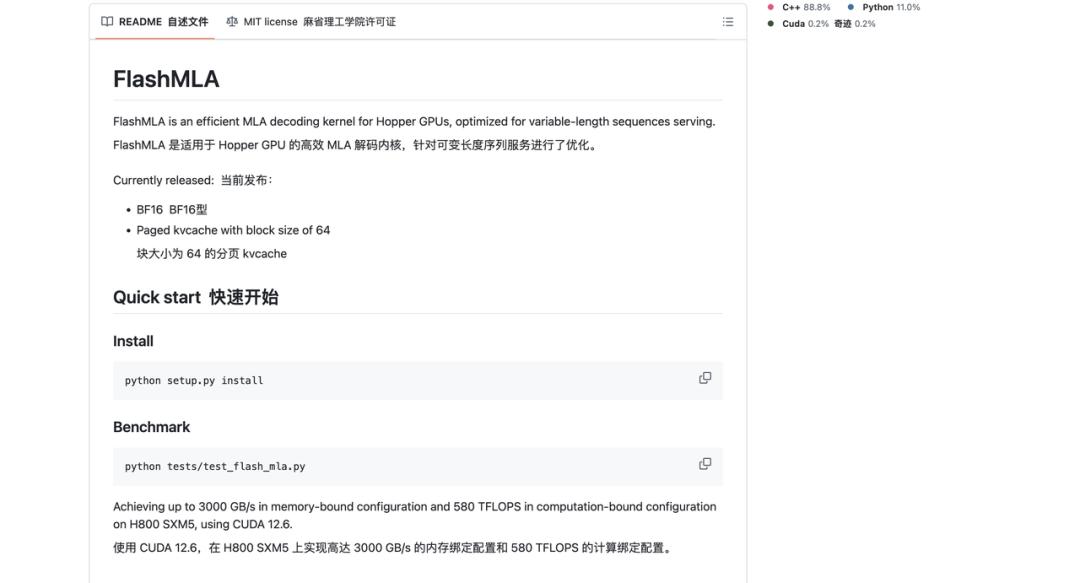
FlashMLA 是一种高效的 MLA 解码内核,专为 Hopper GPU 优化,可用于处理变长序列推理。
当前已发布版本支持:
- BF16
- 分页 KV 缓存,块大小为 64
在 H800 SXM5 上运行 CUDA 12.6,FlashMLA 在受内存带宽限制的配置下可达 3000 GB/s,在受计算能力限制的配置下可达 580 TFLOPS。
项目配备:
- Hopper GPU
- CUDA 12.3 及以上版本
- PyTorch 2.0 及以上版本
附上 GitHub 项目地址:https://github.com/deepseek-ai/FlashMLA
安装
python setup.py install
基准
python tests/test_flash_mla.py
python tests/test_flash_mla.py 是一个命令行指令,用于运行 Python 测试文件 test_flash_mla.py,通常用于测试 flash_mla 相关的功能或模块。
用法
from flash_mla import get_mla_metadata, flash_mla_with_kvcache
tile_scheduler_metadata, num_splits = get_mla_metadata(cache_seqlens, s_q * h_q // h_kv, h_kv)
for i in range(num_layers):
...
o_i, lse_i = flash_mla_with_kvcache(
q_i, kvcache_i, block_table, cache_seqlens, dv,
tile_scheduler_metadata, num_splits, causal=True,
) ...


