

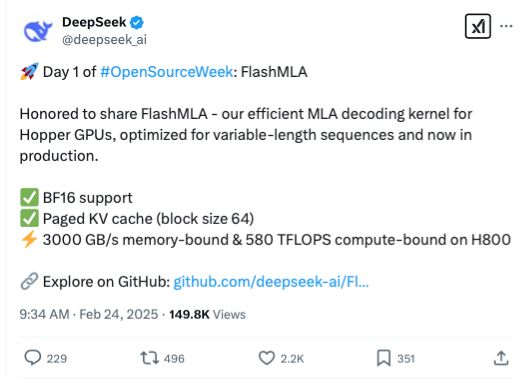
国内 AI 巨头 DeepSeek 开源周终于开始了!今天发布的重磅项目 FlashMLA 又一次点燃了 AI 技术圈。
这是一款专为英伟达 Hopper 架构 GPU 优化的高效解码内核,不仅将H800 GPU的性能推向新高度,可以说是大模型推理服务的革命性加速器了。
技术解析:H800 GPU 如何起飞?
FlashMLA 专注于优化大语言模型(LLM)的解码过程,通过重构内存访问和计算流程,显著提升变长序列处理的效率。其设计灵感源于业界知名的FlashAttention 2&3和cutlass项目,但在分块调度和内存管理上实现了进一步突破。
同时,它还有两大性能杀手锏:
1.分页KV缓存(块大小64)
采用页式内存管理,减少显存碎片化,使内存带宽在H800上飙升至 3000 GB/s,尤其适合高并发推理场景。
2.BF16精度支持
在计算密集型任务中兼顾精度与速度,单卡算力达到 580 TFLOPS,相比传统方案提升30%以上。
DeepSeek 官方表示,FlashMLA 已投入实际生产环境,支持从聊天机器人到长文本生成的实时任务,为 AI 应用的商业化落地提供开箱即用的解决方案。
开源时代:从技术到生态的全面布局
在评论区可以看到网友对 DeepSeek 本周开源计划的猜测:第五天会不会是 AGI?而在这一推测的背后,我们也可以看到 DeepSeek 试图构建一个“模型>开发者>软硬件”三位一体的生态野心。

用开源低门槛吸引开发者布局上手,通过生产环境验证技术方案、推动标准化,甚至可能成为未来 AI 推理的通用范式。
这样就可以抢占 AGI 先机,一旦后续几天的开源项目设计更底层的训练框架或者多模态技术,DeepSeek 就有可能在通用人工智能赛道占据话语权。
这并不是信口开河,就在昨天,苹果就宣布与 Google Gemini 宣布合作,每个 AI 公司都希望成为未来的 AI 基座。
AI推理的极限仍未到头
FlashMLA 的发布不仅是一次技术突破,也揭示了 AI 行业的两个趋势。
首先是软硬件协同优化,FlashMLA 是针对 H800 的高效解码内核,让“特供”芯片有了更强表现,释放了更多算力潜能。
其次是开源,有了开源扩大影响力,但如何让企业级服务私有化部署、定制优化、实现盈利,依然是一个长期课题。

DeepSeek开源周的第一枪已打响,FlashMLA 用性能数据证明了国产 AI 技术的硬实力。若后续项目持续放大招,AGI的中国方案或将加速到来。
GitHub地址:https://github.com/deepseek-ai/FlashMLA


