

DeepSeek 再放降本大招:NSA 官宣发布,加速推理降低成本,并且不牺牲性能
2025-02-18
/ 阅读约1分钟
来源:IT之家
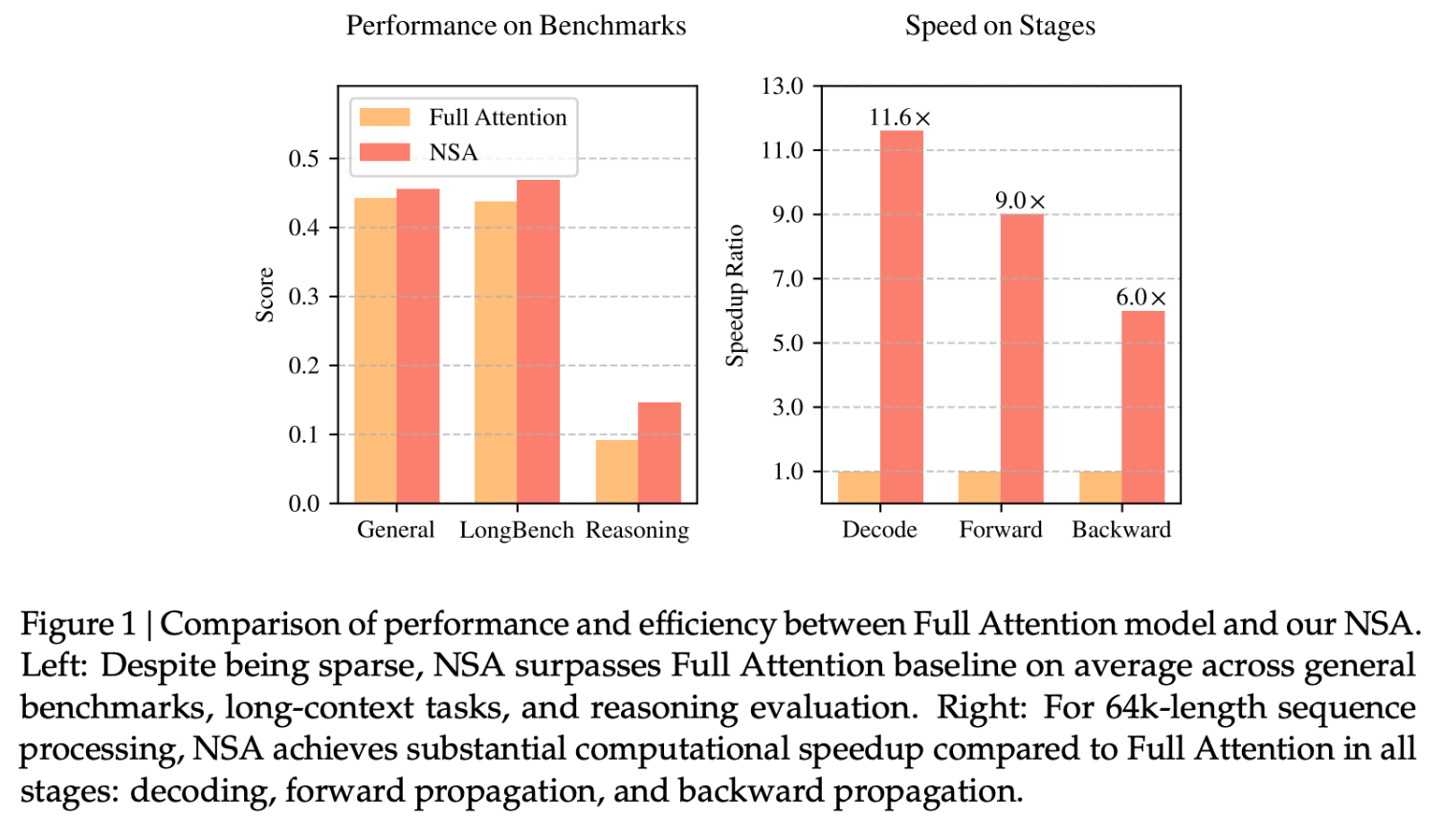
DeepSeek 官方表示,该机制可优化现代硬件设计,加速推理同时降低预训练成本,并且不牺牲性能。在通用基准、长上下文任务和基于指令的推理上,其表现与全注意力模型相当或更加优秀。
IT之家 2 月 18 日消息,DeepSeek 今日官宣推出 NSA(Native Sparse Attention),这是一种硬件对齐且原生可训练的稀疏注意力机制,用于超快速长上下文训练与推理。

NSA 的核心组件包括:
动态分层稀疏策略
粗粒度 token 压缩
细粒度 token 选择
DeepSeek 官方表示,该机制可优化现代硬件设计,加速推理同时降低预训练成本,并且不牺牲性能。在通用基准、长上下文任务和基于指令的推理上,其表现与全注意力模型相当或更加优秀。
IT之家附论文链接:
https://arxiv.org/abs/2502.11089


