

史上最大规模视觉语言数据集:1000亿图像-文本对!
什么概念?
较此前纪录扩大10倍。
这就是由谷歌推出的最新数据集WebLI-100B。

它进一步证明,数据Scaling Law还远没有到上限。
在英文世界之外的多元文化、多语言维度,1000亿规模数据集能更好覆盖长尾场景,由此带来明显性能提升。
这意味着,想要构建更加多元的多模态大模型,千亿级数据规模,将成为一个重要参考。
同时研究还进一步证明,CLIP等模型的过滤筛选步骤,会对这种多元性提升带来负面影响。
该研究由谷歌DeepMind带来,一作为Xiao Wang、 Ibrahim Alabdulmohsin。
作者之列中还发现了ViT核心作者翟晓华。2024年12月,他在推特上官宣,将入职OpenAI苏黎世实验室。
数据规模越大对细节理解越好
论文主要工作有三方面。
验证VLMs在1000亿规模数据集上的效果
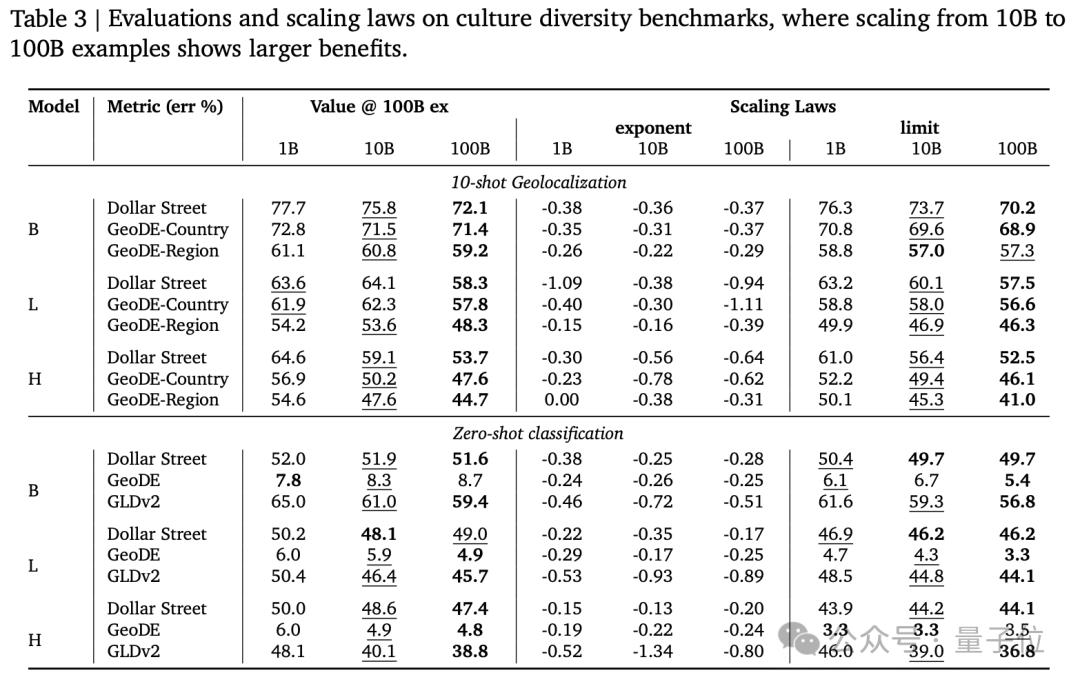
证明1000亿规模数据集能增强VLMs文化多样性、多语言能力以及减少不同子组之间的性能差异。
发现CLIP这类模型过滤筛选数据的过程会对无意中降低模型的文化多元性,在1000亿规模数据集上亦是如此。
具体来看,研究人员从网络上搜集了1000亿图像-文本对,初步去除有害内容以及敏感信息。
然后使用CLIP模型对数据集进行质量评估,筛选出与图像内容高度对齐的图像-文本对。
他们训练了一个分类器模型,对图像-文本进行对齐和错位分类,并调整阈值以重新筛选数据集。为了评估多语言能力,还使用网页的语言标签来确定数据集中的语言分布。
为了评估不同数据规模对模型性能的影响,研究人员从1000亿数据集中随机抽取了1%和10%的数据,分别创建了10亿和100亿规模的数据集。
同时为了提高低资源语言的代表性,研究人员对低资源语言进行了上采样,将它们的占比从0.5%提高到1%。
实验方面,研究人员使用SigLIP模型在不同规模的数据集上进行对比视觉语言预训练。
他们训练了不同大小的模型(ViTB/16、ViT-L/16、ViT-H/14),并使用了大规模的批量大小和学习率调度。
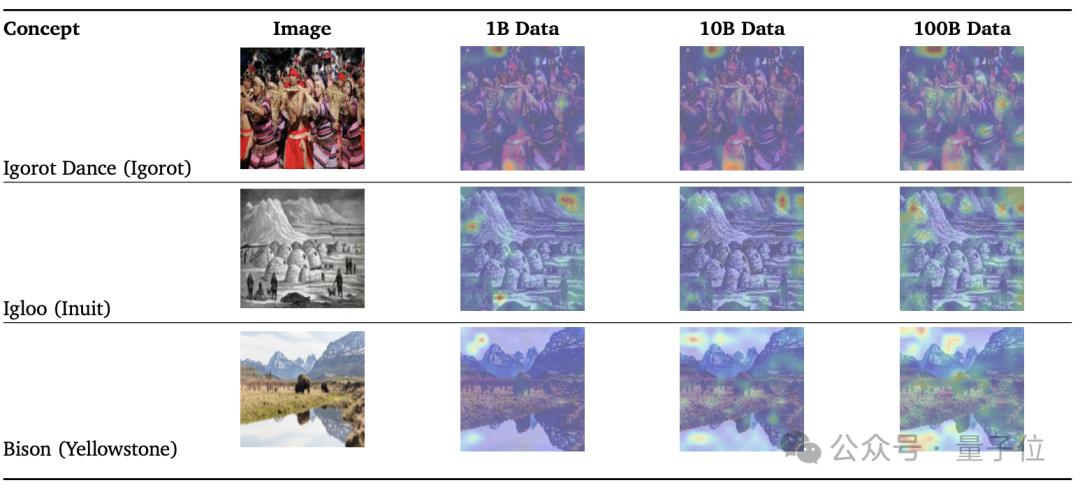
从结果来看,1B数据集训练的模型在注意力图上无法很好捕捉细节。10B数据集有所改善,100B数据集能更精准。
同时使用多语言mt5分词器对文本进行分词,并训练了多种语言的模型。
在模型评估上,研究人员主要进行以下几个维度分析:
传统基准测试:多个传统基准测试(如ImageNet、COCO Captions等)上评估。
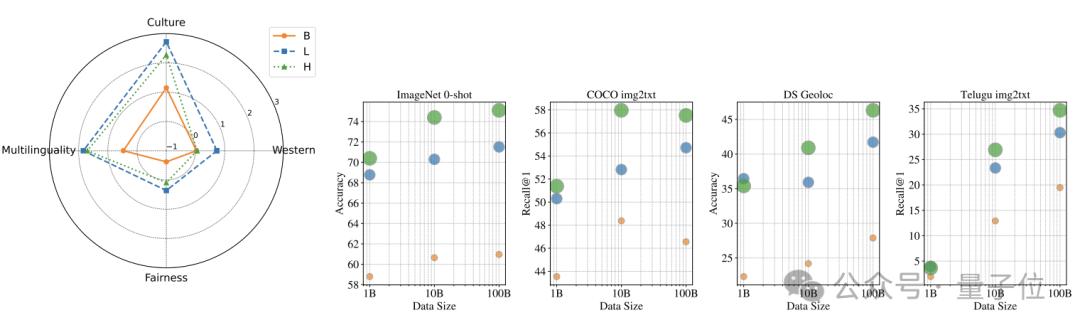
文化多样性:使用Dollar Street、GeoDE和Google Landmarks Dataset v2等数据集评估了模型在文化多样性任务上的性能。
多语言能力:使用Crossmodal-3600数据集评估了模型在多语言任务上的性能。
公平性:评估了模型在不同子组(如性别、收入水平、地理区域)上的性能差异,以评估模型的公平性。
结果显示,从100亿到1000亿规模数据,在以西方文化为主的传统基准测试上带来的提升比较有限,但在多语言能力和公平性相关任务上显著提高。
数据过滤可以提高模型在传统任务上的性能,但可能会减少某些文化背景的代表性,从而限制数据集的多样性。
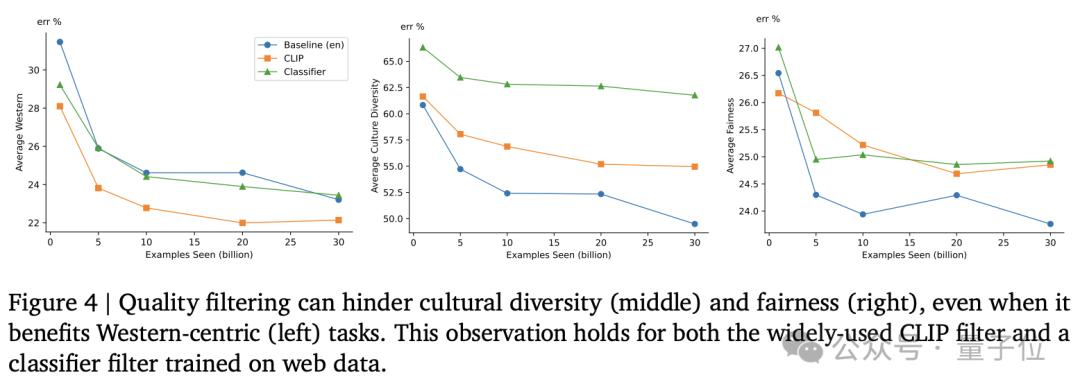
此外,通过调整低资源语言的混合比例,可以显著提高模型在低资源语言基准测试上的性能。

主创翟晓华已被OpenAI挖走
该研究的一作为Xiao Wang和Ibrahim Alabdulmohsin。
Xiao Wang本科毕业于南京大学,硕士毕业于北京大学。
领英资料显示,他毕业后先后任职于IBM中国开发实验室、网易有道。2015年加入谷歌DeepMind至今,职位是高级软件工程师,主要从事视觉语言研究。
主创中还发现了翟晓华的身影。
他同样本科毕业于南京大学,在北京大学攻读博士学位后,赴苏黎世加入谷歌。
翟晓华和卢卡斯·拜尔(Lucas Beyer)、亚历山大·科列斯尼科夫(Alexander Kolesnikov)一起在谷歌提出多项重要工作。
2021年,他们三人作为共同一作的计算机视觉领域神作ViT发布即刷新ImageNet最高分。
这项研究证实了CNN在CV领域不是必需的,Transformer从NLP跨界,一样可以取得先进效果。开创了Transformer在CV领域应用的先河。
目前这篇论文被引用量已超过5.3万。
他在谷歌DeepMind时领导苏黎世多模态研究小组,重点研究多模态数据(WebLI)、开放权重模型 ( SigLIP、PaliGemma )以及文化包容性。

2024年12月,爆料称OpenAI挖走ViT三大核心作者。随后,该消息被本人证实。
论文地址:https://arxiv.org/abs/2502.07617


