

三个月前,我们和中国科学院院士、清华大学计算机系教授张钹曾经聊过一个话题:“为什么在提高算法效率上中国人会做得更好?”
张钹告诉我们:“对中国企业来讲,算法效率是生命攸关的,我们必须全力以赴。也许因为美国人有强大的算力,算法效率对他们来说只是锦上添花而已。”
当时,我们对这句话感受还不是很深,直到后来看到了DeepSeek-V3技术报告里的这张表格。
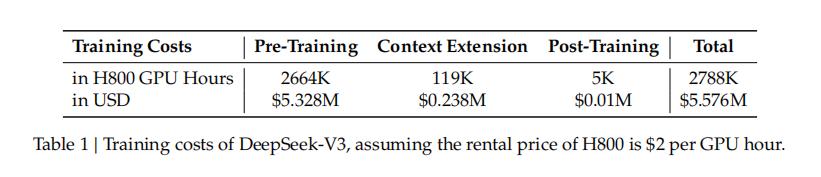
DeepSeek-V3的训练成本(假设H800的租赁价格为2美元/GPU小时),图片来源:DeepSeek-V3技术报告
简单来说,DeepSeek-V3仅使用了2048块英伟达H800 GPU,耗费了557.6万美元就完成了训练,相比同等规模的模型(如GPT-4、GPT-4o、Llama 3.1),训练成本大幅降低。
这样说没有错,但在复杂的舆论场中也引发了一些误读。比如,“中国AI企业用几百万美元的成本打败了美国AI企业数亿美元的投入”“成本仅为国外三十分之一,硅谷恐慌”。
这种误读有一些客观原因,因为OpenAI、Meta官方从来没有公布过GPT-4、GPT-4o、Llama 3.1的训练成本,多数人对模型训练成本构成也并不熟悉,但误读背后更多还是主观原因——情绪。
AI大模型领域,中国AI企业一直是一个“追随者”的角色,这次有了和硅谷巨头“掰手腕”的机会,就像霍元甲站上了与西洋力士的比武台,谁不想叫声好呢?
这种情绪本身没有错,但也在一定程度上模糊了DeepSeek团队在算法、框架和硬件上的优化协同设计的价值,而这正是DeepSeek-V3降本增效的关键。
01 训练成本差距是否有那么大?
我们查阅了技术报告,DeepSeek只公布了基座模型V3的训练成本,并没有公布推理模型R1的训练成本。
DeepSeek-V3技术报告显示,该模型的正式训练成本包括三个阶段:预训练(pre-training)、扩展上下文(context extension)、后训练(post-training),共计557.6万美元。
但是这557.6万美元的训练成本并不包括前期研究以及关于架构、算法或数据的消融实验所产生的成本。
前期研究、消融实验属于“隐性成本”,但不容忽视。
在一个AI企业正式训练一个模型之前,需要进行大量的前期研究,包括对算法的理论研究、对硬件性能的探索、对数据集的分析等。
而消融实验(Ablation Study)是一种在机器学习和深度学习中广泛使用的分析方法,用于评估模型各个组件或特征的重要性及其对模型整体性能的影响。
消融实验就像是在玩“减法游戏”或者“排除法”,通过逐一移除或修改模型的某些部分,观察模型性能的变化,从而确定每个部分的相对重要性。
另外,在训练模型之前还会有一定的试错成本。
为什么说这些成本是“隐性成本”?
因为大模型前期研发往往分散在数月甚至数年中,难以量化统计;消融实验可能反复进行,但最终仅保留最优方案,失败案例的成本常被忽视;企业通常不会公开内部研发细节(如试错次数),导致外部估算会产生偏差。
除了“隐性成本”,不同的成本计算方式也会产生不一样的结果。
DeepSeek-V3这557.6万美元训练成本是怎么计算的呢?按照DeepSeek-V3技术报告的逻辑,我们简单列了一个公式:
训练耗费的时长(GPU小时)×H800每GPU小时的租赁价格(美元)=DeepSeek-V3训练成本(美元)
正式训练耗费的时长包括:预训练阶段耗费266.4万(2664K)GPU小时,扩展上下文长度阶段耗费11.9万(119K)GPU小时,后训练阶段耗费0.5万(5K)GPU小时,因此DeepSeek-V3的正式训练共耗费278.8万(2788K)GPU小时。
而DeepSeek在技术报告中假设H800每GPU小时的租赁价格为2美元,这样DeepSeek-V3训练成本就是:
2,788,000×2=5,576,000(美元)
需要注意的是,这里是按GPU小时而不是GPU个数计算,单价是按GPU租赁价格计算而不是GPU购买价格计算。
换种方式计算训练成本,结果就会很不一样。
比如,为了训练Llama 3.1 405B,Meta使用了超过1.6万个英伟达H100 GPU,如果按照H100 GPU的购买价格计算,这样计算下来的训练成本就已高达数亿美元。
我们也可以按照DeepSeek-V3一样的租赁逻辑计算。
尽管Meta没有透露Llama 3.1具体的训练成本,但是其技术报告显示,Llama 3.1 405B的预训练(此处说的是预训练时间而非完整训练时间)为54天。那么,Llama 3.1 405B预训练阶段耗费的GPU小时为:
天数×24小时×H100 GPU个数=预训练阶段耗费的GPU小时
54×24×16,000=20,736,000
Llama 3.1 405B是2024年7月推出的,如果按照2024年初海外市场H100 GPU每GPU小时的租赁价格2.8美元(参考价格,会浮动)计算,那么其预训练成本约为5800万美元。相比之下,DeepSeek-V3的532.8万美元预训练成本的确是大幅降低了。
而OpenAI官方从来没有公布过其训练成本,但是我们可以从侧面推算。
英伟达CEO黄仁勋在NVIDIA GTC 2024主题演讲中介绍,如果要训练一个有1.8万亿参数的GPT模型,用Hopper(H100)的话,需要约8000个GPU,耗电15兆瓦,用时90天,大约需要三个月。
虽然黄仁勋没有明说,但根据此前多个渠道的爆料信息,这个1.8万亿参数的GPT模型就是GPT-4。

黄仁勋在NVIDIA GTC 2024 主题演讲,图片来源:英伟达B站账号
黄仁勋在演讲中解释道:“这样就可以训练出这种开创性的AI模型,这显然没有人们想象中那么昂贵,但是8000个GPU仍然是一大笔投资。”
我们同样可以按照租赁逻辑估算一下与GPT-4规模相当模型训练成本。为什么说估算?因为H100是2022年3月发布的GPU,但实际大规模供货和云服务商部署通常在2022年底至2023年初才开始,而GPT-4在2023年3月发布,所以GPT-4的训练更多还是依靠A100。
假设在2024年初,也就是黄仁勋发表演讲之前,训练一个与GPT-4规模相当的大模型,其训练成本是:
天数×24小时×H100 GPU个数=训练阶耗费的GPU小时
90×24×8,000=17,280,000(小时)
训练耗费的GPU小时×H100每GPU小时的租赁价格=训练成本
17,280,000×2.8=48,384,000(美元)
大约4800万美元的训练费用,的确如黄仁勋所说“没有人们想象中那么昂贵”。
而据SemiAnalysis在2023年7月发布的分析报告,OpenAI在GPT-4的训练中使用了约2.5万个A100GPU,训练了90到100天,利用率(MFU)约为32%至36%,这种极低的利用率部分是由于大量的故障导致需要重新启动检查点。如果每个A100 GPU的使用成本大约为每小时1美元,那么仅此次训练的成本将达到约6300万美元。

图片来源:SemiAnalysis
DeepSeek-V3对标的Claude 3.5 Sonnet的训练成本又是多少呢?此前Anthropic也没有公布Claude 3.5 Sonnet的训练成本,但Anthropic CEO达里奥·阿莫迪(Dario Amodei)近期在一篇评价DeepSeek的文章中透露,Claude 3.5 Sonnet训练成本在数千万美元(cost a few $10M's to train),他还特意说:“我不会给出具体的数字。”
“A few”在英语里通常指3到5个,所以我们估计Claude 3.5 Sonnet的训练费用在3000万到5000万美元之间。
我们统一按照DeepSeek-V3的GPU租赁逻辑计算,不考虑其他“隐性成本”,可以发现,DeepSeek-V3的训练成本相比其对标模型训练成本大幅降低,但没有到某些人说的“几十分之一”的夸张程度。
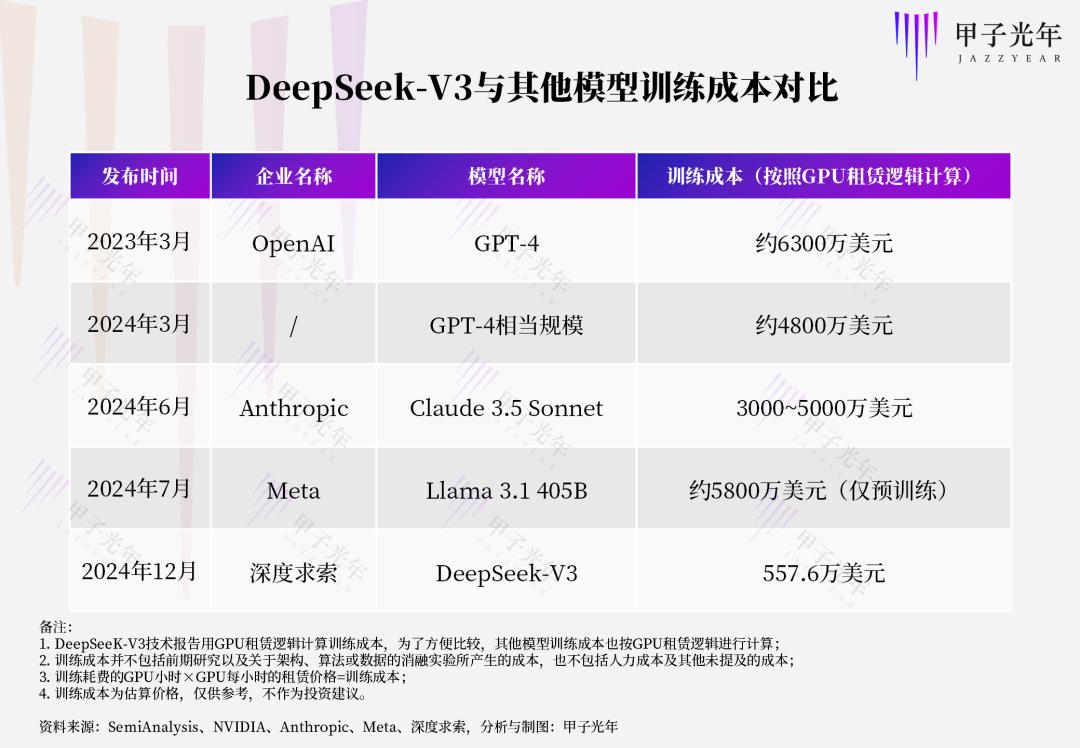
需要注意的是,随着技术和市场的发展,GPU租赁价格的降低使得企业和研究机构能够以更低的成本配置更多的GPU,从而让模型训练降本增效。
企业还可以用更先进的GPU降低训练的能耗。
还记得黄仁勋举的例子吗?如果要训练一个有1.8万亿参数的GPT模型,用Hopper(H100)的话,需要约8000个GPU,耗电15兆瓦,用时90天;如果用Blackwell(GB200)的话,需要2000个GPU,耗电仅需4兆瓦,约为Hopper的四分之一。

图片来源:英伟达
这是先进GPU带来的效率提升,但是国内AI企业由于管控,无法获得最先进的GPU,又是靠什么来实现降本增效呢?
Meta技术报告显示,Llama 3.1 405B的预训练时长54天,使用了15万亿(15T)的tokens以及1.6万个英伟达H100 GPU进行训练。
DeepSeek-V3在预训练阶段,使用了14.8万亿(14.8T)的tokens进行训练,预训练耗时也是54天,DeepSeek-V3技术报告里也说的是“不到两个月”:
预训练阶段耗费的GPU小时÷H800 GPU个数÷24小时=天数
2,664,000÷2048÷24≈54(天)
但是,DeepSeek-V3仅使用了2048块英伟达H800 GPU,尽管可能存在利用率的差异,但这与Llama 3.1 405B训练使用的1.6万个英伟达H100 GPU形成了鲜明对比。而且H800是英伟达为了满足出口限制而设计的GPU,性能低于H100。
也就是说,DeepSeek-V3在GPU比Llama 3.1 405B用得少,GPU性能也更弱的情况下,在相同的时间,完成了与Llama 3.1 405B差不多的训练量。
DeepSeek-V3技术报告里的这句话“DeepSeek-V3每训练一万亿(trillion)个token仅需18万(180K)H800 GPU小时”成为了关键。
DeepSeek-V3大幅提升了模型训练效率。
02 DeepSeek如何降本增效?
DeepSeek-V3是一个混合专家模型 (Mixed Expert Models,以下简称MoE) ,旨在通过整合多个模型或“专家”的预测来提升整体模型性能。
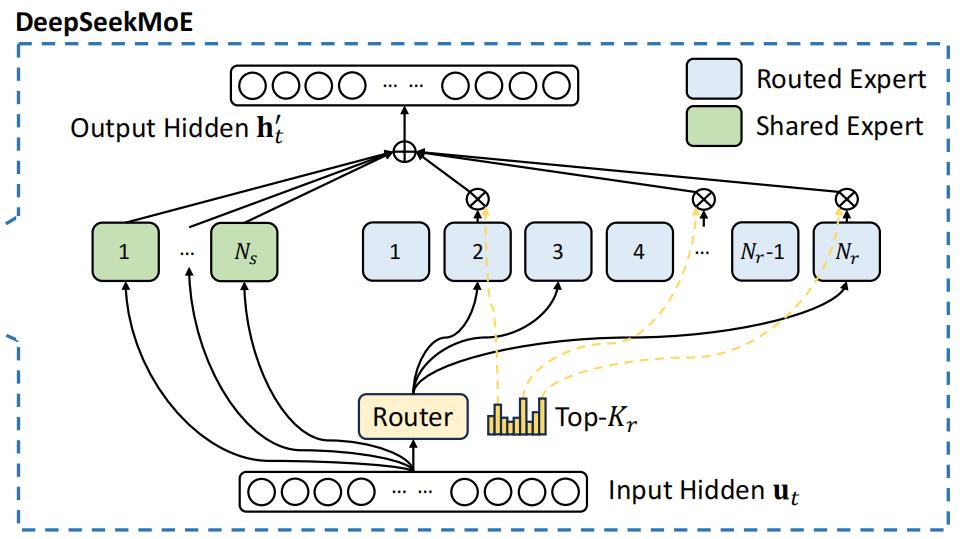
图片来源:DeepSeek-V3技术报告
清华大学计算机系长聘教授、高性能计算研究所所长翟季冬在《夜话DeepSeek:技术原理与未来方向》直播中介绍,之前发布的一些MoE模型,采用的是“专家数很少、每个专家很大”的架构,但是DeepSeek采用的是“大量细粒度的专家”。
“大量细粒度的专家”可以更灵活地处理各种输入数据,提高模型的适应性和泛化能力。由于每个专家的规模小,计算效率更高,训练和存储成本也相对较低。不过,由于专家数量众多,可能会导致模型的管理和调度变得更加复杂。
翟季冬分析,为了提升DeepSeek-V3的模型训练效率,DeepSeek团队在四个方面进行了优化,分别是:负载均衡优化、通信优化、内存优化、计算优化。
首先是负载均衡优化。在MoE架构中,负载均衡指的是将输入数据合理分配给各个专家,使得每个专家都能充分发挥其性能,同时避免某些专家过度负载而其他专家空闲。
负载均衡是MoE训练中的非常大的挑战,如果处理不好,那么模型在一个大规模GPU集群训练时,利用率就很难提升上去。
DeepSeek团队为了解决负载均衡的挑战,创新提出了“Auxiliary-loss-free(无辅助损失)”负载均衡方案。
在传统的MoE中,为了保证各个专家的负载均衡,通常会引入一个Auxiliary Loss(辅助损失)。这个Auxiliary Loss会强制让每个专家处理的任务量尽量均匀。但它可能会让模型在优化过程中过于关注负载均衡,而忽略了模型本身的性能。
而DeepSeek的Auxiliary-Loss-Free方案,不依赖额外的辅助损失,而是在每个token的专家分配过程中直接施加一个bias(偏差值)来实现负载均衡,从而实现动态调整专家的负载。
由于这种bias的引入已经在专家选择的过程中起到了调控作用,使得各专家之间的token分配趋向均衡,因此就不再需要设计和调节额外的辅助损失项来“强制”负载平衡。这不仅简化了训练目标,也避免了因辅助损失权重设置不当而可能引入的训练不稳定问题。
简单来说,这就类似红绿灯路口,Auxiliary loss就是固定时长的红绿灯,车流量大了,路口通行效率会降低;而Auxiliary-Loss-Free中的bias就是可以根据实时车流量动态调整时长的红绿灯,基于当前状态(交通流量或专家负载)动态调整资源分配,以达到整体平衡和高效利用。
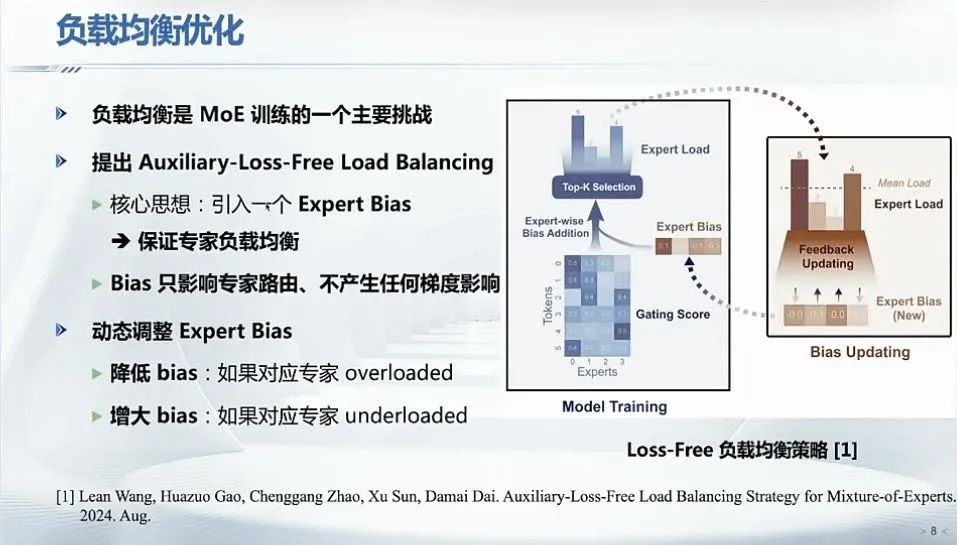
负载均衡优化,图片来源:翟季冬,《夜话DeepSeek:技术原理与未来方向》
第二是通信优化。在MoE训练中,使用专家并行会引入非常大的All to All通信开销。
什么是All to All通信开销?
假设在一个MoE中,有10个专家,每个专家被放置在一个独立的计算节点上。在训练过程中,每个专家需要与其他所有专家进行数据交换,以更新模型参数和同步训练状态。这种情况下,每个节点都需要与其他9个节点进行通信,形成了All to All的通信模式。随着专家数量的增加,通信开销也会显著增加,导致训练效率下降。
DeepSeek-V3就包括1个共享专家和256个路由专家,它采用的并行训练策略:16路流水线并行、64路专家并行,跨8个物理节点。
DeepSeek团队为了降低通信开销,提出了DualPipe算法。
DualPipe算法的核心创新就是能够将计算和通信阶段重叠进行。在传统的训练过程中,计算和通信是分开进行的,这会导致GPU在等待数据传输时出现空闲期,即所谓的 “流水线气泡”(pipeline bubbles)。DualPipe算法通过确保在一个微批量(micro-batch)被计算的同时,另一个微批量可以进行通信,精细地编排计算和通信,从而最大限度地减少这些空闲期,提高GPU的利用率。

通信优化,图片来源:翟季冬,《夜话DeepSeek:技术原理与未来方向》
DualPipe算法还采用了双向流水线机制,同时从流水线的两端处理微批量。这种策略确保了在整个训练过程中GPU始终保持活跃。通过这种方式,DeepSeek能够保持良好的计算与通信比例,减少延迟,提高吞吐量。
“这里有一个需要注意的点,如果采用双向流水线,要在GPU显存里存两份模型参数。大模型训练内存使用非常重要,为了解决这个问题,它采用了64路的专家并行,双流水可以非常有效地降低流水线bubble。”翟季冬说。
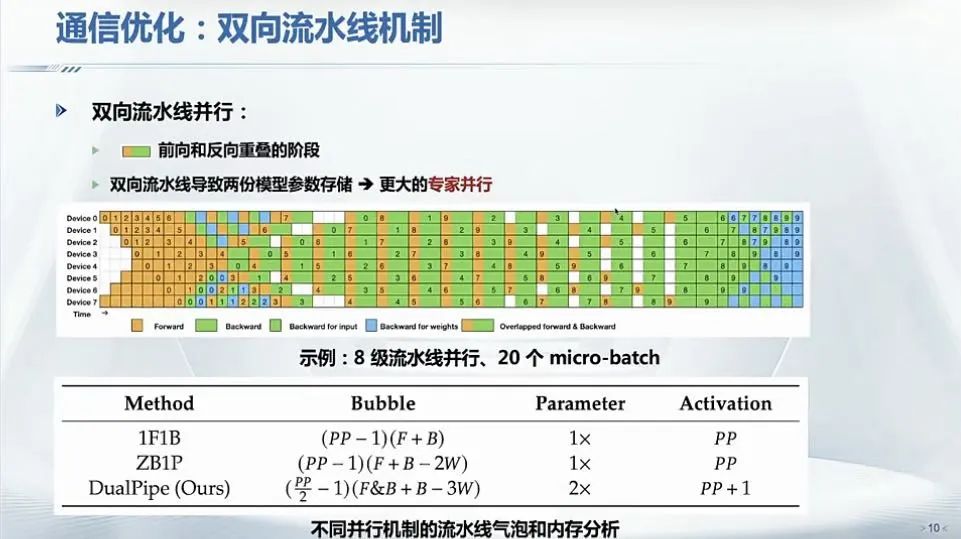
通信优化,图片来源:翟季冬,《夜话DeepSeek:技术原理与未来方向》
此外,DeepSeek的通信优化还包括跨节点通信优化以及Warp Specialization技术。

通信优化,图片来源:翟季冬,《夜话DeepSeek:技术原理与未来方向》
第三是内存优化。包括了重计算、使用CPU内存和参数共享。
大模型训练往往存在显存瓶颈。重计算的核心思想是在前向传播过程中,只保留少量关键的中间结果,而将其余的中间结果释放掉。当在反向传播过程中需要用到这些已释放的中间结果时,再重新执行前向传播中的相应部分来计算得到。这种方法通过增加一定的计算量,显著降低了内存消耗,是一种“以时间换空间”的策略。
这可以理解为一种在大模型训练过程中“偷懒”的技巧。
同时,DeepSeek还把一些数据,包括像模型参数的指数移动平均(EMA),存到CPU内存,从而节约GPU显存;将主模型与MTP(Multi-Token Prediction)模块的output head和embedding部署在相同节点,最大化地共享参数空间。
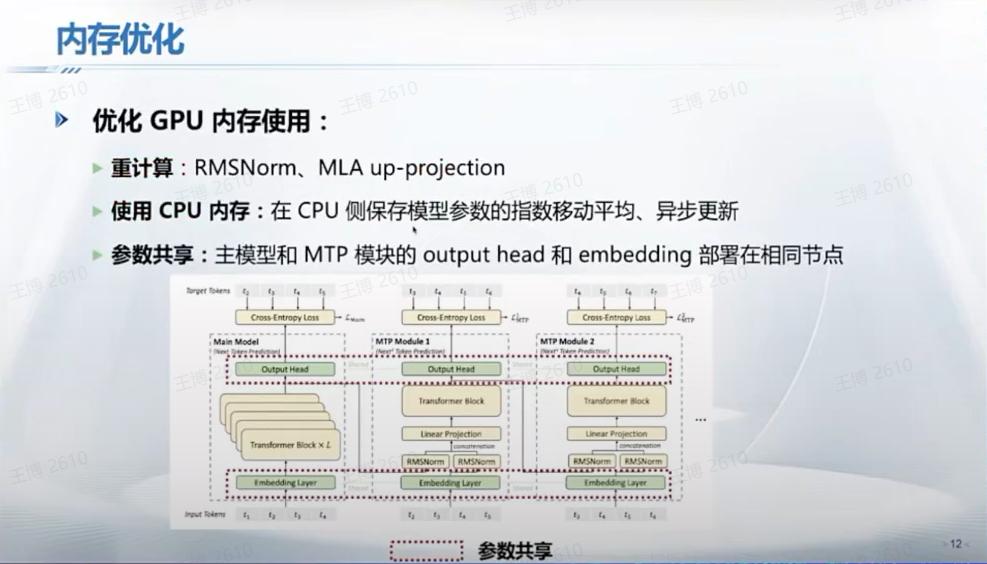
内存优化,图片来源:翟季冬,《夜话DeepSeek:技术原理与未来方向》
第四是计算优化。为了提升训练效率,DeepSeek采用了混合精度训练策略。
DeepSeek引入了英伟达FP8混合精度训练框架,并首次在超大规模模型上验证了其有效性。通过支持FP8计算和存储,DeepSeek实现了加速训练和减少GPU内存使用。FP8训练在相同加速平台上的峰值性能显著超越FP16/BF16,并且模型参数越大,训练加速效果越好。
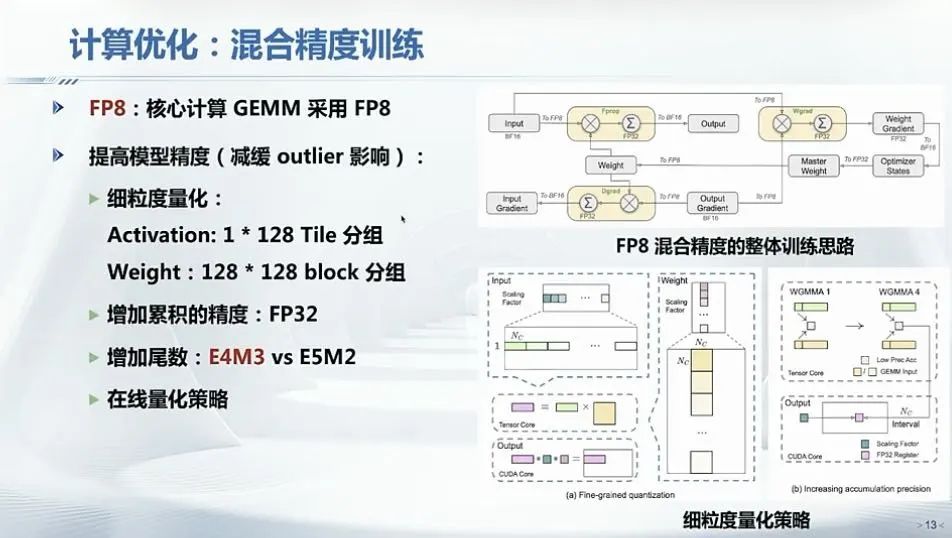
计算优化,图片来源:翟季冬,《夜话DeepSeek:技术原理与未来方向》
总的来说,翟季冬认为:DeepSeek充分挖掘了算法、软件、硬件性能,实现了协同创新;其软件相对灵活,软件赋能硬件,弥补了硬件的很多限制;优秀的系统软件能够充分释放底层硬件的潜力。
DeepSeek正是通过这一步步的优化,让整个模型的训练效率得到提升,并降低训练成本。
03 “小米加步枪”式的成功
经历了春节假期的喧嚣,我们对于DeepSeek的讨论应趋向理性。
我们不应神话DeepSeek,也不要因为外部的贬低而看轻DeepSeek,这些都对DeepSeek团队不公平。其实,DeepSeek就是一种“小米加步枪”式的成功。
行云集成电路创始人季宇最近跟我们聊起DeepSeek时说,创新的意识其实国内根本不缺,但缺乏Known-Why的创新往往会走向类似赌徒的歧途。
“创新不是简简单单的不一样的技术路线,国内其实不缺乏创新性和天马行空的想象,其实无论AI行业还是算力芯片行业,都有无数走非Transformer架构、走非GPU架构、非冯诺伊曼架构的差异化路线,但是基本都陷入了用差异化的技术路线主流技术路线替代品的逻辑里。”季宇说。
但是DeepSeek的创新是一步一个脚印的。
季宇告诉我们,第一性原理思考问题很多人都在讲,但实际上非常困难。第一性原理需要深入推敲,需要对每个论断的边界条件,需要深入考虑各个层级技术的细节。
“之前跟在DeepSeek的一个师弟交流,梁老板(DeepSeek创始人梁文锋)对他写的CUDA Kernel里每个线程具体在干什么事情都非常清楚,只有这样才能从全局视角去思考突围的方式,真正把创新做成。”季宇说。
这一点在另一位投资人那里也得到了印证。这位投资人去年曾问DeepSeek的人:“为什么你们的模型做得好?”
DeepSeek的人回答,因为我们老板自己在读论文、写代码、搞招聘。
关于DeepSeek的成功,你可以说他们有丰富的GPU储备,可以说他们对模型架构进行了创新,但其成功内核往往是朴实而简单的。
DeepSeek创始人梁文锋去年接受《暗涌》采访时说过的一句话,既谦虚又意味深长。
他说:“我们不是有意成为一条鲶鱼,只是不小心成了一条鲶鱼。”
**参考资料:
DeepSeek-V3 Technical Report,DeepSeek
The Llama 3 Herd of Models,Meta
GPT-4 Architecture, Infrastructure, Training Dataset, Costs, Vision, MoE,SemiAnalysis
《夜话DeepSeek:技术原理与未来方向》,中国计算机学会青年计算机科学与技术论坛(CCF YOCSEF)


