

01 钱老之问,DeepSeek之答
1995年,钱老在一封信中发问:
“回想在60年代,
1.我国理论物理家提出基本粒子的“层子”理论,它先于国外的“夸克”理论。
2.我国率先人工合成胰岛素。
3.我国成功地实现氢弹引爆的独特技术。
4.我国成功地解决了大推力液体燃料氧化剂火箭发动机燃烧稳定问题。
5.其它。
但是今天呢,我国科学技术人员有重要创新吗?我认为我们太迷信洋人了,胆子太小了!我们这个小集体,如果不创新,我们将成为无能之辈!”

“但是今天呢?”这一叩问,在今天有了回响。钱老在90年代给出了他的回答,今天的DeepSeek梁文锋给出了相似的回答:
“创新首先是一个信念问题,也就是敢。”
为什么不敢?甚至可能都没有想过敢不敢的问题,质疑就冒出来了:“为什么培养不出创新人才”、“为什么国内鲜有核心科技和自主创新”,这些怀疑、这些语言本身,就是对创新基因的“锁链”。这同样成了惯性思维的病症:
技术自卑症:迷信西方技术权威,依赖“跟随策略”,但把跟随、逆向工程简化为“抄袭”,是一种偏见。但哪一个天才发明家,不是从拆玩具起家的呢?
人才偏见论:将义务教育成果,简化为“做题机器”,但是忽视其培养的“在受限条件下寻求最优解”的能力,在不断的压力测试下练就的抗挫能力。
失败恐惧链:用“资本退出”绑架研发风险,用短线KPI挟持长期探索和长期投入,导致走向“只敢模仿、不敢重构“,”只谈应用、不碰底层”的保守倾向。
但是,过去的整整30年,中国的“小镇做题家”申公豹们、“天之骄子”学霸敖丙们,以及“看起来毫不费力”的学神哪吒们,已经在亲手书写全新的答案。

02 被低估的“解题家”
鲜少有人意识到:在中国教育极致约束条件下,进化出了一个“学神群体”,他们很有可能走向突破性创新。
应试同时充当了一个“反脆弱训练”,有着高压的筛选机制。可能从中学开始,他们可能在高密度竞争中依靠自学超前学习,选择性听课,用20%的时间掌握80%的知识,攻克高难度竞赛领域。
从“五大学科竞赛”到清北等一系列顶级名校的少年班,中国基础教育用严苛的选拔体系,筛选出能在资源少、问题多的环境下多学科发展的“极限生存者”和“最强大脑”。
而当考试变为科研,他们发现“自己定义答案”远比写出标准解更令人兴奋。公开资料显示,DeepSeek核心团队成员包括多位国际学科竞赛获奖者,这正是典型代表。
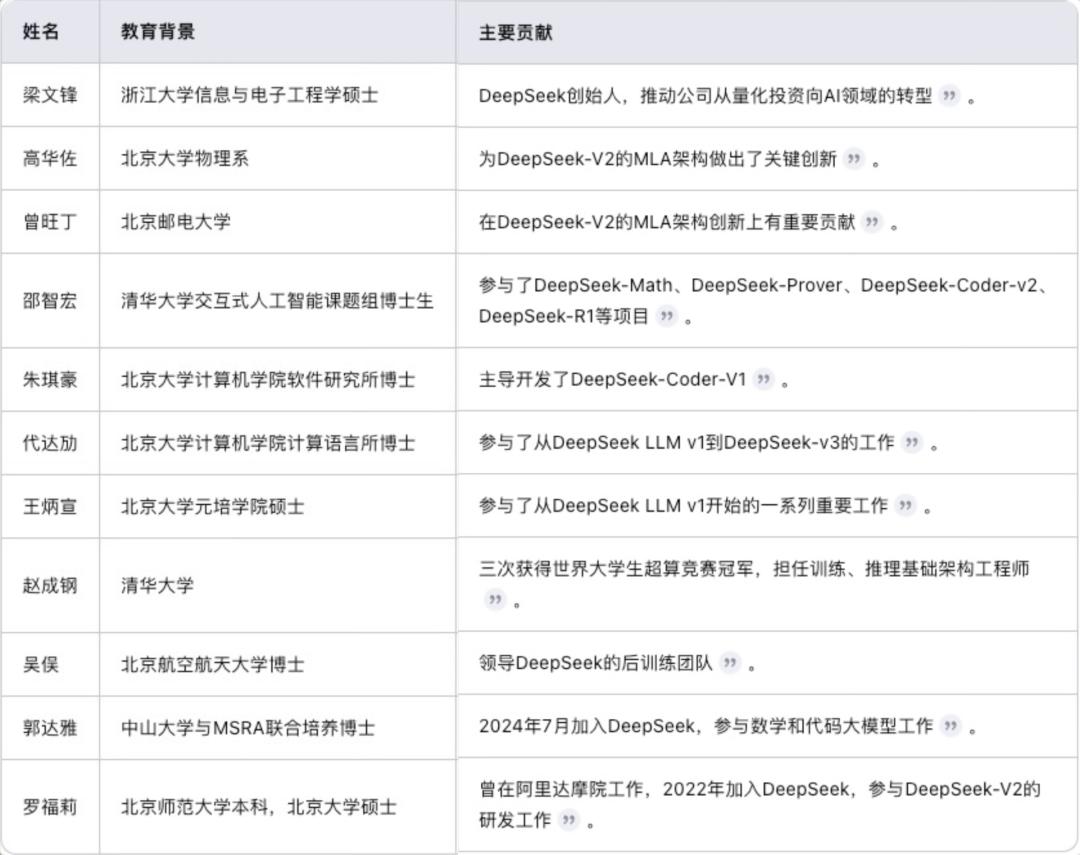
硅谷津津乐道的“天才现象”,比如,GPT之父的Alec Radford 在30岁出头就引入Transformer做语言模型生成与训练,奠定了现代AI发展的理论基础; 其实在中国拥有更庞大的基数,但很多人可能从来没有相信过。
我们看DeepSeek的团队,呈现出三大特征:
年龄小:核心成员平均年龄不到30岁,V3论文第一作者入职时仅为研二学生。团队均来自我国本土顶尖高校的应届博士毕业生、在读生以及硕士生;
经验少:刻意避开“大厂履历者”,选择未被行业范式驯化的“新鲜”大脑;
酷爱难题:将“大模型训练”拆解为数百个具体问题(如KV Cache内存墙、MoE路由效率),每个问题就像奥赛的关卡,他们对最优解有着天然的饥渴。
这种人才策略的底层逻辑,与钱学森在“两弹一星”工程中启用邓稼先(34岁任原子弹理论设计负责人)、于敏(国产土专家1号)的思路有类似之处。

即便在没有资源、时间紧、任务重的压力测试下,没有实战经验的最强大脑,都能突破跨越式创新。而当下的物质条件,已经让天之骄子们大胆地追随自己的热爱了,往无人之境上迈进,与全球的超一流智力去比拼、去对弈、去交流,何尝不令人心潮澎湃。
梁文锋在采访中说:国内人才很多,但顶尖人才在中国是被低估的,因为整个社会层面的硬核创新太少了,使得他们没有机会被识别出来。我们创新缺的肯定不是资本,而是缺乏信心,以及不知道怎么组织高密度的人才,实现有效的创新。
DeepSeek的启示远超技术范畴,它预示着一场更深刻的思想解放。锁住人的,往往是自己的限制性信念。
这自然不是赞扬应试,那同样是一个有限条件下、带着复杂目的的产物。只是我们要看到,“一阴一阳谓之道”,游戏规则是死的,但人是活的。不能妄自菲薄、而忽视了主观能动性。

03 思想钢印,破壁时刻
能够在AI大模型创新中“上桌”,DeepSeek背后是中国式创新的独特路径:既非对硅谷的简单复制,也非举国体制的简单翻版,而是过去30年中西方教育糅合重组的“奇妙产物”。
西方精英往往会在初到中国时感到震惊,但中国只要受过高等教育的莘莘学子,往往对西方文化是保持谦逊学习的姿态。
这也就带来了一种“杂交产物“,而且在反向的美对中、强势文明对弱势文明的视角中,是不可能存在的。
也由此,产生了一些化学反应。

1. 东方哲学“同一性”与第一性原理的交织
当硅谷工程师还在技术选型中纠结时,DeepSeek的年轻人直接重写规则:MLA将KV Cache内存占用压降90%,GRPO砍掉冗余的Value Model,DeepSeekMoE重构专家路由逻辑……这些突破背后,都藏着东方哲学与第一性原理的奇妙共振。
R1-Zero实验中,团队大胆抛弃人类标注数据,跳过传统的微调步骤,让模型通过自我博弈进化思维能力。这完全打破了OpenAI为代表的大模型主流路径。
当西方AI困于Transformer、GPT、AlphaZero的范式内卷时,DeepSeek开始直面更本质的哲学命题。这就是所谓的“第一性原理”、”批判性思维“和”think out of the box“的产物。

R1-Zero尝试让模型脱离标注数据自我演进,GRPO将强化学习简化为“直觉驱动”。深挖这些思路,可以看到东方哲学的“同一性”,道生一,一生二。既然思维有同一个妈,那就不需要老大来教老二,老二同样可以自己参悟(这里简化仅做个类比)。
DeepSeek团队在论文中流露的兴奋,与钱学森当年提出跨学科的“工程控制论”时,状态何其相似。他们在用技术解答“学习是什么”“思维如何涌现”等元问题,而这些居然一以贯之地在理论与实践中达到统一,才是研究的终极浪漫。
当更自觉地走向“第一性”,与“第一性”合一。或许真正的智能并不是人工规则的提线木偶,而已经走向混沌中自主涌现。
2. 软硬件“整体观”与最全供应链的共振
让中国创新实现的秘诀,还藏在改革开放40年锻造的“超级供应链”中。从新能源车的弯道超车到大模型的破局,背后都有着相似的逻辑。
当被戏称为“外星人”的马斯克,用“外星战舰”形容上海超级工厂时,他看到的不仅是速度,更是中国供应链“无缝耦合”的能力——从电池、电机到车机系统,90%以上的零部件,都能在上海500公里、也就是4小时车程的半径内,完成整合。

只有这里才能快速实现马斯克近乎“变态”的要求,实现造车一体化的压铸。而这种能力,在AI领域更为显性:
DeepSeek V3自研的HAI训练框架,大幅降低了训练过程中的GPU内存需求和存储带宽压力,更好适配国产算力卡。
DualPipe算法实现计算与通信的重叠,适配华为昇腾通信协议,能实现高效的流水线并行,减少通信延迟。
FP8训练框架混合精度量化,也大幅降低训练过程中的GPU内存需求和存储带宽压力,加上昇腾AI通过自动混合精度技术,实现模型加速执行,更好适配中芯国际制程工艺。
在基于共同目标的技术攻坚下,软硬件供应商完全成为一体化作战的“军团”,以阵地战攻下一个又一个战略要地。当硅谷巨头们还在为“模块化分工”扯皮时,中国军团已经悄咪咪地攻城略地。
道路是曲折的,但一定要相信前途是光明的。

04 星火燃亮时
DeepSeek的出现,已经改写了AI大模型发展被奉为圭臬的一些认知,同时击碎了很可能“锁住”一些年轻人的思想钢印:
从“追随范式”到“定义范式”:当MLA架构被英伟达纳入下一代GPU设计参考时,中国在AI基础设施层获得规则定义;
从“人才输出”到“反向吸引”:曾被视为“硅谷后备工程师”的中国学神们,开始吸引全球顶尖学者加入DeepSeek的“约束条件创新挑战”;
从“技术应用”到“哲学输出”:R1-Zero项目中展现的“自主智能涌现”思想,正在引发全球AI界对“人类与机器认知边界”的重新思考。
当思想钢印被击碎,那些在黄冈密卷、奥赛考场、实验室中磨砺出的年轻的中国大脑,也必将在人类文明的试卷上留下新解。
我们正在走向一片被迷雾笼罩的荒原,一片人类还未曾踏足的处女地。没有标准答案,没有现成路径,我们只能点燃手中的火把,从容地走向未知。
就像曾经的人类那样。


