

春节至今,DeepSeek的热度持续攀升,伴随而来的,还有很多误解和争议,有人说它是"吊打OpenAI的国货之光",也有人说它"不过是抄国外大模型作业的小聪明"。
这些误解与争议主要集中在五个方面:
1、过度神话与无脑贬低,DeepSeek到底是不是底层创新?所谓的蒸馏ChatGPT之说究竟有没有依据?
2、DeepSeek的成本,真的只有550万美元吗?
3、如果DeepSeek真的能做到这么高效,那么全球各大巨头巨额的AI资本支出,是不是都打了水漂?
4、DeepSeek是否采用了PTX编程,能否真的能够绕开对Nvidia CUDA的依赖?
5、DeepSeek全球爆火,但因为合规、地缘政治等问题,会被国外陆续禁用?
1
过度神话与无脑贬低
DeepSeek到底是不是底层创新?
互联网从业者caoz认为,它对行业发展的促进价值是值得肯定的,但谈及颠覆还为时尚早。一些专业测评来看,在一些关键问题的解决上并没有超越ChatGPT。
比如有人测试,模拟典型的小球在封闭空间的弹跳代码,DeepSeek编写出来的程序表现,和ChatGPT o3-mini相比,从物理学的遵循度角度来看,还是有差距的。
不要过度神话它,但也不要无脑贬低它。
关于DeepSeek的技术成就,目前存在两种极端观点:一种把它的技术突破,称为"颠覆性革命";另一种则认为这不过是对国外模型的模仿,甚至还有猜测,它是通过蒸馏OpenAI模型获得进展。
微软说DeepSeek蒸馏了ChatGPT的结果,所以一些人也借题发挥,把DeepSeek贬低的一钱不值。
事实上,这两种观点都过于片面。
更准确地说,DeepSeek的突破是一次面向产业痛点的工程范式升级,为AI推理开辟“少即是多”新路径。
它主要做了三个层面的创新:
首先通过训练架构瘦身——例如GRPO算法通过省去传统强化学习中必须的Critic模型(即"双引擎"设计),将复杂算法简化为可落地执行的工程方案;
第二,采用了简评估标准,典型如在代码生成场景直接用编译结果和单元测试通过率替代人工评分,这种基于确定性的规则体系有效破解了AI训练中的主观偏差难题;
最后在数据策略上找到精妙平衡点,通过纯算法自主进化的Zero模式与仅需数千条人工标注数据的R1模式组合,既保留模型自主进化能力又保障人类可解释性。
但是,这些改进并没有突破深度学习的理论边界,也没有彻底颠覆OpenAI o1/o3等头部模型的技术范式,而是通过系统级优化解决了产业的痛点。
DeepSeek完全开源并详细记录了这些创新点,全世界都能借助这些进展来改进自己的AI模型训练。这些创新点可以从开源文件中看出。
Stability AI前研究主管Tanishq Mathew Abraham在近期的博文中也强调了DeepSeek的三个创新点:
1、多头注意力机制:大语言模型通常是基于Transformer架构,使用所谓的多头注意力(MHA)机制。DeepSeek团队开发了一种MHA机制的变体,这种机制既能更高效地利用内存,又能获得更好的性能表现。
2、可验证奖励的GRPO:DeepSeek证明了一个非常简单的强化学习(RL)流程实际上可以达到类似GPT-4的效果。更重要的是,他们开发了一种称为GRPO的PPO强化学习算法变体,这种算法更加高效且性能更好。
3、DualPipe:在多GPU环境下训练AI模型时,需要考虑很多效率相关的因素。DeepSeek团队设计了一种称为DualPipe的新方法,这种方法的效率和速度都显著提高。
传统意义上的"蒸馏"指的是对token概率(logits)的训练,而ChatGPT并未开放这类数据,所以基本不可能去“蒸馏”ChatGPT。
因此,从技术角度看,DeepSeek的成就不应因此受到质疑。由于OpenAI o1相关思维链推理过程从未公开,单纯依靠"蒸馏"ChatGPT根本难以实现这一成果。
而caoz认为,DeepSeek的训练中,可能部分利用了一些蒸馏的语料信息,或者做了少许的蒸馏验证,但这个对它整个模型的质量和价值影响应该很低。
此外,基于领先模型蒸馏验证优化自己的模型,是很多大模型团队的一个常规操作,但毕竟需要联网API,能获得的信息非常有限,不太可能是决定性的影响因素,相对于海量的互联网数据信息来说,通过api调用领先大模型能获得的语料杯水车薪,合理的猜测是更多用于对策略的验证分析,而不是直接用作大规模训练。
所有大模型都需要从互联网获得语料训练,而领先的大模型也在不断为互联网贡献语料,从这个角度来说,每个领先的大模型都摆脱不了被采集,被蒸馏的宿命,但其实也没必要把这个当作是决定成败的关键。
最终大家都是你中有我,我中有你,迭代前进。
2
DeepSeek的成本仅有550万美元?
550万美元成本,这个结论既正确也错误,因为没有说清楚是什么成本。
Tanishq Mathew Abraham客观估算了DeepSeek的成本:
首先,我们有必要理解这个数字是从何而来。这个数字最早出现在DeepSeek-V3的论文中,该论文比DeepSeek-R1的论文早发布了一个月;
DeepSeek-V3是DeepSeek-R1的基础模型,这意味着DeepSeek-R1实际上就是在DeepSeek-V3的基础上进行了额外的强化学习训练。
因此,从某种意义上说,这个成本数据本身就不够准确,因为它没有计入强化学习训练的额外成本。不过这部分额外成本可能也就几十万美元。

图:DeepSeek-V3论文中关于成本的论述
那么,DeepSeek-V3论文中声称的550万美元成本是否准确呢?
基于GPU成本、数据集大小和模型规模的多项分析都得出了类似的估算结果。值得注意的是,虽然DeepSeek V3/R1是一个拥有6710亿参数的模型,但它采用了专家混合系统(mixture-of-experts)架构,这意味着在任何函数调用或前向传播时只会使用约370亿参数,这个数值才是训练成本计算的基础。
需要注意的是,DeepSeek报告的是基于当前市场价格估算的成本。我们并不知道他们的2048个H800 GPU集群(注意:不是H100,这是一个常见的误解)实际花费了多少。通常情况下,整批购买GPU集群会比零散购买便宜,所以实际成本可能更低。
但关键在于,这只是最终训练运行的成本。在达到最终训练之前,还有许多小规模的实验和消融研究,这些都会产生相当可观的成本,而这部分成本并未在此报告中体现。
此外,还有其他诸多成本,比如研究人员的薪资。据SemiAnalysis报道,DeepSeek的研究人员薪资据传高达100万美元。这与OpenAI或Anthropic等AGI前沿实验室的高端薪资水平相当。
有人因为这些额外成本的存在,而否定了DeepSeek的低成本和其运营效率。这种说法极不公平。因为其它AI公司在人员上也会花费大量的薪资,这通常都没有被计算到模型的成本中去。”
Semianalysis(一家专注半导体和人工智能的独立研究与分析公司)也给出了DeepSeek的AI TCO (人工智能领域中的总成本)分析,这张表总结了DeepSeek AI在使用四种不同型号GPU(A100、H20、H800和H100)时的总成本情况,包括买设备、建服务器和运营的费用。按照四年周期来算,这60,000块GPU的总花费是25.73亿美元,其中主要是买服务器的费用(16.29亿美元)和运营的费用(9.44亿美元)。
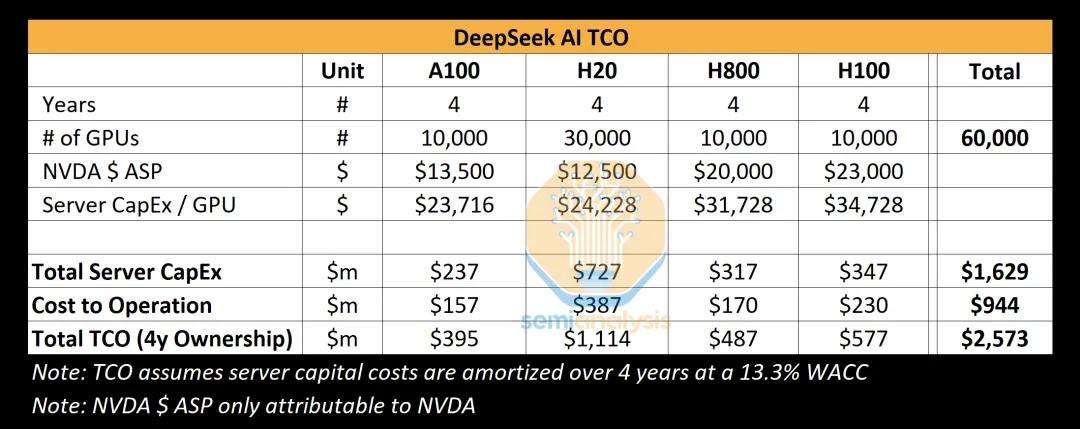
当然,外界没有人准确知道DeepSeek究竟拥有多少卡以及各个型号的占比究竟有多少,所有的一切都只是估算。
总结来说,如果把所有的设备、服务器、运营等成本全部算下来,成本肯定远超550万美元,但是,550万美元的净算力成本,已经十分高效。
3
巨额资本支出投资算力
只是巨大的浪费?
这是一个广为流传但相当片面的观点。确实,DeepSeek在训练效率上展现出了优势,也暴露出一些头部的AI公司在计算资源使用上可能存在效率问题。甚至英伟达短期的暴跌也可能也与这个误读广为流传有关。
但这并不意味着拥有更多计算资源是一件坏事。从Scaling Laws(扩展定律)的角度来看,更多的计算能力始终意味着更好的性能。自2017年Transformer架构问世以来,这一趋势一直延续,而DeepSeek的模型,也是基于Transformer架构的。
AI 发展的重点虽然在不断演变——从最初的模型规模,到数据集大小,再到现在的推理计算和合成数据,但"更多计算等于更好性能"的核心规律并未改变。
虽然Deep Seek找到了一个更高效的路径,规模定律依然有效,但是,更多的计算资源,仍然能获得更好的效果。
4
DeepSeek是否采用了PTX
绕过了对 NVIDIA CUDA的依赖?
DeepSeek的论文中提到了DeepSeek采用了PTX(Parallel Thread Execution)编程,通过这样的一个定制的PTX优化,使DeepSeek的系统和模型可以更好释放底层硬件的性能。
论文的原文如下:
“we employ customized PTX(Parallel Thread Execution)instructions and auto-tune the communication chunk size, which significantly reduces the use of the L2 cache and the interference to other SMs。”“我们采用定制的PTX(并行线程执行)指令并自动调整通信块大小,这大大减少了L2缓存的使用和对其他SM的干扰。”
这段内容,网络上流传着两个解读,一种声音认为,这是为了“绕开CUDA垄断”;另外一种声音是, 因为DeepSeek无法获得最高端的芯片,为了解决H800 GPU互联带宽受限的问题,不得不下沉到更低一层,来提升跨芯片通信能力。
上海交通大学副教授戴国浩认为,这两种说法都不太准确。首先,PTX(并行线程执行)指令实际上是位于CUDA驱动层内部的一个组件,它仍然依赖于CUDA生态系统。所以,用PTX绕过CUDA的垄断这种说法是错误的。
戴国浩教授用一张PPT清晰地解释了PTX和CUDA的关系:

PPT系上海交通大学副教授戴国浩制作
CUDA是一个相对更上层的接口,提供了面向用户的一系列编程接口。而PTX一般被隐藏在了CUDA的驱动中,所以几乎所有的深度学习或大模型算法工程师是不会接触到这一层。
那为什么这一层会很重要呢?原因是在于可以看到从这个身位上,PTX是直接和底层的硬件去发生交互的,能够实现对底层硬件更好的编程和调用。
用通俗的话来讲,DeepSeek这种优化方案并不是在芯片受限的现实条件下的不得已为之,而是主动做的优化,不管芯片用的是H800还是H100,这种方法都能够提高通信互联效率。
5
DeepSeek会被国外禁用吗?
DeepSeek爆火之后,英伟达、微软、英特尔、AMD、AWS五大云巨头都上架或集成了DeepSeek,国内来看,华为、腾讯、百度、阿里、火山引擎也都支持部署了DeepSeek。
但是,网络上有一些过度情绪化的言论,一方面是,国外云巨头上架了DeepSeek,“老外被打服了”。
其实,这些公司对于DeepSeek的部署,更多是因为商业的考量。作为云厂商,尽可能多地支持部署最受欢迎、及能力最强的模型,可以为客户提供更好的服务,同时,也能蹭一波与DeepSeek相关的流量,或许也会带来一部分的新用户转化。
在DeepSeek大热的时候集中部署是真,但是对DeepSeek情有独钟或者是“被打服”等说法却过分夸大了。
更有甚者,编造出了DeepSeek遭受攻击之后,中国科技圈组成复仇者联盟,共同驰援DeepSeek的说法。
另外一方面,还有声音说,因为地缘政治等现实原因,很快国外就会陆续禁止DeepSeek使用。
对此,caoz给出了比较清晰的解读:其实我们所说的DeepSeek,实际上包括了两个产品,一个是DeepSeek这个风靡世界的App,另一个是github上的开源代码库。前者可以认为是后者的Demo,一个完整的能力展示。而后者,也许会成长为一个蓬勃的开源生态。
被限制使用的,是DeepSeek的App,而巨头接入和提供的,是DeepSeek开源软件的部署。这完全是两件事。
DeepSeek以"中国大模型"的姿态闯入全球AI竞技场,且采用了最大气的开源协议——Apache License 2.0,甚至允许商用。目前对它的讨论已经远远超越了技术创新的范畴,但技术的进步从来不是非黑即白的对错之争。与其陷入过度吹捧或全盘否定,不如让时间和市场检验其真实价值。毕竟,在AI这场马拉松中,真正的竞争才刚刚开始。
参考资料:
《关于deepseek的一些普遍误读》 作者:caoz
https://mp.weixin.qq.com/s/Uc4mo5U9CxVuZ0AaaNNi5g
《DeepSeek最强专业拆解来了,清交复教授超硬核解读》 作者:ZeR0
https://mp.weixin.qq.com/s/LsMOIgQinPZBnsga0imcvA
Debunking DeepSeek Delusions作者:Stability AI 前研究主管 Tanishq Mathew Abraham
https://www.tanishq.ai/blog/posts/deepseek-delusions.html


