


2月5日开工第一天,业界传来大消息,百度智能云成功点亮自研昆仑芯三代万卡集群,这也是国内首个正式点亮的自研万卡集群。除了解决自身算力供应问题之外,有望进一步降低大模型成本。
此前,DeepSeek推出V3和R1模型,以可媲美OpenAI领先模型的效果和极大的成本降低,在春节期间引爆全球市场。
在陆续取得突破的背后,AI大模型竞争也进入新时期——不再局限于技术,而是成本、用户体验、生态体系的综合较量。“每天一杯奶茶钱就能养AI”不再是梦,AI加速走向普惠化。
01 DeepSeek之后,国产自研万卡集群亮相
实际上,在DeepSeek新模型推出后,最近几天,海内外芯片行业动作频出。海外如英伟达、AMD、英特尔,国内如华为昇腾、沐曦、天数智芯、摩尔线程、海光等,纷纷宣布支持DeepSeek模型部署、推理服务。
而在2月5日新春后开工首日,百度智能云也宣布,成功点亮昆仑芯三代万卡集群,万卡集群的建成,将进一步推动模型降本。
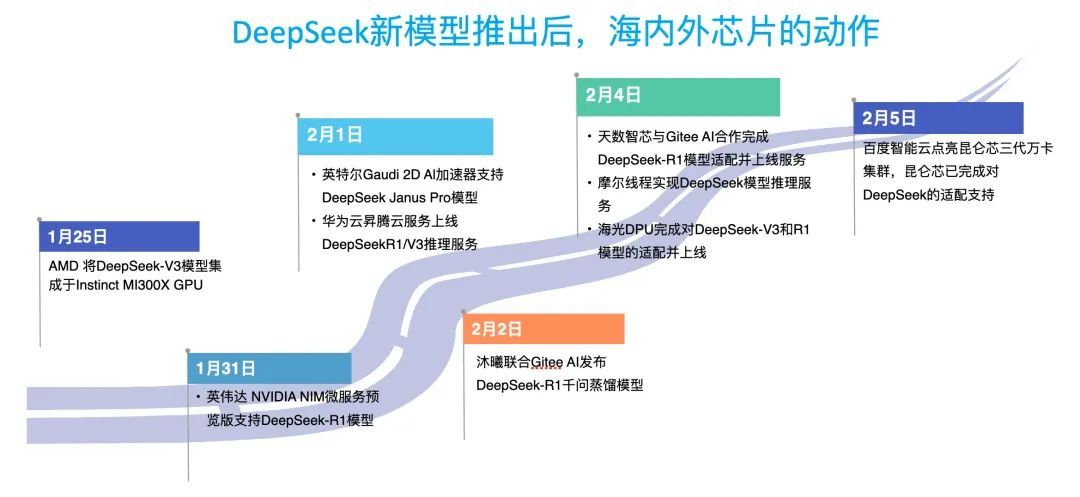
此前,海外的谷歌、亚马逊AWS和特斯拉都自研部分芯片,来降低成本,提升性价比。在中国,过去一年,算力紧张是大模型成本居高不下的重要因素之一。通过自研芯片和大规模集群的建设,不仅解决了自身算力供应问题,也有望进一步降低大模型成本。
昆仑芯是百度自研的AI芯片,初代于2018年推出。
最近两年,昆仑芯对外鲜有报道。但在点亮万卡集群之前,业界已经听到了一些风声。外界推测,昆仑三代芯片于2024年量产。也有行业内企业告诉数智前线,2024年下半年,他们曾评估购买基于昆仑三代芯片的服务器。
百度董事长李彦宏曾在一些场合强调,昆仑芯是百度AI技术栈的“基石”,自研能力保障了在生成式AI时代的技术主权。
在2024年的一些对外介绍中,百度称昆仑芯,与飞桨深度学习框架、文心大模型深度协同,形成“芯片-框架-模型-应用”的端到端优化,提升整体性能。
数智前线获悉,此前两代昆仑芯片,主要用于AI的部署和推理服务。昆仑芯三代则更进一步,是为大模型和训练优化的AI云端芯片。
这次点亮的万卡集群,可将千亿参数模型的训练周期大幅降低,同时能支持更大模型与复杂任务和多模态数据,支撑Sora类应用的开发。此外,万卡集群能支持多任务并发能力,通过动态资源切分,单集群可同时训练多个轻量化模型,通过通信优化与容错机制减少算力浪费,实现训练成本指数级下降。
值得关注的是,今年推理市场也将是重头戏。数智前线获悉,国内外芯片企业,都在铆足劲拼抢英伟达的市场份额。一位AI算力资深人士告诉数智前线,推理追求的是“能效比”,比拼每瓦的计算性能。
预计百度昆仑芯集群也将加入这一市场的争夺。而针对推理市场,业界的策略是围绕主流模型,做好适配服务。毫无疑问,除了自身的文心一言,昆仑芯也适配了DeepSeek等一众模型。
在百度官宣中也提及,随着国产大模型的兴起,万卡集群逐渐从“单任务算力消耗”到“集群效能最大化”过渡,“将训练、微调、推理任务混合部署”,从而提升集群综合利用率,降低单位算力成本。
接下来,海内外大厂面临如何突破英伟达的CUDA护城河。在过去10多年,英伟达利用CUDA生态,既把持训练市场,又围猎推理市场。CUDA的厉害之处,是面向生命科学、量化、自动驾驶等场景持续开发应用库。“你要完成一个药物分子、自动驾驶的应用,CUDA上可能已写了10万行代码,你可能再写几百行,就解决问题了。”上述人士说。
目前,不少国家如英国、法国、加拿大和中国企业在AI芯片生态上表现出倔强和韧性,开展基础生态建设。另外,全球一些国家的高校实验室和科研机构,在政府的支持下,也持续在做基础工作。
02 “每天一杯奶茶钱就能养AI”
在最新的芯片进展之外,DeepSeek掀起的大模型风暴也在继续,而各大云计算大厂已纷纷宣布支持DeepSeek模型调用或部署,并卷起价格战,争夺市场。
大厂的积极性,与DeepSeek模型在全球掀起的巨大流量相关。这个春节假期,“神秘的东方力量”、“AI界拼多多”、“每天一杯奶茶钱就能养的AI”……国产大模型DeepSeek,不管是在国内,还是国外,都赚足了关注度。
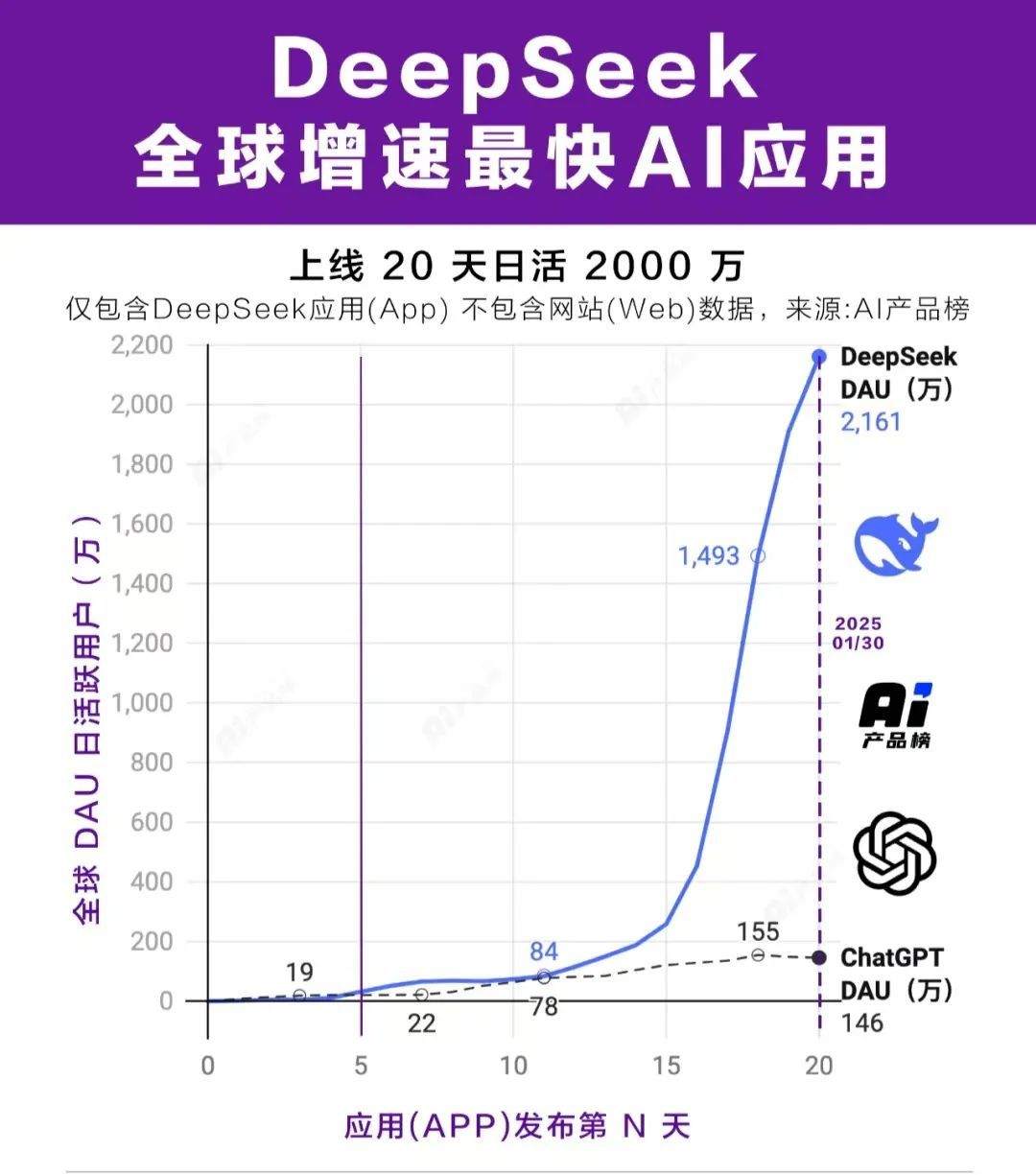
2月4日,AI产品榜公布,根据最新统计数据,上线20天,DeepSeek应用(不包含网站数据)日活已破2000万,上线5天时日活就已超过ChatGPT上线同期日活,成为全球增速最快的AI应用。
在微博,2月4日,“DeepSeek回答如何过好这一生”一度登上热搜第一位。 在小红书,DeepSeek相关笔记已迅速超49万,各类教程、测评帖密集涌现,甚至有人玩起了“AI算命”。

“免费使用+更好的效果”是吸引普通用户尝鲜的关键。
更为关键的是,Deepseek给了OpenAI价格体系一记重击。多项数据测算,如果以平均使用情况计算,DeepSeek-R1 的整体成本,约为OpenAI o1模型的1/30,让人们可以用极低的成本应用AI。
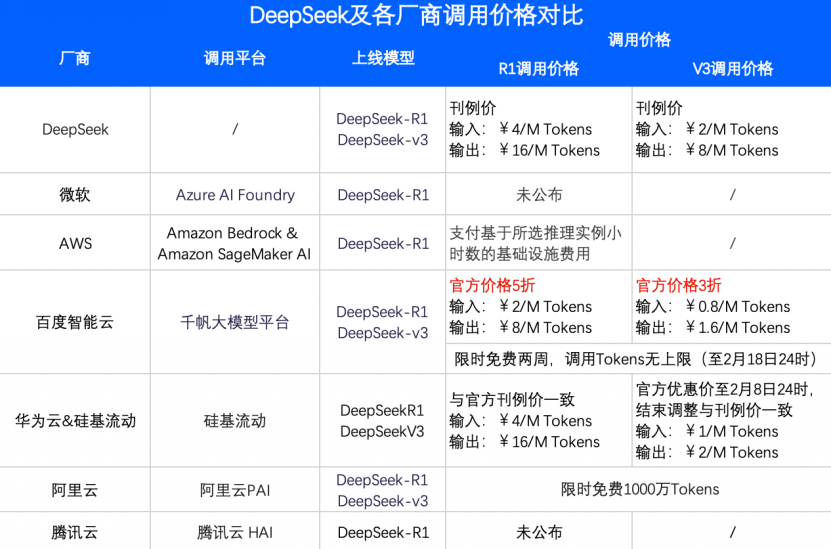
随着 DeepSeek 的爆火,科技大厂之间的大模型价格战愈发激烈。海外的微软 Azure、亚马逊AWS和英伟达NIM服务,接入DeepSeek模型,试图通过更具吸引力的性价比来抢夺市场份额。国内的运营商、阿里云、百度智能云、火山引擎等也不甘示弱,以各种形式接入DeepSeek模型后,展开了价格博弈。
一些云计算企业的价格与Deepseek官方刊例价一致,或在此基础上有一定优惠或免费额度。
其中,2月3日,百度智能云打出的价格最低,百度智能云R1调用价格,是Deepseek官方刊例价的5折,V3调用价格是官方刊例价的3折,并限时免费两周。
大模型调用价格的大幅下降,降低了高质量模型的使用门槛,企业决策阻力骤减,也快速引爆了开发者的热情。
在全球各个技术论坛上,“DeepSeek”是最燃的话题。在开发者社区CSDN上,全站综合热榜前十名中,有四条都与DeepSeek有关,相关应用迅速涌现。有网友用DeepSeek将老照片修复成彩色的,期间没写一行代码。

在金融行业,江苏银行将DeepSeek引入到自身服务平台“智慧小苏”中,并将DeepSeek-VL2多模态模型、轻量DeepSeek-R1推理模型,分别运用到了智能合同质检和自动化估值对账场景中。
某跨国药企基于DeepSeek-R1模型构建药物副作用预测系统,结合患者历史数据与实时监测,降低临床试验风险。
上海交通大学已开始用DeepSeek-V3生成合成数据,开发垂类大模型。
事实上,OpenAI为了应对DeepSeek的竞争,已迅速推出新模型o3-mini,其定价也被打下来了。
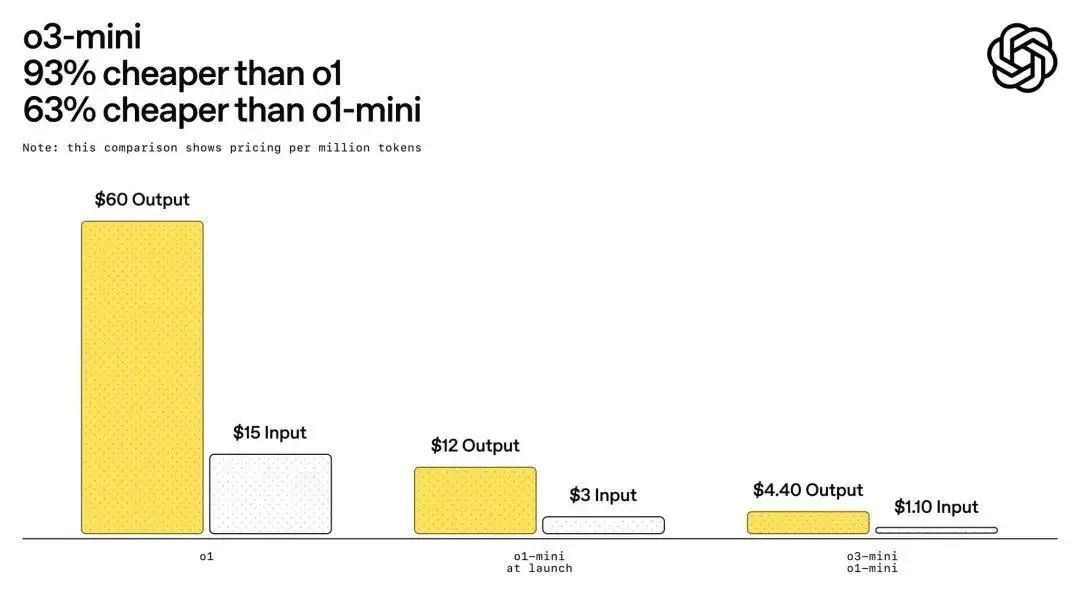
尽管这一价格仍高于DeepSeek的定价,但这是一个显著的降价趋势。
实际上,DeepSeek这轮大火,也标志着AI大模型竞争不再局限于技术,而是成本、用户体验、生态体系的综合较量。
“每天一杯奶茶钱就能养AI”不再是梦。业界这一轮动作,以极具竞争力的价格优势,不仅改变了普通用户对 AI 的使用习惯,更在行业内掀起了一股变革的浪潮,推动着 AI行业朝着更普惠的方向发展。
03 大模型普及进程将加速
一旦各方科技大厂和平台力量加入,由DeepSeek引发的大模型普惠的进程将加速。
2月3日,我们体验了公有云的DeepSeek API调用,用Deepseek R1,特别体验了两个玩法:
玩法一:秦始皇AI军师体验卡
玩法二:老照片时光染色机
可以看到,即便之前没有任何技术背景,登录百度智能云网站,只需要点击在线体验,进行实名认证,在“模型广场”就可以轻松调用DeepSeek-R1和DeepSeek-V3模型。
用户还可在千帆提供的67个模型中,一次性选择六个模型,让他们同时干一件事,直观对比模型的效果,最终用脚投票。
这也是平台的优势所在,集成各种模态的开闭源模型,就好比AI界的“滴滴打车”,既能比价比质,让用户自由选择最高效价比模型服务,也能智能“拼车”、多模态协同,互补模型能力,增强应用深度。
在各种配套服务上,头部云平台们,在一站式开发工具链、全生命周期安全机制、行业解决方案等各项能力的搭建和完善上,也有着极快的反应速度。
在工具链上,尽管大模型爆发已两年,但门槛依然较高,需辅以各种好用的工具。比如我们发现,在Github社区上,按Star数排序,其中最受欢迎的DeepSeek项目,一个是帮助开发者使用DeepSeek的工具集——DeepSeek-Tools,另一是帮助开发者自动选择和优化DeepSeek模型超参数的DeepSeek-AutoML。
各云大厂也都在工具链上进行了诸多布局,如百度智能云的千帆大模型平台,虽然没有直接上架DeepSeek工具包,但已集中各种类似工具,如数据加工、工作流编排、模型精调、模型评估、模型量化......
当企业用户使用DeepSeek模型开发应用,却担心训练数据泄露、生成内容不符合规范以及模型在推理过程中被恶意攻击等问题时,各云平台也都在安全机制上进行了保障。
根据新闻介绍,百度智能云在将DeepSeek接入千帆推理链路时,支持了百度独家内容安全算子,保障内容生成的安全;通过数据保险箱产品,保证模型仅可用于推理预测程序,训练数据仅可用于模型微调程序;千帆平台集成的BLS日志分析和BCM告警功能,也能保障金融或医疗等对安全要求较高的用户,构建的智能化应用更安全可靠。
而云平台们积累的更广泛的行业覆盖和行业解决方案,也能帮助开发者实现在对应行业和场景的快速复制与场景适配,让DeepSeek快速进入这些垂直领域。
除了这些,面向企业逐渐从模型训练、微调转向推理的大背景,推理的支撑和优化成为关键。百度智能云对DeepSeek进行了专项优化,如通过针对DeepSeek模型MLA结构的计算进行了极致的性能优化;并通过计算、通信、访存不同资源类型算子的有效重叠及高效的Prefill/Decode分离式推理架构等,在核心延迟指标TTFT/TPOT满足SLA的条件下,实现吞吐量“坐火箭”,推理成本“坐滑梯”。
千帆支持多种主流推理框架的,让开发者可以根据实际场景选择最适合的推理引擎。如,vLLM以高吞吐量和内存效率著称,适合大规模模型部署;而SGLang特别是在延迟和吞吐量上优于其他主流框架。同时,允许用户自定义导入和部署模型,为DeepSeek开发提供了灵活性。
通过大厂和平台企业的加入,AI普惠化将成为今年的发展主线之一。当大模型从“土豪玩具”变成“普通人的口粮”,创新门槛的降低将激发更大的创造力,最终让人类突破能力和资源的边界——小店主用AI设计爆款包装、中学生靠开源模型开发校园助手、乡村医生借多模态工具辅助诊断…这场全民参与的智能革命,让每个普通人都能站在AI的肩膀上,触摸曾经遥不可及的未来。


