

在今年春节期间,最近国产的推理大模型DeepSeek R1很火,我们经过实测,推理效果非常棒,可以说是阶段性的技术突破。
不过,每次中国优秀的明星产品或企业崛起之时,总会遭到一些境外不法势力的暗中阻击。上一次是《黑神话:悟空》全球上线后,遭遇了海外60个僵尸网络大规模攻击,而这次DeepSeek上线以来,也遭遇了包括僵尸网络在内的多轮攻击,攻击方式一直在进化和复杂化。
既然网络有被攻击的风险,很多人就希望本地化部署DeepSeek,那么,本地化部署DeepSeek简单吗?部署完成后就可以避免安全问题发生了吗?
本地化部署DeepSeek
随着人工智能技术的快速发展,大模型在自然语言处理、图像识别等领域取得了显著进展。传统的大模型需要将大量数据上传到云端进行训练和inference,而本地化部署通过在设备端运行预训练模型,能够避免对敏感数据的远程传输,从而提升数据隐私保护能力。
但是,很多人对于本地化部署大模型还比较陌生,其实操作起来并不复杂。
就拿DeepSeek为例,首先,一键下载安装Ollama这款软件。官网地址https://ollama.com/国内可直接访问,支持Windows、MacOS和Linux;

其次,运行命令ollama run deepseek-r1:8b 即可完成部署8B的R1模型部署(自动下载,国内可正常下载);
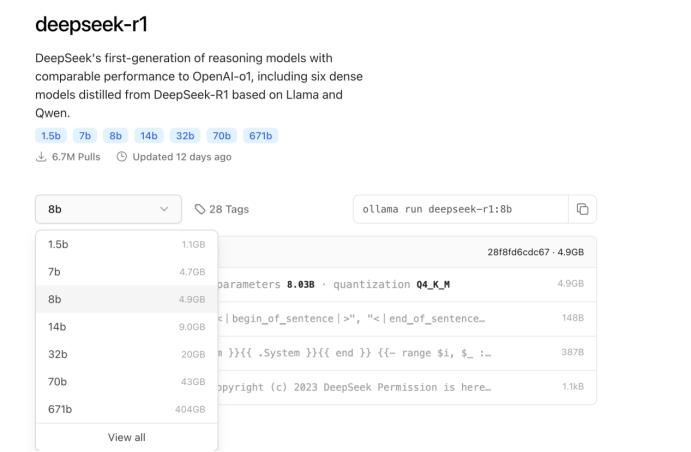
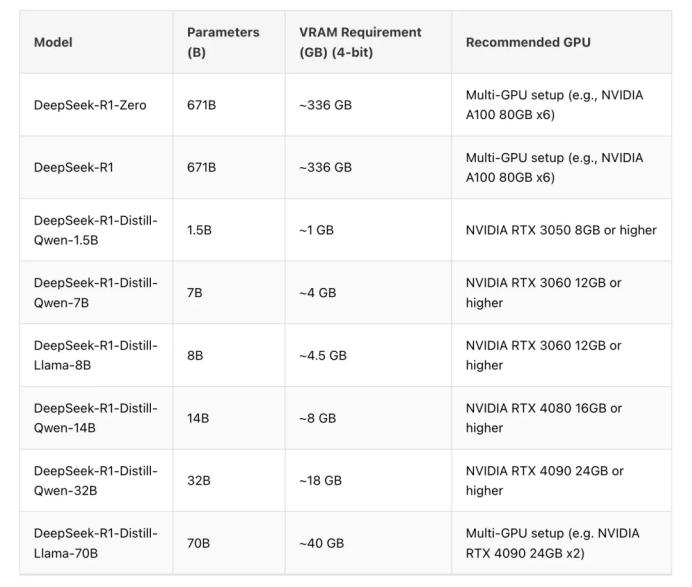
除了8b模型外,下面的这张截图就可以确定,对号入座即可。注意:只需看你的显卡显存大小,显存大小如果够用了就可以运行,显卡的性能不太重要,即使是老显卡1080、2080等都有很好的效果。
明确了用户可以使用多大参数的模型,接下来就来部署。访问Ollama官网,搜索deepseek,找到R1模型。可以选择更大参数量的R1模型,我们上面的命令是运行的8B大小的模型。模型参数越大,效果越好。
此后,Windows可以使用CMD、Powershell运行ollama命令。MacOS可以使用iTerm、Terminal。
在部署完成后,用户就可以在本地与DeepSeek交流。

另外,如果用户需要面向一些隐私场景,数据不方便上传到外网。通过向量数据库+RAG,构建个人知识库。支持本地和远程向量数据库、agent工具等。
以paper为例,上传个人知识库后,会自动embedding并存入向量数据库,即可开启聊天,查资料等。
值得注意的是,大模型本地化部署通常包括以下几个关键环节:
1. 模型压缩与量化:为适应边缘设备的计算资源限制,通常采用模型压缩和量化技术。模型压缩通过移除冗余参数或优化算法减小模型尺寸;量化则通过将模型权重表示为有限精度浮点数,降低存储和计算需求。
例如,常见的压缩算法包括剪枝(去除不重要的神经元连接)和知识蒸馏(将大型模型的知识迁移到小型模型中),而量化方法如 INT8 量化可将模型权重从 32 位浮点数量化为 8 位整数,显著减少模型存储空间和计算量。
2. 模型固件加密:在本地化部署中,模型核心逻辑需嵌入硬件固件,以防止恶意篡改或逆向工程。这涉及对硬件设计进行封闭式处理,并严格进行安全审计。
例如,采用专用指令执行环境或安全处理器,确保程序正常执行,防止恶意代码注入。
3. 数据预处理与特征提取:本地化部署需在设备端完成数据预处理和特征提取,这一过程可能暴露部分数据信息。因此,如何在保证数据隐私的前提下完成特征提取,是一个重要挑战。
例如,可采用差分隐私技术,在数据中添加噪声,保护用户隐私,同时尽量不影响模型性能。
虽然,本地化部署降低了计算开销,还提高了服务响应速度,但与此同时,也引发了一系列新的安全问题。如何在本地化部署中确保模型的安全性和用户数据的隐私保护,成为当前AI研究中的重要课题。
大模型本地化部署也有安全问题?
如今,随着大模型项目需求不断增长,各类开源框架层出不穷。这些框架极大提升了开发效率,降低了构建AI应用的门槛,同时也打开了新的攻击面。在AI场景下,为了使大模型能处理各项业务需求,通常会赋予其包括代码执行在内的多项能力,这在带来便捷的同时,也提供了更多攻击系统的可能性。

首先是数据泄漏风险,在本地化部署中,用户数据直接暴露在设备端,若设备未充分保护,攻击者可通过物理或网络方式获取用户数据。例如,攻击者可能利用设备的漏洞或弱密码,通过网络入侵设备,窃取存储在本地的数据。
其次是模型权重盗窃,模型的核心权重是其性能的关键,本地化部署使权重存储在边缘设备中,如何防止权重被盗窃或篡改成为重要问题。一旦权重泄露,攻击者可轻松复制模型并进行恶意使用。例如,攻击者可能通过逆向工程或侧信道攻击,获取模型权重。
再次是逆向工程风险,大模型的开放性使其结构和参数难以完全理解,攻击者可能通过对模型输出的观察,反推出模型内部逻辑,找到潜在漏洞或弱点。例如,攻击者可通过分析模型的输出结果,推测其内部结构和参数设置,从而找到攻击切入点。
最后是授权绑定问题,本地化部署需确保仅授权用户或设备访问和使用特定模型,这涉及如何有效绑定模型权限与身份认证。例如,攻击者可能通过伪造身份认证信息,非法访问和使用模型。
面对以上的问题我们就没有办法解决了吗?可以从以下几个方面提出解决方案:

一、 加密技术的应用:在数据预处理阶段,对用户输入数据进行加密,确保数据泄露时无法被有效解密。同时,在模型权重传输中使用加密技术,如基于密钥的一致性加法(PAKE),保护模型权重不被窃取。
例如,采用对称加密算法(如 AES)对数据进行加密,确保数据在传输和存储过程中的安全性。
二、 安全硬件设计:将安全功能集成到硬件层面,例如通过专用指令执行环境或安全处理器保护模型运行过程。这些硬件可确保程序正常执行,防止恶意代码注入。
例如,采用 Intel SGX(Software Guard Extensions)等安全硬件技术,为模型运行提供安全的执行环境。
三、 分离数据与模型:通过对数据进行抽象和符号化处理,使用户无法直接接触原始数据,即使模型权重泄露,也无法获取实际数据信息。
例如,采用联邦学习中的数据分离策略,将数据和模型分离,确保数据隐私。
四、 分层权限管理:采用基于角色的访问控制(RBAC)或基于属性的隐私保护技术,确保不同用户或设备仅能访问其授权范围内的模型和数据。
例如,为不同用户分配不同权限,通过身份认证和授权机制,限制用户对模型和数据的访问。
关于本地化部署大模型的安全问题,一直以来,学术界和工业界都在积极探索,一些代表性的技术包括量子随机数生成器用于加密、联邦学习中的模型联邦与差分等方法,以及基于零知识证明的新型认证方案。
写在最后
一直以来,本地化部署作为人工智能发展的重要方向,虽然面临诸多安全挑战,但通过技术创新和协同研究,这些问题是可以得到有效解决的。未来的研究可能会更加关注如何在模型复杂性和安全性之间找到平衡点,以及如何将先进的加密技术与AI算法更好地结合起来。
总之,包括DeepSeek在内的本地化部署为大模型带来了更多的可能性,同时也需要我们投入更多的努力来确保其安全性和隐私保护能力。通过多维度的技术创新和严格的安全设计,我们有望在未来让本地化部署不仅安全可靠,而且能够充分发挥其优势。


