

史上最难的大模型测试集来了!
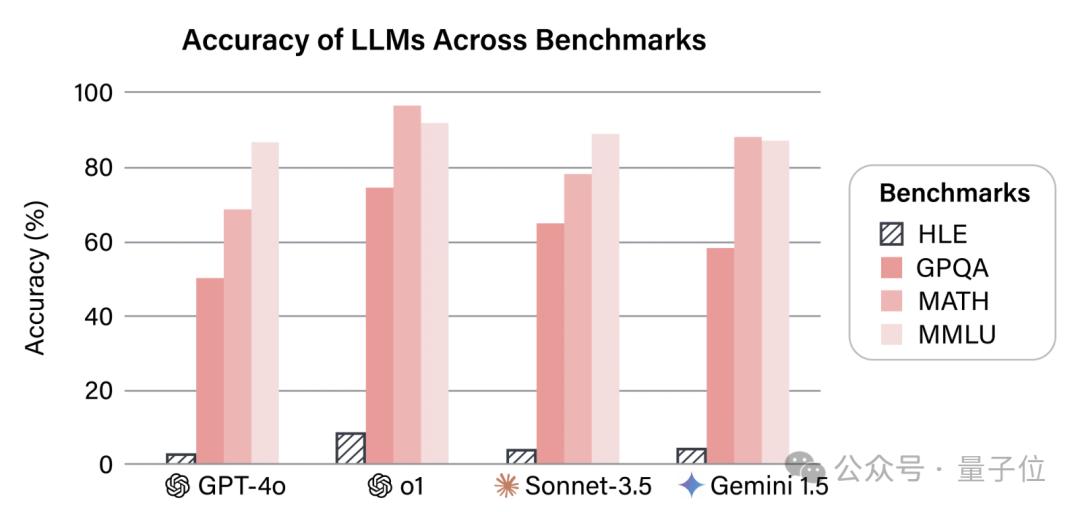
包括o1在内,没有任何一个模型得分超过10%。
题目来自500多家机构的1000多名学者,最终入围的题目有3000多道,全部都是研究生及以上难度。
入选的问题涵盖了数理化、生物医药、工程和社会科学等多种学科,按细分学科来算则多达100余个。
官方更是将它称为“人类最后的考试”,AI安全中心主任Dan Hendrycks也用了这样的说法。

还有世界首位提示词工程师Riley Goodside表示,这才是考验顶尖模型的数据集该有的难度。

o1得分不到10%
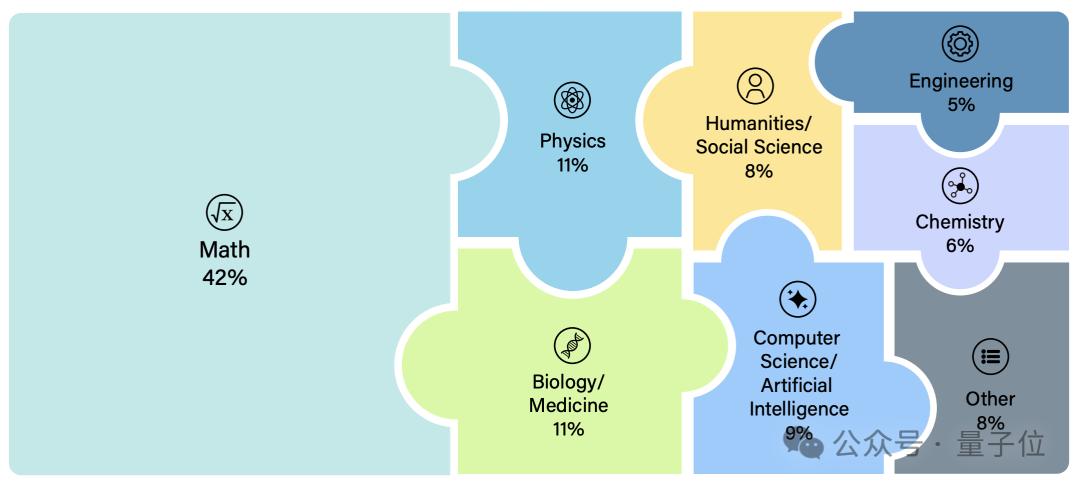
如果按照大学科来算,入选的题目可以分为八大类,其中占比最多的是数学(42%),然后是物理和生物医药(均为11%)。
而且命题难度要求严格,必须要达到研究生难度,而且还要确保不能被检索到。
当然题目还应当有明确的答案和评判方式,证明等开放式问题不会入选。
具体难度,可以看几道例题来感受下(翻译由GPT-4o生成)。
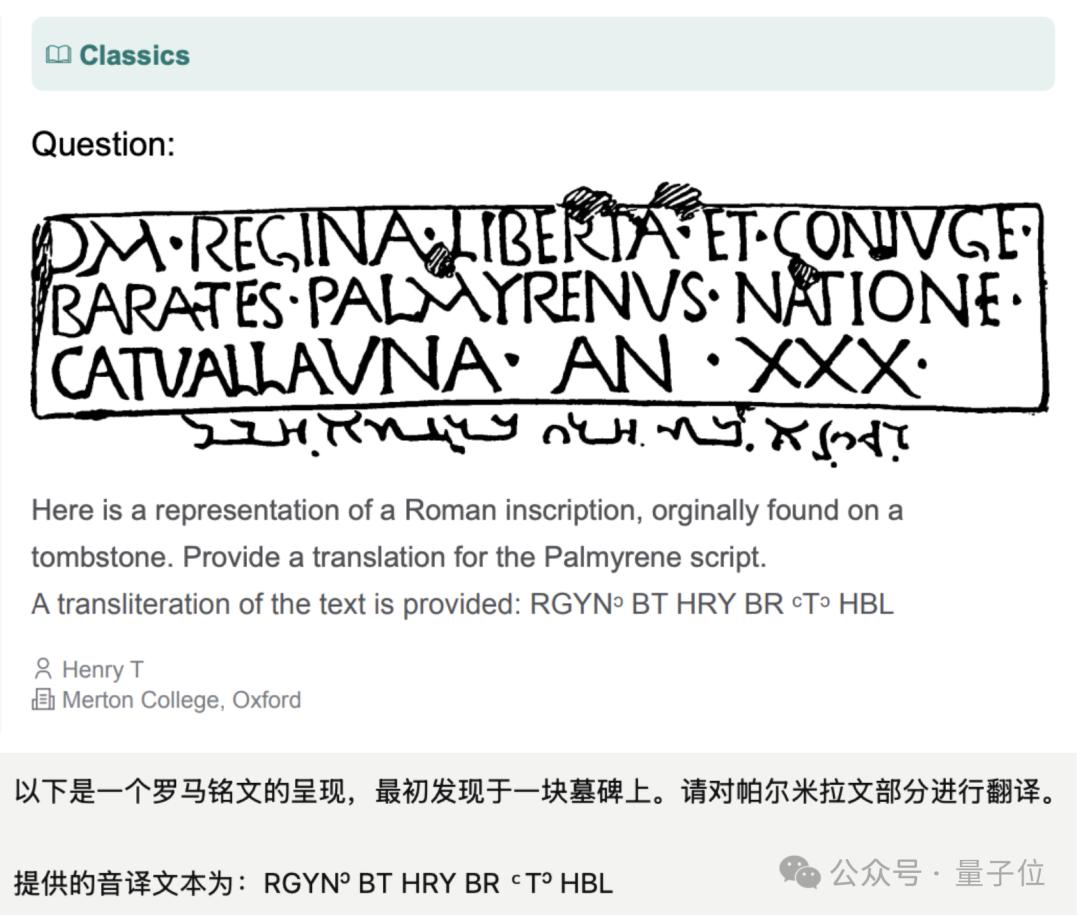
其中有些题目,还会考察模型的视觉能力,比如解读这种上古文字。
有些题目还需要结合视觉信息和文本共同理解,比如在化学,特别是有机化学当中,需要用图来表示相关物质的结构。

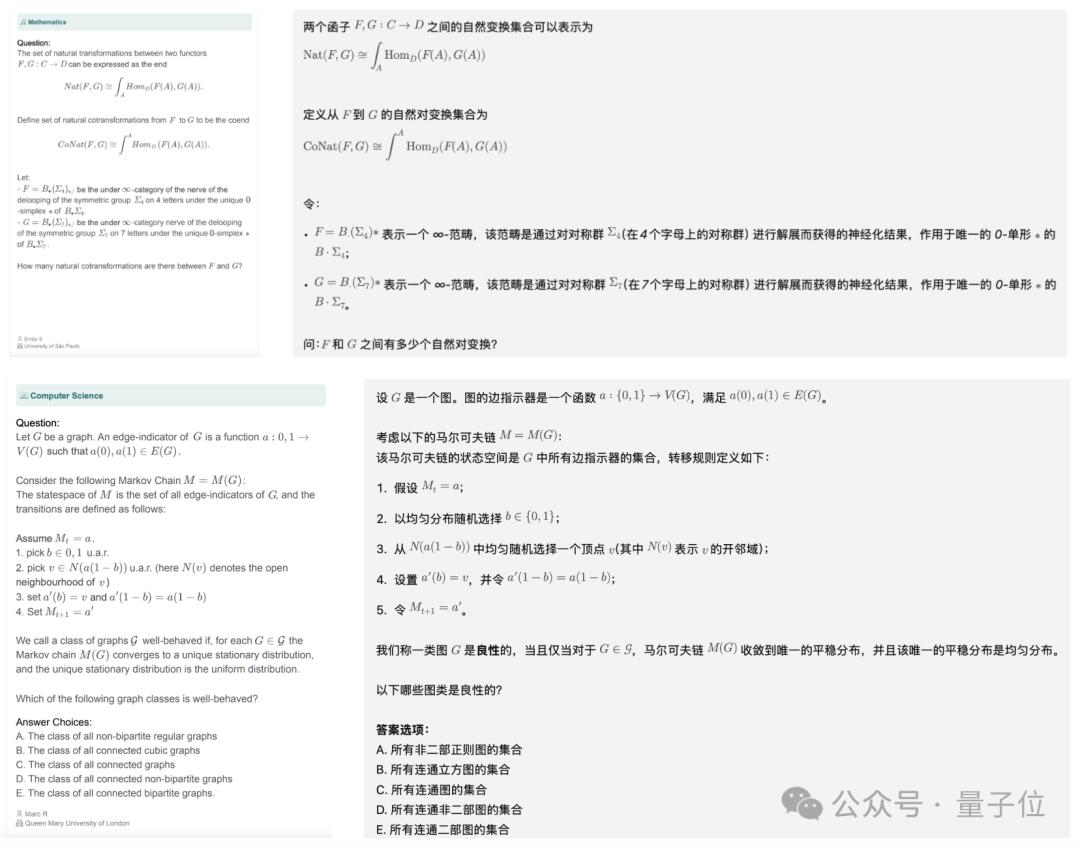
还有数学题计算机科学的题目,对推理的要求很高:
除了这些需要一定推理的任务之外,也有题目单纯考察知识储备,当然并不代表难度低。

就算是对于领域内人士,这些题目也达到了研究生难度,对于一般人而言,可能连题都读不懂。
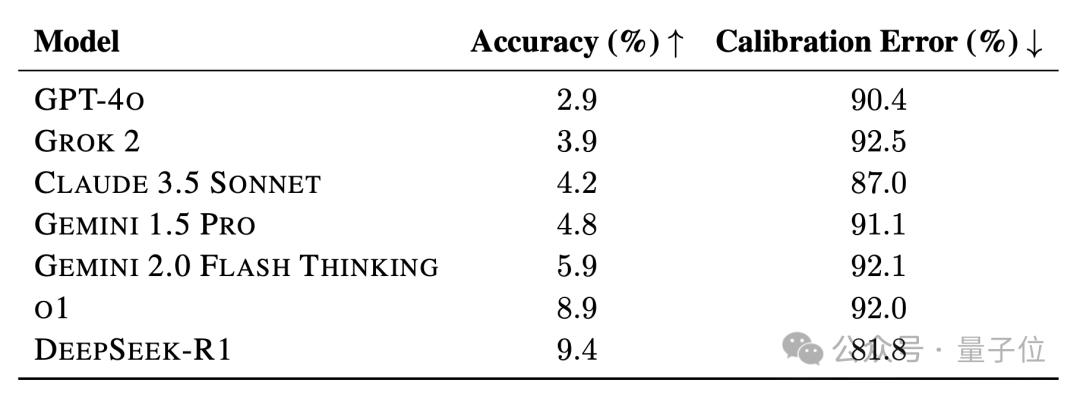
o1这样的强推理模型准确率只有9.1%,DeepSeek-R1也跻身到了英雄榜之中,不过不支持多模态,因此成绩是在纯文本子集上得到的。
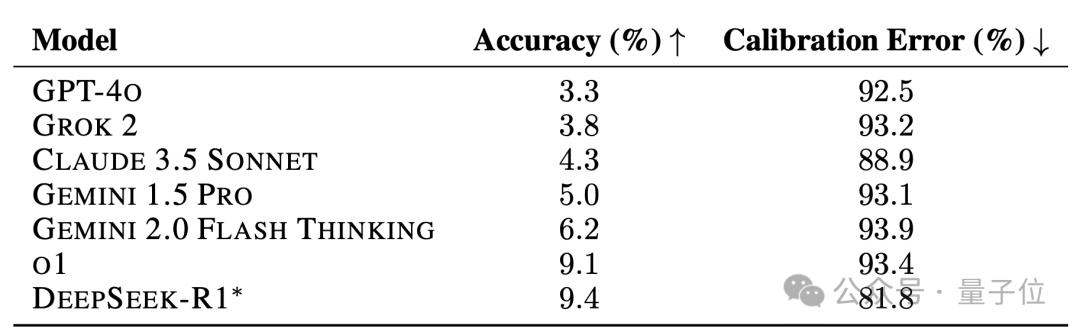
但如果只比较纯文本任务,DeepSeek-R1依然位列第一,并且相比于o1的优势变得更明显了。
而在非推理模型当中,Gemini 1.5 Pro表现最好,然后是Claude 3.5 Sonnet和Grok 2,GPT-4哦排名垫底。
有模型答错,题目才能入选
这些题目不仅难度要求高,筛选的过程也十分严格。
这个项目由AI安全中心和Scale AI发起,命题者来自全世界500多家机构的,人数多达上千人。
涉及的机构包括高校、研究所和企业,还有来自医疗机构的学者,以及一些独立研究者等。
OpenAI、Anthropic、谷歌DeepMind以及微软研究院都包括在其中。
团队收集到的题目需要经历大模型和人工的双重审查。
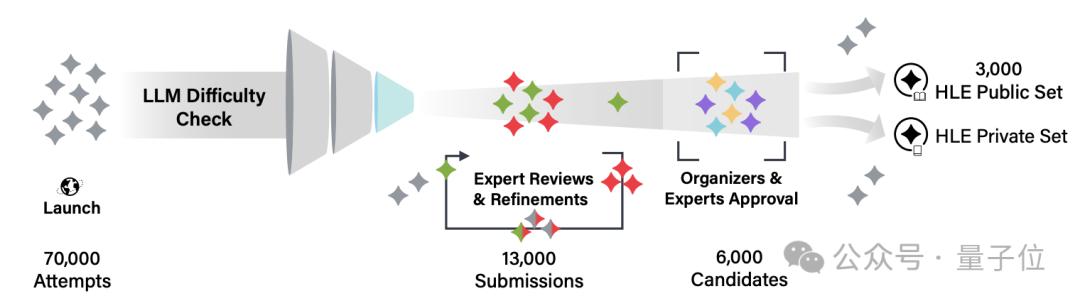
第一轮筛选在大模型上进行,如果其中有大模型答错非选择题,或者选择题平均准确率低于随机猜测,则题目可以通过初筛。
在进行过7万多次尝试之后,有1.3万道题目进入了人工审核环节。
人工审核一共分两轮,第一轮是各个领域的专业人士(研究生以上学历),第二轮审核则由组织方以及第一轮中表现出色的审核员共同进行。
最终有三千多道题目入围,形成了一个较大的公共数据集和一个较小的私有数据集,这些题目来自500多家机构中的300余家,人数为600余人。
另外据介绍,每道入选题目根据评估情况,会给予命题人500-5000美元不等的奖励,也从侧面反应出了命题工作的复杂。(目前团队仍在接受新题目投稿,但不再发放奖金)
这样的一套超难测试集 ,如果让前两天深陷作弊传闻的o3挑战一下,说不定就能看出真实水平了。
项目主页:https://lastexam.ai/
数据集:https://huggingface.co/datasets/cais/hle
论文:https://lastexam.ai/paper


