

合成孔径雷达(Synthetic Aperture Radar, SAR)作为一种基于电磁波的主动探测技术,具有全天时、全天候的对地观测能力,已发展成为一种不可或缺的对地观测工具,在军民很多领域均有着重要的应用。
目标识 别(Automatic target recognition,ATR)是 SAR 图像智 能解译的核心问题,旨在对 SAR 图像中典型目标(通常为车辆、舰船和飞机等目标)进行自动定位和分类,复杂、开放、对抗环境下的 SAR 目标识别要做到高精准、高敏捷、强稳健、省资源,仍然面临很多挑战。当前,SAR 目标识别主要面临两个层面挑战。
技术层面,SAR 目标识别方法多为有监督、静态、单任务、单模型、单平台,对特定类别的检测和分类,都需要各自的算法模型,每个任务都必须从头开始独立学习,这导致计算冗余、算法设计周期长、泛化能力严重不足、高标注依赖等问题。
生态层面,由于 SAR 图像数据敏感性、标注代价昂贵等因素,缺乏良好的、开源的代码、评估基准和数据生态,导致很多 SAR 目标识别算法不开源、算法评估基准不统一、目前尚无公开的百万 / 千万级大规模高质量 SAR 目标识别基准数据集等问题。
在人工智能基础模型技术飞速发展的今天,SAR 图像解译领域技术创新与发展生态亟待突破。

图 1. 各种专门的 SAR ATR 数据集和任务。SAR ATR 包括各种成像条件(即操作条件),如目标、场景和传感器。然而,由于成本较高,通常是在特定任务和设置中收集数据集。例如,MSTAR 是 X 波段和草地场景中的 10 型车辆目标分类数据集,SAR-Aircraft 是从三个机场和 C 波段卫星收集的 7 型飞机检测数据集。不同的目标特征、场景信息和传感器参数使现有算法的泛化困难。因此,团队旨在建立 SAR ATR 基础模型,一种用于各种任务的通用方法。
为了解决上述技术挑战,国防科技大学电子科学学院刘永祥&刘丽教授团队提出首个公开发表的SAR图像目标识别基础模型SARATR-X 1.0。
技术层面: ①率先开展基于自监督学习的 SAR 目标特征表示学习;②创新性地提出了适用于 SAR 图像的联合嵌入 - 预测自监督学习新框架(Joint Embedding Predictive Architecture for SAR ATR, SAR-JEPA),让深度神经网络仅仅预测 SAR 图像稀疏且重要梯度特征表示,有效地抑制了 SAR 图像相干斑噪声,避免预测 SAR 图像含相干斑噪声的原始像素强度信息;③研制了首个 SAR 图像目标识别基础模型 SARATR-X(0.66 亿参数,基于 Transformer),突破了复杂场景中 SAR 目标特征学习对大规模高质量标注数据高度依赖的瓶颈,大幅提升了预训练基础模型的认知能力。
生态层面: 团队致力于为 SAR 图像目标识别创建一个良好开源生态,以促进 SAR 目标识别技术快速创新发展。①规范和整合已有公开数据集,形成较大规模 SAR 图像陆海目标识别数据集 SARDet-180K;②为了取代 MSTAR(10 种车辆型号),耗时两年构建 SAR 车辆目标识别数据集 NUDT4MSTAR(40 种车辆型号、更具挑战的实际场景、数据公开、规模超过同类型数据集十倍),进行了详细性能评测;③开源相关的目标识别算法代码和评估基准。
研究成果以 “SARATR-X:面向 SAR 目标识别的基础模型(SARATR-X: Towards Building A Foundation Model for SAR Target Recognition)” 和 “预测梯度更好:探索联合嵌入-预测框架的 SAR ATR 自监督学习(Predicting gradient is better: Exploring self-supervised learning for SAR ATR with a joint-embedding predictive architecture)”,被国际顶级学术期刊《IEEE Transactions on Image Processing》录用和《ISPRS Journal of Photogrammetry and Remote Sensing》发表。
团队的代表性工作一经发表、录用后,已经引起国内外同行关注,获得积极评价。引文单位包括美国空军研究实验室、法国古斯塔夫・埃菲尔大学、新加坡南洋理工大学、北京大学、武汉大学、北京航空航天大学等。
例如,ISPRS Journal 主编、LASTIG 实验室主任 Clement Mallet 在其论文《AnySat: An Earth Observation Model for Any Resolutions, Scales, and Modalities》中认为 “SAR-JEPA [41] 首次将联合嵌入预测框架概念应用于对地观测,专门用于 SAR 数据。(引文原文:SAR-JEPA [41] introduces the first implementation of JEPA concepts for EO, focusing exclusively on SAR data. In this paper, we combine JEPA with a versatile spatial encoder architecture, allowing a single model to handle diverse data scales, resolutions, and modalities.)”
此外,该团队正在加紧研制 SARATR-X 2.0,预计参数规模 3 亿,SAR 目标切片样本规模 200 万,其中收集的数据将形成开源数据集以服务生态建设,近期将发布 SAR 车辆目标识别数据集 NUDT4MSTAR。
技术方案
团队旨在构建一个通用 SAR 图像目标识别基础模型以满足实践中多样的识别任务需求。作为首个公开发布的 SAR 图像目标识别基础模型 SARATR-X 1.0,该模型从大规模无标注 SAR 目标图像中学习到了较为通用的特征表示,突破了传统有监督算法适应性局限,为各种下游任务的高效适应提供基础。在系列工作中,团队研究了 SAR 图像目标识别基础模型的预训练集、模型架构、自监督学习和评估基准。
预训练集 ,所使用的预训练集包括不同的目标类别和成像条件,以适应各种下游任务,将大部分开源数据集作为预训练的一部分,共纳入了 14 个具有不同目标类别和成像条件的分类和检测数据集,作为新的预训练数据集,以探索基础模型的潜力。
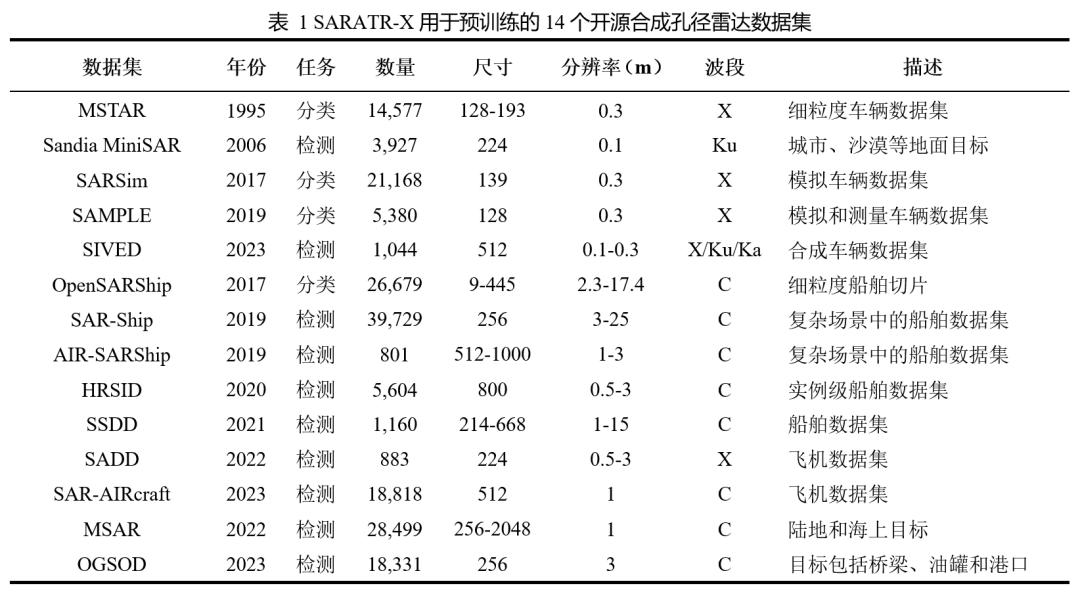
表 1. SARATR-X 用于预训练的 14 个开源合成孔径雷达数据集。
模型架构 ,采用 HiViT 架构,旨在实现更好的遥感图像空间表示,特别是对于大图像中的小目标。HiViT 具有 Swin Transformer 高分辨率输入的优势,且可在自监督学习的掩码图像建模中丢弃补丁提高训练效率。
自监督学习 ,SAR 相干成像中的散斑噪声会对图像质量产生负面影响。此外,SAR 幅度图像的视觉特征不像光学 RGB 图像那样明显。因此,SAR SSL 的主要任务是提高特征学习和目标信号的质量。在前期工作 SAR-JEPA 中,重点研究了如何针对 SAR 图像特性设计自监督学习方法。
SAR-JEPA 受 JEPA、MaskFeat、FG-MAE 等工作启发,这些工作利用特征空间进行自监督学习任务,而非在原始像素空间进行,这压缩了图像空间中信息冗余,且可以学习到不同特征,如目标性质、深层语义特征。SAR-JEPA 针对 SAR 图像噪声问题,重点在一个降噪特征空间进行自监督学习,通过结合传统特征算子去除散斑噪声干扰,提取目标边缘梯度信息用于自监督,从而实现在 SAR 图像这种噪声数据中的大规模无标注自监督学习。其结果表明自监督学习模型性能可在不同 SAR 目标分类数据集上随着数据量而不断增长。这推动了我们基于大规模数据集构建一个通用 SAR 图像目标识别基础模型,从而实现在不同目标、场景、传感器和识别任务中高效复用。
因此,SARATR-X 基于 SAR-JEPA 进行训练,首先在 ImageNet 数据进行预训练,以获得更好的初始化模型多样性,第二步是利用 SAR-JEPA 中高质量的目标信号对 SAR 图像进行预训练。
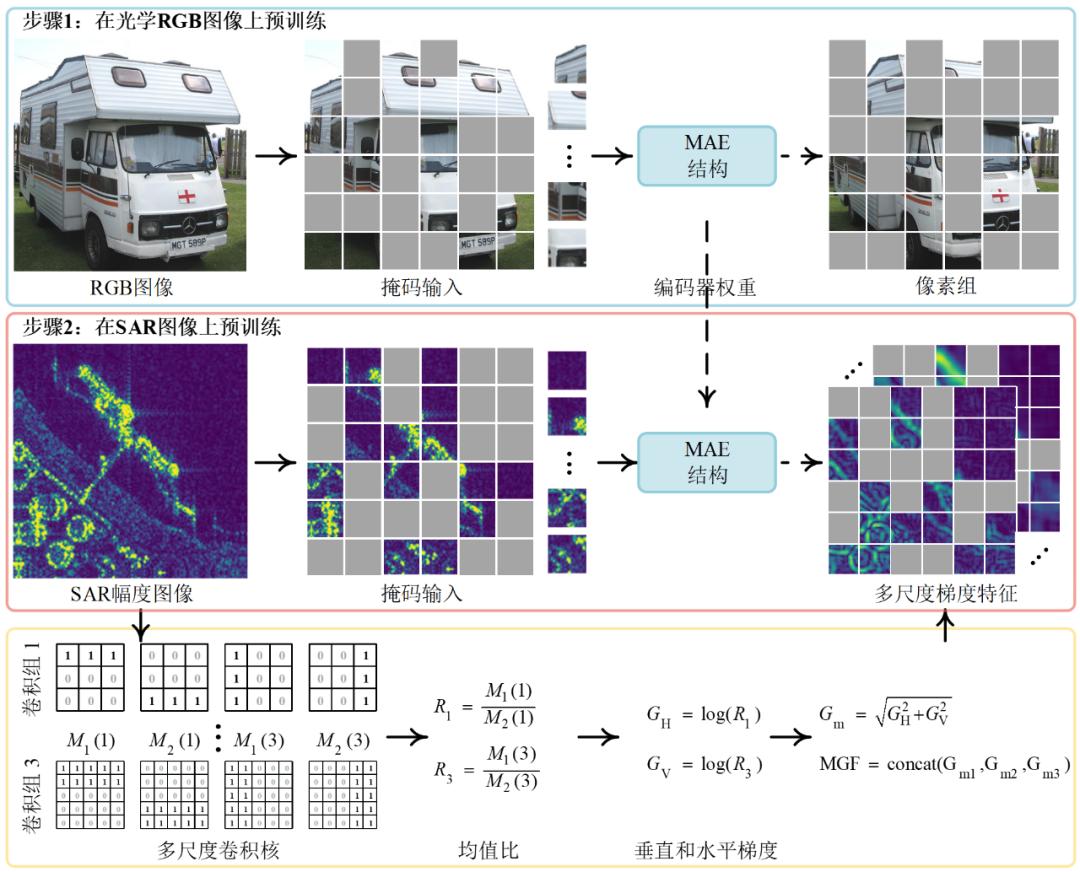
图 2. 两步预训练过程。第一步是对 ImageNet 数据进行预训练,以获得更好的初始化模型多样性。第二步是利用高质量的目标信号对 SAR 图像进行预训练,比如抑制散斑噪声和提取目标边缘的多尺度梯度特征。
评估任务,针对全面评估基础模型的性能需求,团队利用 3 个开源目标数据集,首先构建了一个包含 25 个类别的细粒度分类数据集 SAR-VSA,以评估所提改进措施的有效性。然后,在公开分类和检测数据集上,对所提 SARATR-X 1.0 和现有方法进行了全面比较。
模型性能
受限于公开的 SAR 目标识别数据集规模,研制的 SAR 图像目标识别基础模型 SARATR-X 1.0 规模只有 0.66 亿参数,但从大规模无标注 SAR 目标图像中学习到了较为通用的特征表示。在多种下游目标识别任务上(8 个基准目标识别任务,包括小样本目标识别、稳健目标识别、目标检测等)的性能达到国际先进或者领先水平(如下图 3 所示)。在细粒度车辆 MSTAR 数据集中,它的目标分类性能优于现有的 SSL 方法(BIDFC),提升 4.5%。
此外,它在扩展操作条件 EOCs(擦地角 EOCs-Depression、目标配置 EOCs-Config 和目标版本 EOCs-Version)下表现良好。SARATR-X 在各种类别(多类的 SARDet-100K 和 OGSOD、船舶 SSDD 和飞机 SAR-AIRcraft)的目标检测下也具有竞争力,平均提升约 4%。并且所提方法具有良好的数据量和参数量可扩展性,具有进一步提升潜力。
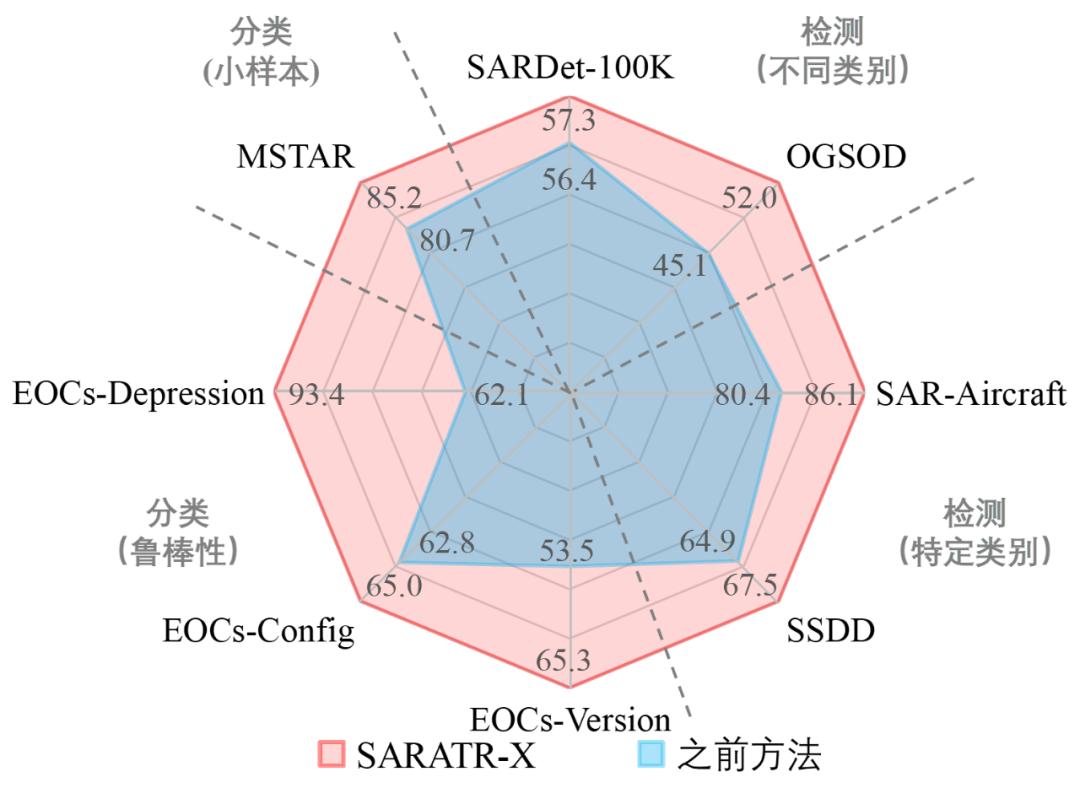
图 3. SARATR-X 1.0 分类和检测的结果。
检测结果分析,检测可视化如下图 4 所示,虚警和漏检在 SAR 图像中很常见,特别是在相似的目标重叠和复杂的场景。虽然所提方法通过学习图像中的上下文信息,有效地提高了检测效果,但复杂场景和低质量图像的目标检测仍然非常困难。
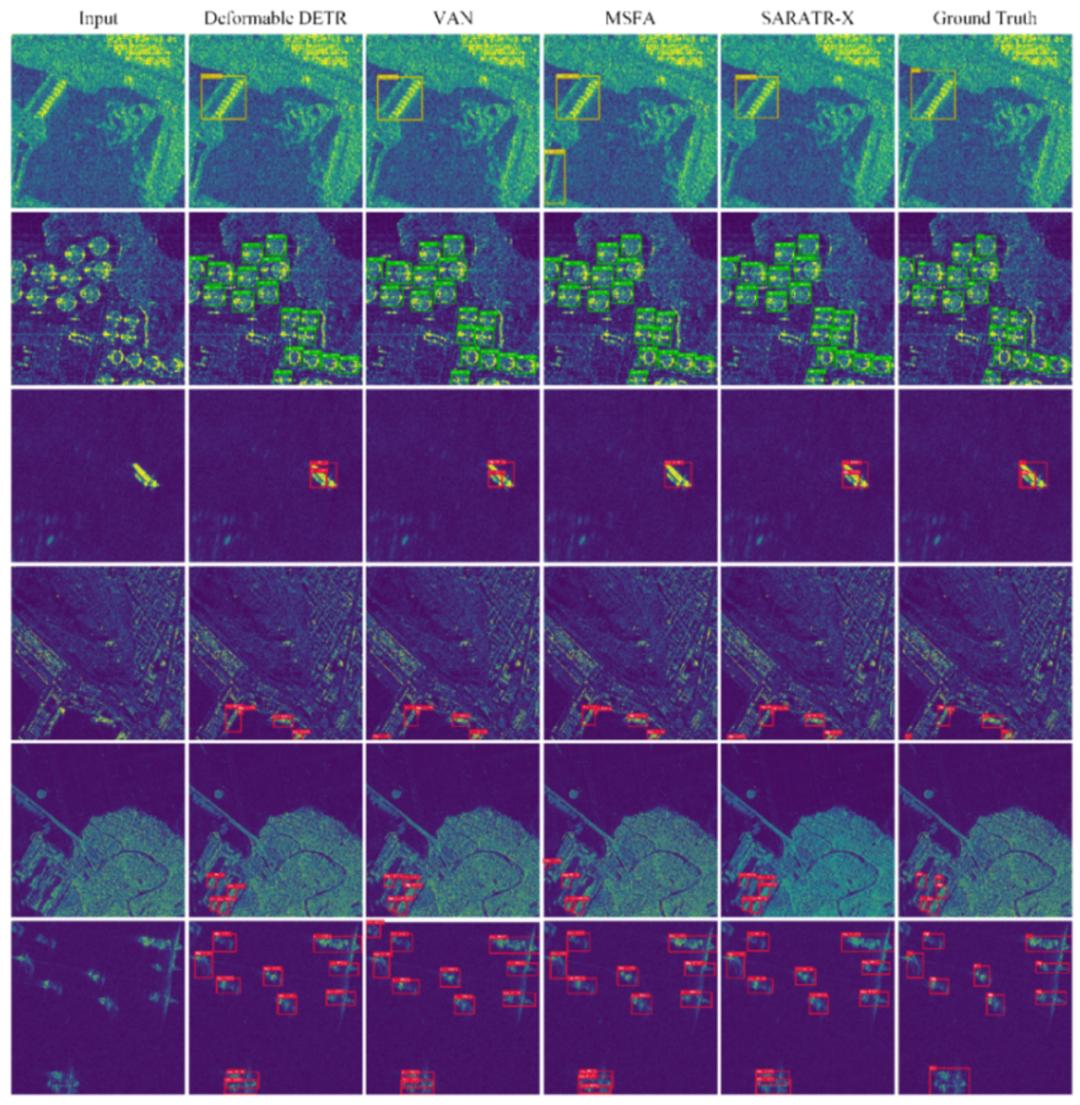
图 4. 在 SARDet-100K 上进行检测的可视化。
注意力多样性分析,对于不同模型的注意力范围进行可视化分析,如图 5 所示,通过模型架构(图 a v.s. 图 b),初始化权值(图 a v.s. 图 c)和 SSL (图 d v.s. 图 e)改进以确保 SAR 目标识别的注意范围不同,包括 HiViT 架构、ImageNet 权重和 SAR 目标特征。
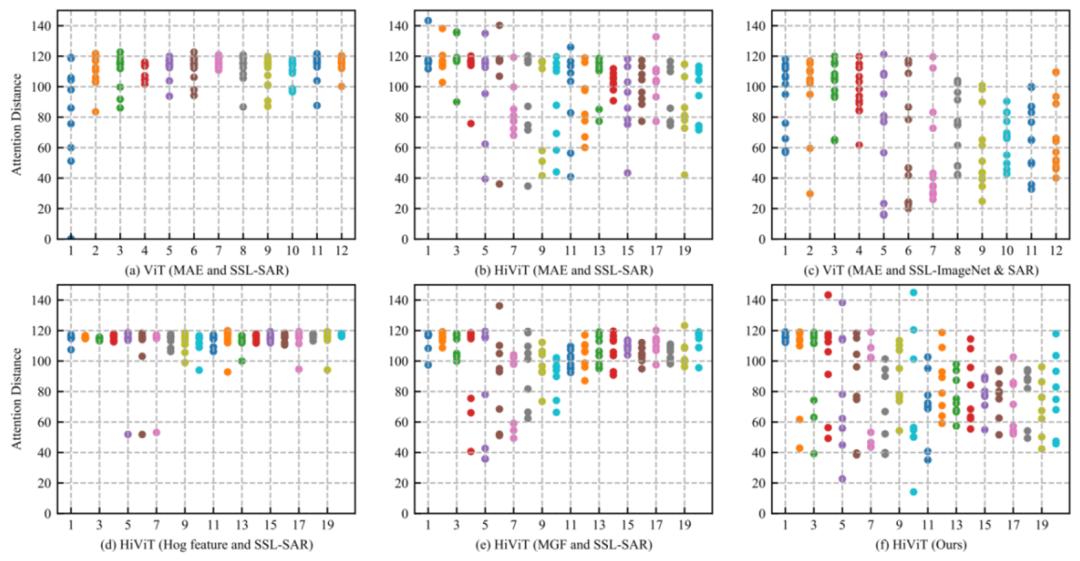
图 5. 不同注意头的平均注意距离(x 轴为注意头层数,点颜色代表不同的层,以便更好地可视化),注意距离(Attention Distance)代表了一个接受域的范围。
可扩展性,尽管掩码图像建模可以有效地随数据资源和模型参数扩展性能,但在处理噪声数据(如 SAR)时,所提方法是否可以确保其可扩展性?图 6 从三个角度展示了实验的结果:数据集大小、模型参数量和训练轮数。尽管预训练集包含 18 万个图像,比 ImageNet-1K 小,但在图 6(a)和(b)中,随着数据和参数量的增加,下游任务性能呈现显著上升曲线。这一结果表明,通过提取高质量的特征作为引导信号,基础模型可以充分发挥其在 SAR 目标识别中的潜力。但由于数据量限制,模型在扩展训练轮数时倾向于过拟合。此外,SAR 图像噪声和低分辨率进一步加剧了过拟合。
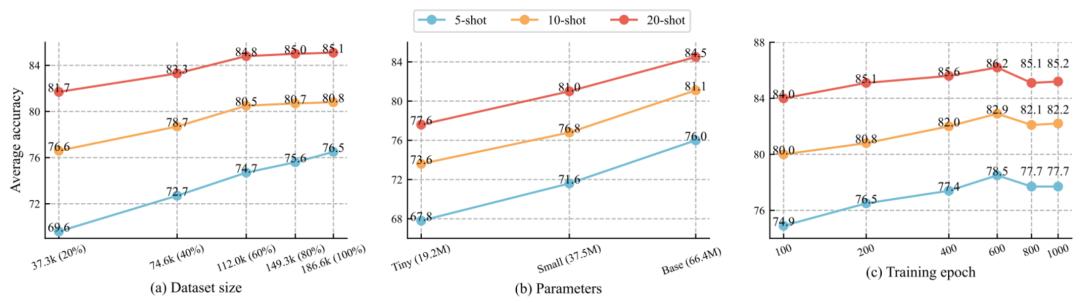
图 6. SARATR-X 在数据集大小、模型参数量和训练轮数方面的可扩展性。虽然方法受益于这三个方面,但需要注意的是,由于数据集的大小,过大的训练轮数经常会导致过拟合。
更多图表分析可见原文。
论文传送门
SARATR-X
题目:SARATR-X: Towards Building A Foundation Model for SAR Target Recognition
期刊:IEEE Transactions on Image Processing
论文:https://arxiv.org/abs/2405.09365
代码:https://github.com/waterdisappear/SARATR-X
年份:2025
单位:国防科技大学、上海人工智能实验室
作者:李玮杰、杨威、侯跃南、刘丽、刘永祥、黎湘
SAR-JEPA
题目:Predicting gradient is better: Exploring self-supervised learning for SAR ATR with a joint-embedding predictive architecture
期刊:ISPRS Journal of Photogrammetry and Remote Sensing
论文:https://www.sciencedirect.com/science/article/pii/S0924271624003514
代码:https://github.com/waterdisappear/SAR-JEPA
年份:2024
单位:国防科技大学、上海人工智能实验室、南开大学
作者:李玮杰、杨威、刘天鹏、侯跃南、李宇轩、刘振、刘永祥、刘丽


