

又爆大瓜!FrontierMath的o3惊人表现,竟是因OpenAI资助了Epoch AI而提前获得大部分试题访问权。OpenAI模型的性能究竟几分是真,几分炒作,愈来愈变得扑朔迷离。
不久前,OpenAI在「圣诞12连更」中发布的最强推理模型「o3」,毫无疑问地惊艳了所有人。
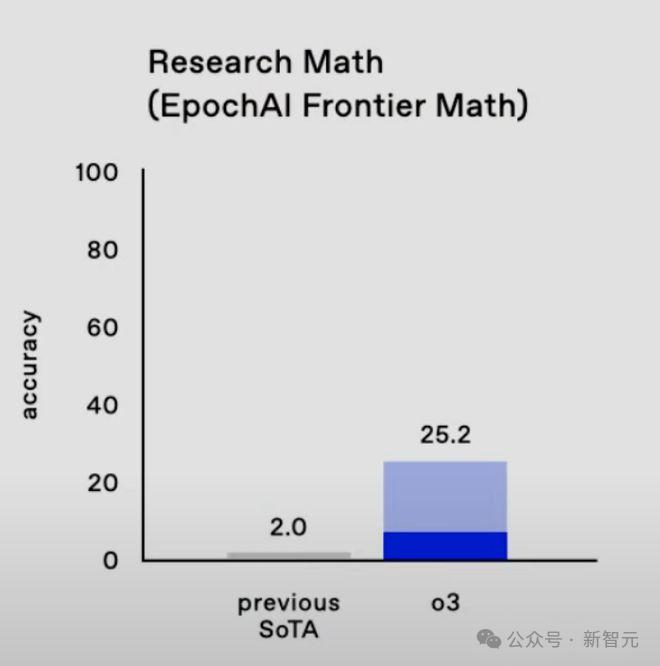
尤其是对于新近发布的数学基准FrontierMath,其准确率相比o1直接翻了12倍。
要知道FrontierMath可是Epoch AI联合六十余位全世界的数学家,其中包括教授、IMO命题人、菲尔兹奖获得者,共同推出的。
其包括数百个原创的、格外具有挑战性的数学问题,每个问题就算是专业数学家,也得需要数小时或数天的时间才能解决。

正因如此的高难度,o3这种对于FrontierMath惊人的突破才让大家都对其推理能力而感到不同凡响。
但是,近日曝出一则消息,o3之所以能在短时间之内就相比于o1提升12倍的准确率,是因为OpenAI资助了FrontierMath,并且可以访问大部分数据集。
但那些为评测集创建问题和解答的数学家们却完全被蒙在鼓里,根本不知道OpenAI是项目资助方并将获得数据访问权。

简单来说就是:
- 我们无从得知OpenAI是否用这个评测集训练了o3,因此他们宣称的结果可信度值得质疑
- 数学家们被有意隐瞒了真相,而大多数人甚至从未怀疑过会有一家AI公司在背后提供资金支持
对此,Epoch AI解释称:「我们承认OpenAI确实可以访问大部分FrontierMath的问题和解决方案,但有一个OpenAI未见过的保留集使我们能够独立验证模型能力。我们有口头协议这些材料不会用于模型训练。 」
但是这所谓与OpenAI达成的「口头协议」——呵,现在还有谁会相信OpenAI的承诺?

根据网上的各种报道,FrontierMath中的难题本应都是未公开的,目的就是防止AI公司利用这些数据训练模型。
然而现在看来,「AI公司根本接触不到这个数据集」这一点,实际上却是Epoch AI和OpenAI刻意制造出的假象。
但考虑到OpenAI前科累累的欺骗和误导行为——从蒙骗自家董事会,到强迫前员工签署秘密的不诽谤协议,应有尽有。
所以这次的事件,多少有种「意料之外,情理之中」的意味了。
Epoch AI首席数学家回应
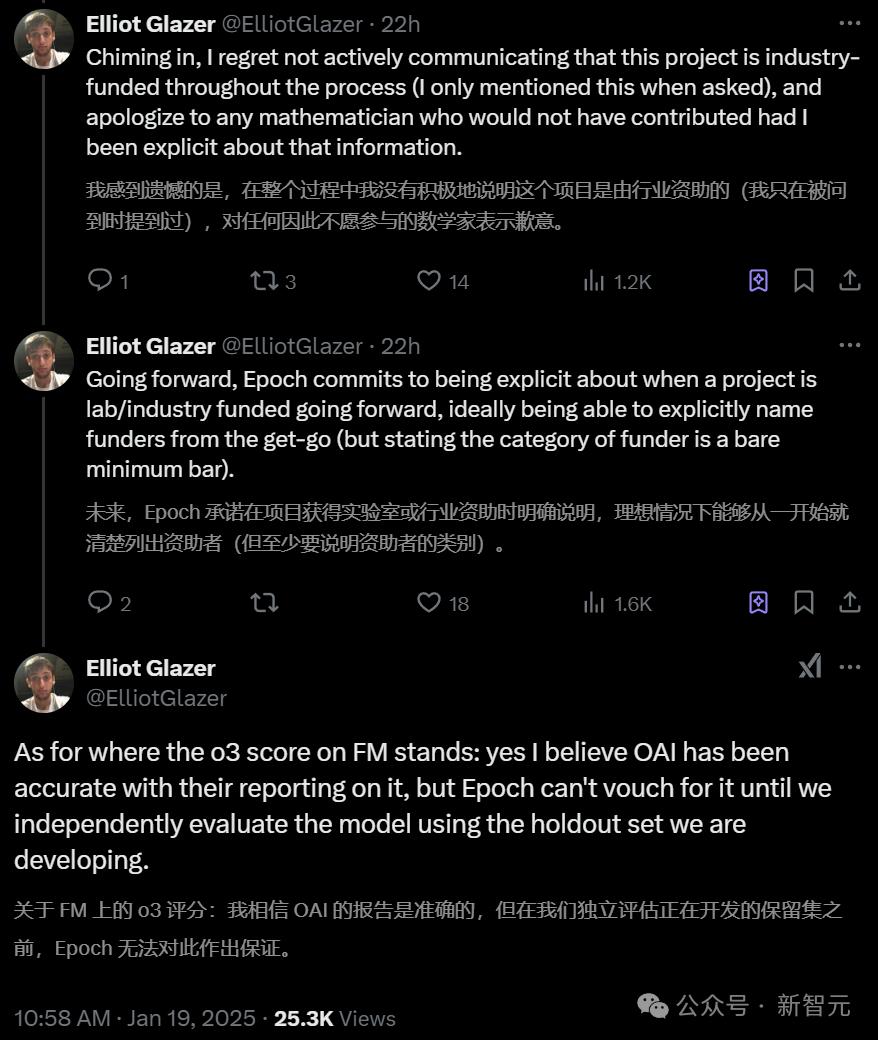
消息曝出后,Epoch AI首席数学家Elliot Glazer对此进行了回应。
他首先是承认了自己的错误,并对因为没有被告知真相而自主做出贡献的数学家致以歉意。
而对于o3那惊人的25.2%的准确率,他只是个人层面上表示相信,却没有一个真实可靠、有理有据的保证。
Epoch AI联创Tamay Besiroglu也正式发布了博客作为回应。
对于此次事件,Tamay给出的解释是:「我们的合同明确禁止披露资金来源信息以及OpenAI可以访问大部分(但不是全部)数据集的事实。」
现在回想起来,我们应该更积极地争取向评测集贡献者及时公开相关信息的权利。我们对此承担责任,并承诺未来会做得更好。
虽然我们确实向部分数学家告知了来自lab的资金支持,但这种沟通并不系统,也没有具体说明合作方。
这种不一致的沟通方式是我们的疏忽。我们应该一开始就坚持争取公开合作关系的权利,尤其是对那些创建问题的数学家们。
仅在o3发布前后才获得披露OpenAI参与的许可是远远不够的。参与项目的数学家们有权知道谁可能会接触到他们的工作。
尽管我们受到合同条款的限制,但我们应该将对贡献者的透明度作为与OpenAI合作的基本前提。
同时,对于FrontierMath他仍然声称:「OpenAI完全支持我们维护独立的未见测试集的决定——这是防止过拟合和确保准确评估进展的重要保障。」
在交流中,OpenAI的员工将FrontierMath称为「严格保留」的评估集,这种公开表述与我们的理解一致。
而且,我想强调的是,拥有真正未被训练数据污染的测试集对各个lab都很重要。
从项目伊始,FrontierMath就被设计和定位为一个评估工具,我们相信当前的安排完全符合这一初衷。
对于未来的合作,我们将致力于提高透明度,确保贡献者能在项目初期就清楚了解资金来源、数据访问权限和使用目的等信息。

总结来看,Epoch AI的确意识到了这次事件的严重性,但是很多回应依然停留在「公关套词」层面,并且全程都在甩锅称自己不说是因为「合同」的限制。

已有端倪,激起热议
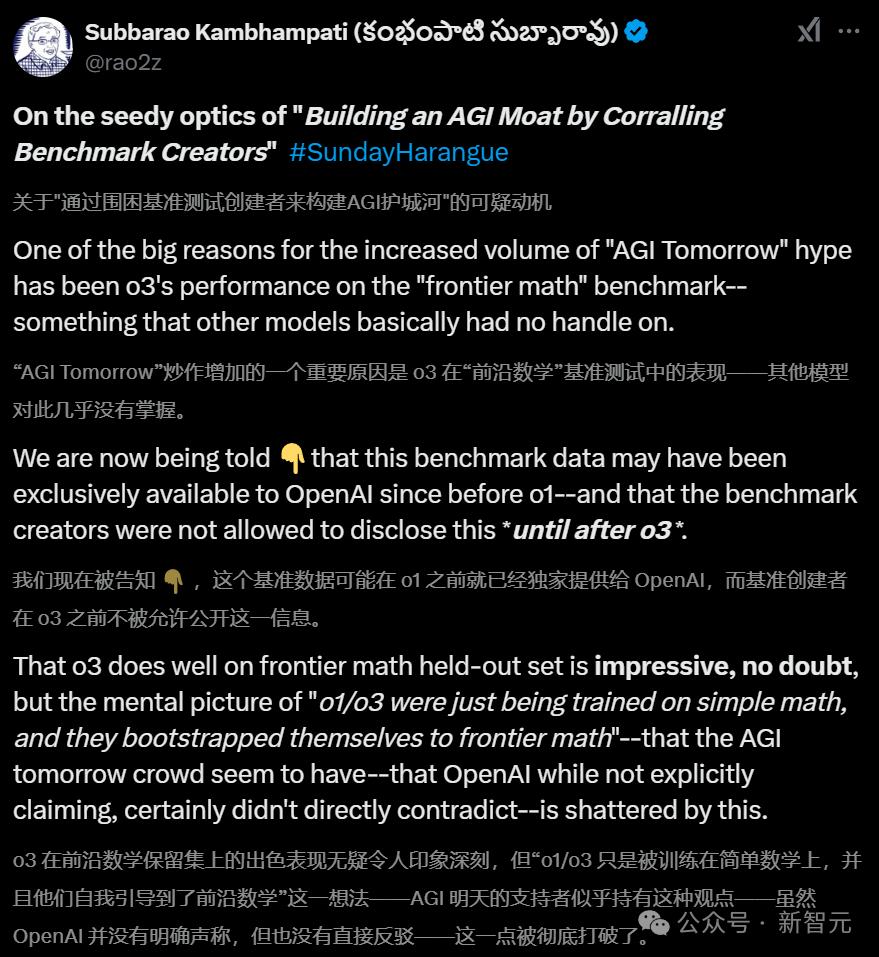
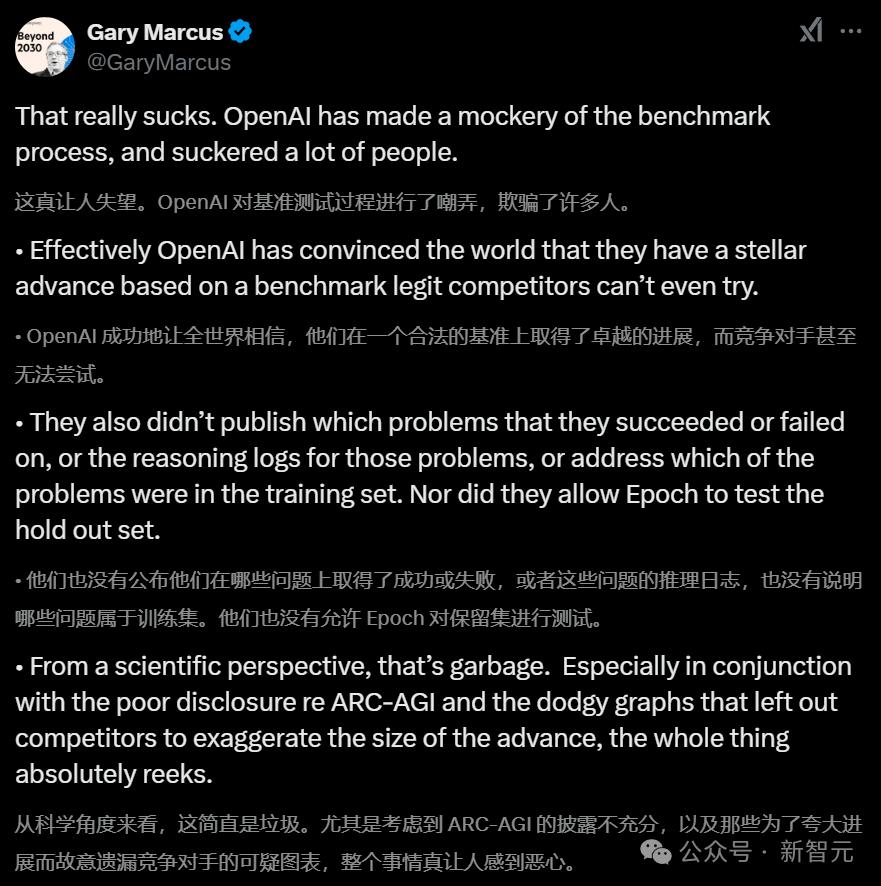
一石激起千层浪,纽约大学教授Gary Marcus,亚利桑那州立大学计算机教授Subbarao Kambhampati等大佬,纷纷发文对OpenAI这一的行为表示谴责。

其实,在去年12月刚发布时,便有参与o3-mini早期测试的研究人员发现了这一端倪。
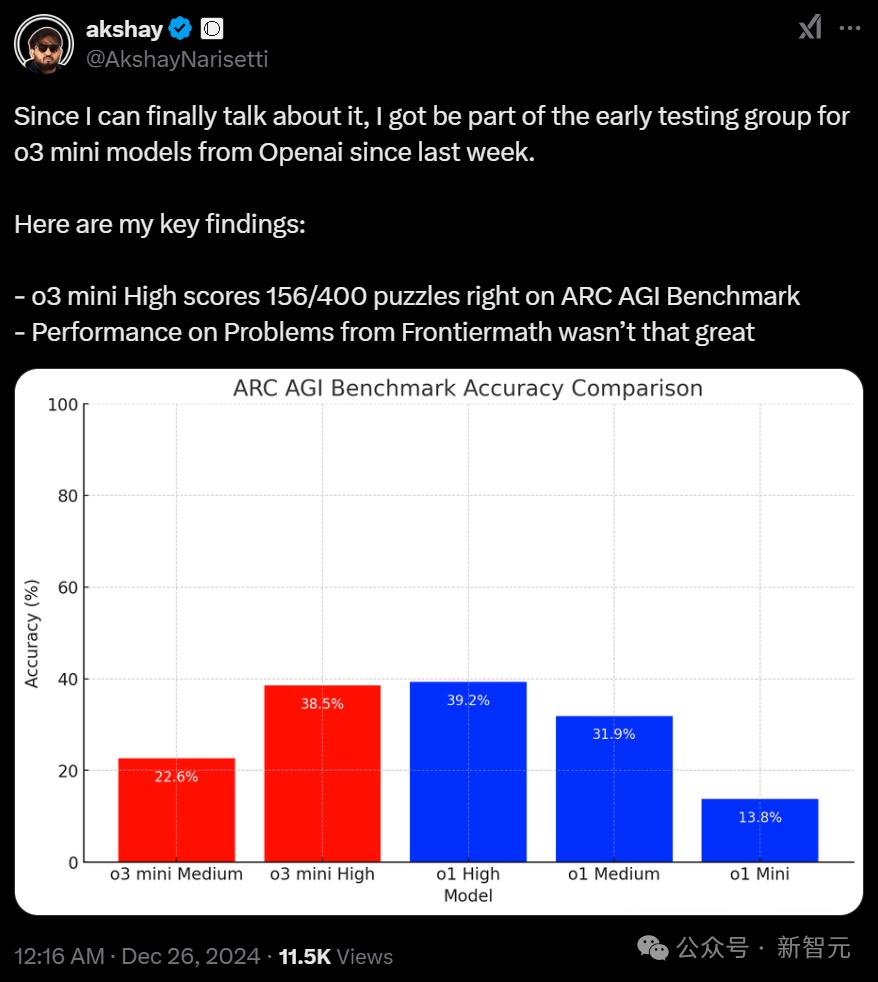
比如Open Vision Engineering的创始人Akshay Narisetti在推上po出的发现,就从侧面印证了这次的爆料:
- o3-mini在ARC-AGI中的正确率为156/400
- o3-mini在Frontiermath上的表现并不理想
根据实测结果,模型擅长解决特定类型的问题,但泛化能力还未完全成熟。在结构化任务上表现优异,但在需要多维度推理能力的问题上仍有明显短板。
对此,谷歌DeepMind的研究员「Ted Xiao」分析认为,这种影响可以有两个极端的解释:
1. 糟糕,OpenAI正在操纵benchmark,还把测试题目泄漏进训练数据里了!2. OpenAI只是用FrontierMath的私有题库来指导新训练数据的整体设计方向和目标,以及设计推理路径。
当然了,也有没那么极端的。比如,稍微改改题目内容创建新的训练数据,这样从技术角度来说,确实没有直接用测试数据中的token来训练。

如今,SOTA模型之间的竞争已经白热化。如果使用这种投机取巧的方式,模型在实际应用场景中就会原形毕露(缺乏泛化能力)。
这种冒险顶尖AI实验室可承担不起,因此于理来说,OpenAI更可能采用第二种方式。
但即便如此,这一行为依然让o1和o3在FrontierMath上,表现得比在其他未经优化的复杂推理领域中更亮眼。
不过,这种差距应该不会像某些在MMLU上采用第一种手段的「小语言模型」那样——评测分数和实际能力简直是天壤之别。
对于那些坚信OpenAI用了第一种方法、偷偷把测试数据混进去的人,我建议:不妨等等看o3在实际应用场景和其他评测中,跟下一代重点强化推理能力的顶尖模型相比,表现如何。
到时就知道,o3是不是只在FrontierMath上特别强,在其他地方就不行了。
参考资料:
https://x.com/Mihonarium/status/1880944026603376865
https://x.com/xiao_ted/status/1881075585843069258
https://x.com/ElliotGlazer/status/1880812021966602665


