

一觉醒来,突然发现 AI 的智商比肩爱因斯坦了。
根据外网疯传的一张图表,OpenAI 新模型 o3 在 Codeforces 上的评分为 2727,转换成人类智商的分数也就相当于 157,妥妥万里挑一。
并且,更夸张的是,从 GPT-4o 到 o3,AI 的智商仅用时 7 个月就飙涨了 42 分。

包括前不久尤为备受吹捧的是,OpenAI 的 o1 模型在门萨智商测试中得分更是高达 133,超过了大多数人类的智商水平。
然而,先别急着感慨人类在 AI 面前的一败涂地,不妨先停下来思考一个更为根本的问题,那就是用专门衡量人类智商的尺子来丈量 AI,是否真的恰当?

聪明的 AI,也会犯最基础的错误
任何有过 AI 使用经验的用户都能清晰地得出一个结论,对 AI 进行人类智商测试虽说有一定意义,但也存在严重的局限性。
这种局限首先源于测试本身的设计初衷。
传统智商测试是一套专门针对人类认知能力的评估体系,它基于人类特有的思维模式,涵盖了逻辑推理、空间认知和语言理解等多个维度。
显然,用这样一套「人类标准」去评判 AI,本身就存在方法论上的偏差。

深入观察人类大脑和 AI 的差异,这种偏差更为明显。
人类的大脑拥有约 860 亿个神经元,但研究表明,突触连接的数量和复杂度可能比神经元数量更为重要,其中人类大脑有大约 100 万亿个突触连接。
相比之下,2023 年 Nature 期刊上的研究显示,即便是参数量达到 1.76 万亿的 GPT-4,其神经网络的连接模式也远不及人类大脑的复杂程度。
从认知过程的流程来看,人类是按照「感知输入→注意过滤→工作记忆→长期记忆存储→知识整合」的路径进行思考。
而 AI 系统则遵循「数据输入→特征提取→模式匹配→概率计算→输出决策」的路径,形似而神异。
因此,尽管当下的 AI 模型在某些方面确实模仿了人类的认知功能,但本质上仍然只是一个基于特定算法的概率机器,其所有输出都源于对输入数据的程序化处理。

前不久,苹果公司发表的研究论文就指出,他们在语言模型中找不到任何真正的形式推理能力,这些模型的行为更像是在进行复杂的模式匹配。
而且这种匹配机制极其脆弱,仅仅改变一个名称就可能导致结果产生约 10% 的偏差。
用爬树能力评判鱼类,它终其一生都会觉得自己是个笨蛋。同理,用人类标准衡量 AI 同样可能产生误导性判断。
以 GPT-4o 为例,看似智商远超人类平均水平 100 分的光环背后,是连 9.8 和 9.11 都分不清大小的尴尬现实,而且还经常产生 AI 幻觉。
包括 OpenAI 在自己的研究中也坦承,GPT-4 在处理简单的数值比较时仍会犯基础性错误,AI 所谓的「智商」可能更接近于单纯的计算能力,而非真正意义上的智能。
这就不难理解为什么我们会看到一些暴论的出现。
比如 Deepmind CEO 和 Yann Lecun 声称当前 AI 的实际智商甚至不如猫,这话虽然听起来刺耳,但话糙理不糙。

实际上,人类一直在为量化 AI 的聪明程度寻找合适的评估体系,既要容易度量,又要全面客观。
其中最广为人知的当属图灵测试。如果一台机器能在与人类的交流中完全不被识破,就可以被认定为具有智能,但图灵测试的问题也很明显。 它过分关注语言交流能力,忽视了智能的其他重要维度。
与此同时,测试结果严重依赖于评估者的个人偏见和判断能力,一个机器即便通过了图灵测试,也不能说明它真正具备了理解能力和意识,可能仅仅是在表层模仿人类行为。

就连素有「智商权威」之称的门萨测试,也因其针对特定年龄组人类的标准化特点,而无法为 AI 提供一个「真实可信」的智商分数。
那么,如何才能向公众直观地展示 AI 的进步?
答案或许在于将评估重心转向 AI 解决实际问题的能力。相比智商测试,针对具体应用场景设计的专业评估标准(基准测试)可能更有意义。
从「理解」到「背题」,为什么连测试 AI 都变得如此困难?
从不同维度出考卷,基准测试可谓五花八门。
比如说,常见的 GSM8K 考察小学数学,MATH 也考数学,但更偏竞赛,包括代数、几何和微积分等,HumanEval 则考 Python 编程。
除了数理化,AI 也做「阅读理解」,DROP 让模型通过阅读段落,并结合其中的信息进行复杂推理,相比之下,HellaSwag 侧重常识推理,和生活场景结合。

然而,基准测试普遍存在一个问题。 如果测试数据集通常是公开的,一些模型可能在训练过程中已经提前「预习」过这些题目。
这就好比学生做完整套模拟题,甚至真题后再参加考试一样,最终的高分可能并不能真实反映其实际能力。
在这种情况下,AI 的表现可能仅仅是简单的模式识别和答案匹配,而非真正的理解和问题解决。成绩单看似优秀,却失去参考价值。
并且,从单纯比拼分数,到暗地里「刷榜」,AI 也会染上人类的焦虑。比如说号称最强开源大模型的 Reflection 70B 就曾被指出造假,让不少大模型榜单的可信度一落千丈。
而即便没有恶性刷榜,随着 AI 能力的进步,基准测试结果也往往会走向「饱和」。

正如 Deepmind CEO Demis Hassabis 所提出,AI 领域需要更好的基准测试。目前有一些众所周知的学术性基准测试,但它们现在有点趋于饱和,无法真正区分不同顶级模型之间的细微差别。
举例来说,GPT-3.5 在 MMLU 上的测试结果是 70.0,GPT-4 是 86.4,OpenAI o1 则是 92.3 分,表面上看,似乎 AI 进步速度在放缓,但实际上反映的是这个测试已经被 AI 攻克,不再能有效衡量模型间的实力差距。
如同一场永无止境的猫鼠游戏,当 AI 学会应对一种考核,业界就不得不寻找新的评估方式。在比较常规的两种做法中,一种是用户直接投票的盲测,而另一种则是不断引入新的基准测试。
前者我们很熟悉了,Chatbot Arena 平台是一个基于人类偏好评估模型和聊天机器人的大模型竞技场。不需要提供绝对的分数,用户只需比较两个匿名模型并投票选出更好的一个。

后者,最近备受关注的就是 OpenAI 引入的 ARC-AGI 测试。
由法国计算机科学家 François Chollet 设计, ARC-AGI 专门用来评估 AI 的抽象推理能力和在未知任务上的学习效率,被广泛认为是衡量 AGI 能力的一个重要标准。
对人类来说容易,但对 AI 来说非常困难。ARC-AGI 包含一系列抽象视觉推理任务,每个任务提供几个输入和对应的输出网格,受测者需要根据这些范例推断出规则,并产生正确的网格输出。
ARC-AGI 的每个任务都需要不同的技能,且刻意避免重复,完全杜绝了模型靠「死记硬背」取巧的可能,真正测试模型实时学习和应用新技能的能力。
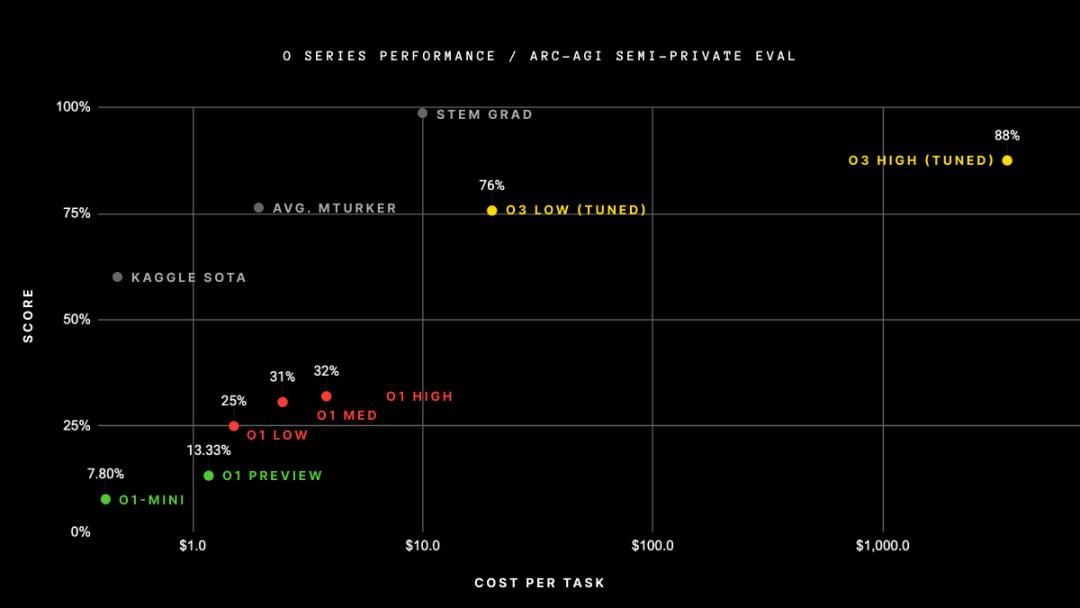
在标准计算条件下,o3 在 ARC-AGI 的得分为 75.7%,而在高计算模式下,得分高达 87.5%,而 85% 的成绩则接近人类正常水平。
不过,即便 OpenAI o3 交出了一份优秀的成绩单,但也没法说明 o3 已经实现了 AGI。就连 François Chollet 也在 X 平台发文强调,仍有许多对人类来说轻而易举的 ARC-AGI-1 任务,o3 模型却无法解决。
我们有初步迹象表明,ARC-AGI-2 任务对这个模型来说仍然极具挑战性。 这说明,创建一些对人类简单、有趣且不涉及专业知识,但对 AI 来说难以完成的评估标准仍然是可能的。 当我们无法创建这样的评估标准时,就真正拥有了通用人工智能(AGI)。
简言之,与其执着于让 AI 在人类设计的各种测试中取得高分,不如思考如何让 AI 更好地服务于人类社会的实际需求,这或许才是评估 AI 进展最有意义的维度。


